29. Distribunomicon¶
29.1. 暗闇に独り¶
やあ!どうぞ座って下さい。あなたを待っていました。 初めてErlangについて聞いたとき、あなたは2、3つの要素に関して魅力に感じたのではないでしょうか。 Erlangは関数型言語で、並列性に関して素晴らしいセマンティクスがあって、分散をサポートしています。 最初の2つに関しては、思いもよらないほど多くの時間を割いて、いろいろな物を見てきました。そして、最後の砦である、分散について語る時間となりました。
ここに来るまで、かなり長い時間がかかってしまいました。これは、まずローカルでちゃんと動くものを作れないと、分散させても全然役に立たない、という理由があったからです。 必要なタスクをやり遂げ、長い道のりを経て、ようやくここまでやってきました。 Erlangにある他の機能と同様に、Erlangの分散に関する層は、フォルトトレランスを提供するために追加されました。 1台のマシンで稼働しているソフトウェアは、常にそのマシンが死んで、アプリケーションがオフラインになる危険にさらされています。 多くのマシンで稼働しているソフトウェアは、アプリケーションが正しく構築された時かつその時に限って、ハードウェア障害に対応しやすくなります。 あなたのアプリケーションがたくさんのサーバで稼働していても、その内の1台が落ちそうになったときに、それに対応できなければ、フォルトトレランスの利点をまったく得ることはできません。

分散プログラミングは、モンスターがそこら中にいる中、暗闇に独り残されるようなものです。 その状況は恐ろしく、何をしていいか分からず、何がやってくるかわかりません。 悪いお知らせがあります。分散Erlangでもあなたを暗闇に独り置き去りにして、恐ろしいモンスターと闘う事になります。 良いお知らせもあります。備えが多少の小銭とモンスターを殺すセンスが乏しい状態で独りにさせられるのではなく、Erlangはあなたに懐中電灯、ナタ、かなりかっこいい口ひげを授けてくれ、自信を持たせてくれます。(女性の読者もこれらがあれば自信がつくでしょう)
これはErlangがどう実装されているかということだけによらず、多かれ少なかれ分散ソフトウェアの性質によるところがあります。 Erlangは分散に関して書くべき基本的な要素がほとんどありません。お互いにやり取りする多くのノード(仮想マシン)を持ち、やり取りするデータのシリアライズとデシリアライズを行い、マルチプロセスの概念を多くのノードで行うように拡張させ、ネットワークの失敗を監視する方法を実装すればよいのです。 しかし、これらは、例えば「何かがクラッシュした時に何が起きるか」というようなソフトウェア固有の問題は解決してくれません。
これは先にOTPの部分で触れたような「道具であり、解決方法ではない」という一般的なアプローチです。OTPを使えば、完璧なソフトウェアやアプリケーションを作ることは難しいでしょうが、システムを作る上で多くの概念を学ぶことができるでしょう。 システムの一部が稼働する、または、落ちるときを教えてくれたり、ネットワーク越しに多くの作業を行ったりできる道具を手にすることはできますが、あなたに固有の問題を解決してくれる銀の弾丸ではあり得ないでしょう。
この道具を使って、どのように動作させることができるかを見てみましょう。
29.2. これは私のほうきの柄¶
暗闇の中でこれらのモンスターに立ち向かうために、とても役に立つものを与えてきました。かなり完全なネットワーク透明性のことです。
稼働していて、他の仮想マシンに接続することが出来る状態にあるErlang仮想マシンのインスタンスはノードと呼ばれます。 いくつかの言語、あるいはコミュニティではサーバのことをノードとしますが、Erlangでは各VMがノードです。 1台のコンピュータ上で50ノード走らせることも、50台のコンピュータ上で50ノード走らせることも、どちらも可能です。
ノードを起動したとき、ノードに名前を付けあと、ノードは EPMD ( Erlang Port Mapper Daemon )と呼ばれるアプリケーションに接続します。これはErlangクラスタの一部として各コンピュータ上で稼働しています。 EPMDはノードが自分自身を登録し、他のノードに接続し、もし名前がクラッシュした場合には警告する、といったことをするための名前サーバとして振る舞います。
ノードが起動したら、ノードは他のノードに接続できるようになります。 接続するとなったら、2つのノードは自動的にお互いを監視し始め、接続が切れたかあるいはノードが消えたかを知ることができます。 さらに重要なのは、新しいノードが、既にお互いに接続しあっているノード群の一部となっているノードに接続した場合には、ノード群全体に接続した状態になります。
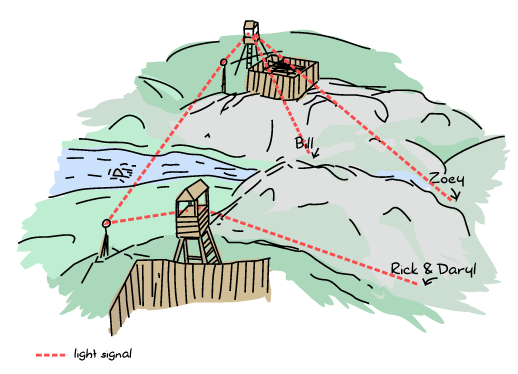
ゾンビが暴動を起こしたときの大量の生存者という図を使って、Erlangのノードがどのようにお互いの接続を行なっているかを表現してみましょう。 ここに、Zoey、Bill、Rick、Darylの4人がいます。 ZoeyとBillはお互いのことを知っていて、トランシーバーを使って同じ周波数でやり取りをしています。 RickとDarylはそれぞれ独立しています:
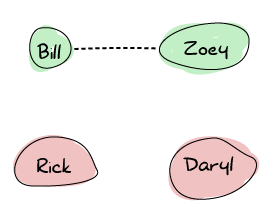
たとえばいまRickとDarylは生存者キャンプへ行く途中だとしましょう。 いまお互いにトランシーバーの周波数を共有して、お互いの状況を交信しあって、再びバラバラになってしまわないようにしています。
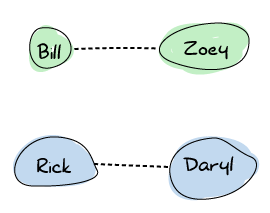
あるとき、RickはBillに会います。 会えたことに大喜びで、お互いに周波数を共有することに決めました。 この時点から、接続が広がって、最終的にグラフはこのようになります:
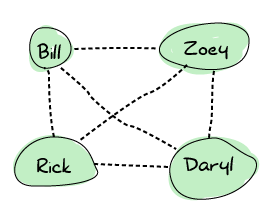
つまり、この状態はすべての生存者がお互いに直接連絡を取ることができるということです。 これは、一人でも生存者が死んだ場合に、だれも一人きりにならないので、役に立ちます。 Erlangノードはこのやり方で設定をします。全員が全員に接続します。
Don’t Drink Too Much Kool-Aid:
このような方法は、フォルトトレランスに関しては良いのですが、スケールできる規模に関しては欠点もあります。 何百ものノードをErlangクラスタに持たせることは、単純に接続数と交信頻度を考えた場合に難しいことがあります。 事実、接続するノード1つに付き1つのポートが必要になります。
Erlangでこのような厳しい設定をしようと考えている場合には、この章の続きを読んで、このような設定をしたいときに、問題を回避するためにどのような事ができるかを読んで下さい。回避が可能な場合、の話ですが。
ノードがお互いに接続しても、ノードは完全に独立しています。つまり、ノードは所有しているプロセスレジストリやETSテーブルを(テーブル名とともに)保持し、読み込んだモジュールもお互いに独立しています。 接続しているノードがクラッシュしても、接続されているノードは落ちません。
それから接続しているノードはメッセージ交換を始めます。 Erlangの分散モデルはローカルプロセスがリモートプロセスに対して連絡し、通常のメッセージを送れるように設計されました。 このようなことが、何も共有されず、すべてのプロセスレジストリが一意な状態でどうしてできるのでしょうか。 これについては、後ほど分散の仕様について触れるときに見るように、特定のノード上の登録済みプロセスへ接続する方法があります。 こうしてようやく最初のメッセージが送れます。
Erlangメッセージは、透過性が高い方法でシリアライズとデシリアライズされます。 Pidを含む、すべてのデータ構造はリモートでもローカルでも同様に動作します。 つまり、ネットワーク越しにPidを送ることもできますし、それらに対してやり取りすることもできますし、メッセージを送ることもできます。 さらに素晴らしいのは、Pidにアクセスできるということは、リンクやモニタをネットワーク越しに設定できるということです。
もしErlangがすべてを透過的にしようとしているのであれば、なぜナタや懐中電灯や口ひげだけを与えると言ったんでしょう。
29.3. 分散コンピューティングに関する誤解¶
ナタが特定のモンスターだけを殺すようにできているように、Erlangのツールはいくつかの分散コンピューティングだけを扱うために出来ています。 Erlangが提供するツールを理解するためには、分散の世界にはどのような展望があるのか、そしてフォルトトレランスを提供するためにErlangが何を想定しているのか、ということをまず考えるのが良いでしょう。
過去数十年間、何人かの非常に聡明な方々が時間を掛けて、分散コンピューティングを失敗させる原因をカテゴリ分けしてきました。 彼らは後に災いとなってやってくる主な8つの仮定を導き出しました。その中のいくつかはErlangの設計者が様々な理由から導いたものです。
29.3.1. ネットワークは信頼性が高い¶
まず分散コンピューティングに関する最初の誤解は、アプリケーションはネットワーク越しに分散できるという想定です。 こんな事を改めていうのもおかしいですが、ネットワークがややこしい原因で落ちてしまうことは数えきれないほどあります。たとえば、電源の遮断、ハードウェア障害、あるいは誰かがケーブルを引っ掛けたり、他次元への竜巻がミッションクリティカルなコンポーネントを巻き込んでしまったり、headcrabが体内に侵入してきたり、銅線泥棒にあったり、などといった原因があります。
したがって、あなたが起こしうる最大の間違いは、リモートノードに接続できると勘違いすることです。 これはハードウェアを増強し冗長化して、いくつかが故障しても、アプリケーションが別のどこかで稼働し続けていられるようにします。 また、メッセージやリクエストを失っても耐えられるよう、応答不能になってもいいように準備します。 これは、特に、すでに稼働していない3rdパーティーサービスに依存していても、あなたのソフトウェアスタックを稼働し続けさせたい場合には有効です。
この問題は通常アプリケーション固有のものなので、Erlangにこの問題を扱うための特別な測定法などはあるわけではありません。 結局あなた以外の誰がある特定のコンポーネントがどれくらい大事かということを知ることが出来るでしょうか。 分散Erlangノードは他のノードが切断しようとしている(あるいは応答不能になっている)ことを検知できるので、あなたはまったくもって孤独だというわけではありません。 ノードを監視する特別な関数があり、リンクやモニターは切断をきっかけとして動作します。
このような特別な関数があるした上で、さらにこの問題に対してErlangが自分自身のために持っている最も優れた機構は非同期通信モードです。 メッセージを非同期に送信し、開発者に処理が正常に行われたときに返信をさせることで、Erlangはあらゆるメッセージパッシングが直感的に異常処理を行えるようにしています。 あなたが話かけようとしているプロセスが、ネットワーク障害によって消えようとしているノード上で動作している場合、それはローカルでのクラッシュと同じくらい自然なものとして扱います。 これがErlangがスケールすると言われている理由の1つです。(パフォーマンスの面でもスケールしますが、設計においてもスケールするのです)
Don’t Drink Too Much Kool-Aid:
ノード間でリンクやモニターを張るのは危険です。 ネットワーク障害が起きたときに、リモートのリンクやモニターがすべて一度にトリガーとなります。 これは様々なプロセスに対して何千ものシグナルやメッセージを生成することになり、システムに重く、予想しない負荷をかけることになります。
信頼性の低いネットワークに対して準備をするということは、急な傷害に対して準備し、システムの一部が突然消えてしまっても確実に動作不能にならないようにする、ということでもあります。
29.3.2. 遅延などない¶
一見したところ良い分散システムに思えるものの諸刃の点は、今行おうとしている関数呼び出しがリモートへの呼び出しである事実をしばしば隠してしまうことにあります。 ある関数呼び出しが本当に速く行われてほしいと期待していますが、ネットワーク越しではまったく状況は異なります。 いうなれば、ビッチェリアの店内でピザを注文する場合と、他の街からあなたの家まで宅配してもらう場合の違いと同じです。 通常の待ち時間というものはありますが、ある場合には時間がかかり過ぎてピザが冷めた状態で届けられることもあるでしょう。
本当に処理を速く行いたい場合には、ネットワーク通信では本当に小さなメッセージを送る場合でさえも遅くなるということを忘れてしまうと、処理コストの点で見て障害になりえます。 Erlangのモデルではその点はうまく処理しています。 ローカルアプリケーションを、独立したプロセス、非同期メッセージ、タイムアウトと常にプロセスが落ちる可能性を考慮しながら稼働させているため、アプリケーションを分散させるために必要な変更はほとんどありません。タイムアウト、リンク、モニター、非同期パターンは変わらず信頼性の高いものです。 こういった類の問題は最初から常につきまとうものなので、Erlangは暗黙の内に遅延がないとは想定しません。
しかし、あなたの設計や期待の中では、現実的に可能な速度よりも速く返信をするような想定をしてしまっているでしょう。 それに関しては注意深く続きを読んでいって下さい。
29.3.3. 帯域は無限大¶
ネットワーク転送は留まることを知らず速くなりつづけていて、ざっくりと言えば、1バイトあたりのネットワーク越しの転送コストはだんだんと小さくなっていますが、大量のデータを送信することは単純で簡単だと考えるのはリスクが高いです。
一般的に、アプリケーションをローカルで制作する場合では、Erlangではさほど問題は起きません。 秘訣は、新しい状態を持ち回していくのではなく、何が起きているかについてのメッセージを送る、ということだったのを思い出してください。 (プレーヤーXが持っているアイテムすべてを何度も持ち回すのではなく、「プレーヤーXがアイテムYを見つけた」というメッセージを送るのです)
もし、何らかの理由で、大きなメッセージを送る必要が出てきた場合は、非常に気をつけて下さい。 Erlangの分散と通信が多ノード間で動作している方法は特に大きなメッセージに対して影響を受けやすいのです。 2つのノードがお互い接続している場合、お互いの通信はすべて1つのTCP接続越しに行われるでしょう。 一般的に2つのプロセス間での(ネットワーク越しであっても)メッセージの順序を維持したいため、メッセージは接続越しに直列に送信されるでしょう。 これはつまり、もし1つ大きなメッセージがあれば、他のメッセージも使っているチャンネルをブロックする可能性があるということです。
さらに悪いことに、Erlangはノードが生きているかどうかをハートビートと呼ばれるものを送信することで確認しています。 ハートビートは、2つのノード間で定期的な間隔で送られる小さなメッセージで、基本的には「私はまだ生きてますよ、動き続けてますよ!」ということを言っています。 これは、ゾンビからの生還者が定期的にお互いに言葉を掛けあうようなものです。つまり「Bill、まだいるか?」と質問して、もしBillが返信しなければ、彼は死んだと分かり(電池切れです)、彼はこれ以上あなたの通信を受け取る事はないでしょう。 いずれにせよ、ハートビートは通常のメッセージと同じチャンネル越しに送信されるのです。
したがって、問題は、大きなメッセージがハートビートが戻ってくるのを抑えてしまうということです。 大きなメッセージがたくさん来すぎて、ハートビートを端に追いやる時間が長すぎると、ノードは結果的に他方のノードは応答不能になっていると判断して、切断するでしょう。 これはいけません。 どのような場合にも、このような事が起こらないような、良いErlangの設計をするための教訓としては、メッセージを小さく保つ、ということです。 これによって諸々改善されます。
29.3.4. ネットワークは安全¶
分散が出来たとして、すべてが安全で、あなたが受信するメッセージは信頼できる、と信じるのは非常に危険です。 単純に、誰かがメッセージを改変してあなたに送っている可能性がありますし、誰かがパケットを傍受して修正している(あるいは公にしてはいけないデータを覗いている)可能性や、最悪の場合、誰かがあなたのアプリケーションやそれが動作しているシステムを占領している可能性もあります。
分散Erlangの場合、悲しいことにこれらは起こりえるのです。 次に、Erlangのセキュリティモデルがどのようになっているかお見せします:
ここは意図的に空白にしてあります
そうです。これは、Erlangの分散機構がはじめはコンポーネントのフォルトトレランスと冗長性のために作られたからです。 Erlangの黎明期、まだ電話交換機や電信アプリケーションなどに使われていた頃に、Erlangはしばしば非常に稀な環境にデプロイされていました。たとえば非常に離れた場所にあって変な環境(エンジニアが湿った地面を避けるためにサーバを壁に設置しなければならなかったり、ハードウェアが適切な温度で稼働できるように木の中に加熱システムを設置しなけれならない)で動作しているサーバなどにデプロイされていました。 このような場合、主ハードウェアと同じ物理的配置でフェイルオーバー用のハードウェアを設置していました。 こういった状況が分散Erlangが動作すると想定されたところで、これがErlangの設計者が安全なネットワークを想定した理由です。
悲しいことに、これは現代のErlangアプリケーションはほとんど異なるデータセンター越しにクラスタ化されていないということです。 事実、このようなことは推奨されていません。 たいていの場合、システムはErlangノードでできていて、1箇所にまとまっている、小さな、城壁で囲まれたクラスタでできていて欲しいものでしょう。 より複雑なものは開発者が実装する必要があります。SSLに切り替えたり、独自に上位層通信レイヤを実装したり、セキュアチャンネル越しにトンネルしたり、ノード間の通信プロトコルを再実装したりする必要があります。 これらを行うための指針はERTSユーザガイド内の、 Erlangの分散のための代替的なキャリア にあります。 分散プロトコルに関する詳細は、 分散プロトコル にあります。 これらを使った場合でさえも、かなり気をつけなければなりません。なぜなら、誰かが分散ノードの1つへのアクセス権を取得して、やがて全ノードへのアクセス権を取得して、あらゆるコマンドを実行される可能性があるからです。
29.3.5. トポロジーは変わらない¶
多くのサーバ上で稼働するように作られた分散アプリケーションを初めて設計するとき、頭の中にある台数のサーバを思い浮かべて、ホスト名の一覧を考るのはよくあることです。 また特定のIPアドレスも想定しているかもしれません。 これは間違いです。 ハードウェアが死に、サーバ管理者がサーバをあちこちに動かし、新しいマシンが追加され、またいくつかは取り除かれます。 ネットワークのトポロジーは常に変化するのです。 もしアプリケーションが細かくハードコードされたトポロジーで動作しているのであれば、そのアプリケーションは容易には変更できないでしょう。
Erlangでは、この問題をを明示的に想定して準備する方法はありません。 しかしながら、アプリケーション内でゆっくりとトポロジーを変形させていくことは非常に簡単です。 Erlangノードはすべて名前とホスト名を持っていて、これらは絶えず変更可能です。 Erlangプロセスを扱うときは、プロセスがどのように命名されたかを考えなければならないだけでなく、クラスタ内のどこに位置しているかも考えなければいけません。 プロセス名とホスト名を両方共ハードコードしてしまった場合、次に障害が起きたときに困ったことになるでしょう。 しかし、心配しすぎる必要はありません。依然として特定のプロセスの配置を扱うことはできますが、あとで、ノード名と一般的なトポロジーを忘れさせてくれる面白いライブラリについて学んでいきます。
29.3.6. 管理者は一人きり¶
これは、どんなものであろうと、ある言語やあるライブラリの分散レイヤが準備のしようのない問題です。 ここでの誤解というのは、あなたのソフトウェアや、それを動かしているサーバが一人の管理者によって管理されるように設計されたとしても、常にそうとは限らないということです。 多くのノードが1つのコンピュータ上で動作するように決めた場合は、このような誤解がある心配を剃る必要はありません。 しかし、異なる場所にあるマシン上で動作するものや、あなたのコードに依存する外側のソフトウェアがある場合、この誤解について気をつける必要があります。
注意を払うべき事には、システムに起きた問題を診断するためのツールを提供することも含まれています。 Erlangは、VMを主導で操作できるときはデバッグがいくらか簡単です。たとえば、必要があればコードをその場で再読み込みすることすらできます。 しかしながら、あなたのターミナルにアクセス出来ない人や、ノードが稼働している端末の前に座っている人には、管理用に異なる道具が必要です。
またここでの誤解に関する他の側面は、サーバを再起動、データセンター間でのインスタンスの移動、ソフトウェアスタックの一部を更新する、というような作業が必ずしも、一人の人間や一組織だけに管理されているものではない、ということです。 非常に大きなソフトウェアプロジェクトでは、このようなことは非常によく起こりえますし、多くの異なるソフトウェア会社が、大きなシステムのいろいろな部分の責任を持っていることすらあります。
あなたのソフトウェアスタック向けの規約を書いている場合、そのユーザやパートナーが彼らのコードをどれくらいの速度で更新できるかに応じて、様々な版の規約を扱える必要があるでしょう。 規約にはバージョン管理についての情報も書いてあるでしょうし、必要があればトランザクションの途中で規約を変更可能でしょう。 この誤解に関して、あなたも多くのまずい事例を思いつくことだと思います。
29.3.7. 転送コストはゼロ¶
これは両面性の誤解です。 1つ目は時間に関するデータ転送コストに関係したもので、もう1つはお金に関するデータ転送コストに関係したものです。
前者では、データをシリアライズするような処理はほぼコストがなく、とても速く、大した事はない、という考えてしまう例です。 実際は、大きなデータ構造は小さなデータ構造よりシリアライズに時間がかかり、送信先ではデシリアライズされる必要もあります。 これはあなたがネットワーク越しに何を送信する場合においても当てはまります。 小さなメッセージは、シリアライズ/デシリアライズによる影響を小さくすることができます。
データ転送コストがゼロだと想定する後者の誤解は、データを運ぶのにいくら掛かるかに関係しています。 現代的なサーバスタックでは、(RAM上もディスク上も)メモリは帯域と比較して安い場合が多いです。この帯域というのは、データが通過するネットワーク全体を保有していない限り、継続的にお金を払わなければいけないものです。 リクエストを少なくして、メッセージを小さくするという最適化は、この場合にも利益があります。
Erlangでは、前者の例に関して、他のノードに渡されるメッセージの圧縮については(圧縮をするための関数は既に存在はしていますが)特に注意は払われません。 そのかわり、必要があれば元々の設計者は独自の通信レイヤを実装する選択もできます。 したがって、プログラマにかかる責任というのは、小さなメッセージが送られるようにすることと、データ転送のコストを最小化するために他の指標を取ることです。
29.3.8. ネットワークは同質¶
最後の誤解は、ネットワークアプリケーションのすべてのコンポーネントが同じ言語をしゃべっている、あるいは一緒に操作するために同じ書式を使うというものです。
私たちのゾンビ生存者の例で言えば、すべての生存者が計画を立てるときに常に英語(あるいは流暢な英語)を話すという想定をしていないかや、1つの単語が様々な人に対して異なる意味を持つのではないかという疑問になりえます。

プログラミングにおいては、通常閉じた標準に依るものではなく代わりに公開された標準を使うのか、あるいはある規約から別の規約にいつでも移る準備があるか、という問題になります。 Erlangの場合、分散プロトコルは完全に公開されていますが、すべてのErlangノードは人々は同じ言葉を話していると想定しています。 Erlangクラスタに統合していこうとしている外側の人々は、Erlangのプロトコルを学んで話せるようになるか、あるいはErlangのアプリケーションにXML、JSONなどの変換レイヤを持たせるかする必要があります。
もしそれがアヒルのように鳴き、アヒルのようにに歩いたら、それはアヒルに違いありません。 これが、 C-nodes のようなものを持つ理由です。 C-nodes(あるいはC以外の言語で書かれたノード)は、どのような言語やアプリケーションでもErlangのプロトコルを実装でき、クラスタ内でErlangノードのふりをする事ができる、るという考えに基づいています。
データ交換に関する他の解法は、BERT、あるいは BERT-RPC と呼ばれるものを使うことです。 これはXMLやJSONのような交換用書式ですが、 Erlang External Term Format と呼ばれるものに似たものです。
手短にいうと、次のポイントを常に気をつけましょう:
- ネットワークを信頼すべきではありません。Erlangは(機能としては悪くありませんが)何がおかしくなったの検知以外の、特別な測定方法は提供しません。
- ネットワークは時々遅いものです。 Erlangは非同期機構を提供し、その使い方もわかっていますが、アプリケーションがその設定に逆らわず無駄にしないように注意しなければいけません。
- 帯域は無限ではありません。小さく、記述的なメッセージが求められます。
- ネットワークは安全ではなく、Erlangはデフォルトではこの問題に関して何も提供していません。
- ネットワークのトポロジーは変わるものです。Erlangからは明示的な想定はありませんが、どこにものがあって、どう命名されているかは考えたほうがいいでしょう。
- あなた(またはあなたの組織)は滅多にシステムの構造全体の制御権を持っていません。システムの複数の箇所は古いもので、違ったバージョンを使っていて、予期しない時に再起動または停止されます。
- データ転送にはコストがあります。再度になりますが、小さく短いメッセージが良いです。
- ネットワークは同質ではありません。すべてが同一なものではないですが、データ交換はよく記述された規約に依るべきです。
Note
分散コンピューティングに関する誤解はArnon Rotem-Gal-Ozの Fallacies of Distributed Computing Explained に紹介されています。
29.4. 生か、生殺しか¶
分散コンピューティングに関する誤解を理解することで、良い道具は持っているものの、なぜ私たちが暗闇の中のモンスターと戦っているのかが部分的にでも説明されたことでしょう。 まだまだ多くの問題ややるべきことが残っています。 それらのほとんどは、先に説明したような誤解に関係した注意事項(小さなメッセージ、通信量の削減など)を反映する設計に関する決定事項です。 最も難しい問題は、ノードが死んだりネットワークが信頼できなくなる状況に関係したものです。 この問題は、何かが死んでいるか生きているかを(対象にアクセスすることなく)知るのに良い方法がないため、特に扱いにくいです。
Bill、Zoey、Rick、Darylの4人のゾンビ災害からの生存者の例に戻りましょう。 彼らは皆隠れ家で落ち合って、そこで数日間の休息を過ごし、見つけてきた缶詰などを食べていました。 しばらくして、彼らはそこを出て、街に出て食料などを別々に探しに行かなければならなくなりました。 彼らは街の外れにある小さな集落で落ち合うことに決めました。
食料を探す間、彼らはお互いにトランシーバーで連絡を取り合っていました。 何を見つけたか、ゾンビが居ない道、あるいは他の生存者を見つけた、などの情報をやり取りしていました。
隠れ家と待ち合わせ場所の間のどこかで、Rickが仲間に連絡しようとしている状況を考えてみましょう。 彼はなんとかBillとZoeyに連絡できたけれど、Darylは応答しません。 BillやZoeyも彼に連絡がつきません。 問題は、Darylがゾンビに食べられてしまったのか、彼のトランシーバーの電池が切れたのか、彼は寝てしまったのか、あるいはただ地下にいるだけなのかを知る方法が全くないのか、ということです。
3人は彼を待ち続けるか、しばらく連絡を取り続けてみるか、あるいは彼は死んだものとして先に進むかを決めなければなりません。
同じようなジレンマが分散システムのノードにも当てはまります。 ノードが応答不能になった場合、ハードウェア障害でそのノードが死んだのか、アプリケーションがクラッシュしたのか、ネットワークが輻輳しているのか、あるいはネットワークが落ちたのでしょうか。 ある状況では、アプリケーションが動いていないだけで、単純にそのノードを無視して、処理を続けることができます。 他の状況では、アプリケーションはまだ孤立したノード上で動いているということも有り得ます。その場合、孤立したノードから見れば、他のノードが全部死んだ状況になるのです。
Erlangではデフォルトでは応答不能になったノードは死んだものとみなし、応答できるノードは生きているとみなします。 これは悲観的な手法ですが、破局的な障害が起きているときに非常に素早く反応したい場合には有用です。この手法では、ネットワークは一般的にハードウェアやシステム内のソフトウェアよりは障害が起きにくいと想定していて、Erlangの元々の用途を考えればこれは自然です。 (ノードはまだ生きていると想定する)楽観的な手法では、クラッシュに関連した報告は遅れます。なぜなら その手法ではネットワークはハードウェアやソフトウェアよりも障害が起きにくいと想定し、それゆえにクラスターは切断されたノードが再度接続するまで長い時間待ってしまいます。
ここで疑問が浮かびます。 悲観的なシステムでは、私たちが死んだと思ったノードが突如復活して、ノードは全然死んでいなかったと分かったときに、何が起きるのでしょうか。 ゾンビノードに唖然としてしまうでしょう。ゾンビノードとは、自身の命があったけれど、データや接続などのあらゆる点においてクラスターから孤立してしまったノードのことです。 ここでとてもややこしい事が起きます。
2つのノードが2つの異なるデータセンター上にあるシステムについて、ちょっと考えてみましょう。 そのシステムでは、ユーザは口座に預金があって、各ノードに満額保存されているとします。 そして各トランザクションはすべてのデータをお互いに同期します。 両ノードが問題なく稼働しているときには、ユーザは口座が空になるまでお金を使い続けることができ、使い尽くしたら何も買えなくなります。
ソフトウェアが順調に動作していましたが、ある瞬間に、片方のノードが他方から切断されてしまったとします。 このとき、他方が生きているか死んでいるかを知る方法はありません。 私たちが考えられることとしては、両ノードがまだ外からのリクエストを受け取っているけれど、お互いに通信出来ていないという状況です。
取れる一般的な戦略が2つあります。すべてのトランザクションを停止するか、否か、です。 トランザクションを止めることのリスクは、サービスが利用不可能になって、収益が減るということです。 トランザクションを止めないことのリスクは、口座に1000ドル持っているユーザに関して、2つのサーバで1000ドル分のトランザクションを受け入れて、合計でトランザクションが2000ドルになってしまうことです! いずれにせよ、正しく対処しないとお金を失うリスクがあるということです。
サーバスプリットが起きている間にアプリケーションを動かしたまま、サーバ間のデータを失うことなく、問題をすべて避ける方法はないのでしょうか。

29.5. もう1つのCAPは論理的¶
先ほどの質問に対する手短な回答は「いいえ」です。 悲しいことに、サーバスプリットが起きている間、アプリケーションを生かしたまま、データの整合性を保つ方法はありません。
この考えは CAP定理 ( You Can’t Sacrifice Partition Tolerance も面白いと思いますよ)として知られています。 CAP定理では、まずすべての分散システムに存在する、一貫性(Consistency)、可用性(Availability)、分断耐性(Partition Tolerance)という、3つの核となる属性について述べています。
29.5.1. 一貫性(Consistency)¶
先の例では、一貫性は、システム内に、リクエストに応答するノードが2個ある場合でも100個ある場合でも、ある時間において口座の預金額が完全に一致させることが出来るということです。 これは、通常はトランザクションを追加する(全ノードが、1台のデータベースへ変更を加えることに対して同意する)、あるいはそれと同様の機構を追加することで行われます。
定義では、一貫性とは、すべての操作が、多くのノードに渡るものでも単一の分割できないブロックに対してなされたものの用に見える、という状況です。 これは時間は関係なく、2つの異なる操作があるデータを修正したときに、複数の異なる値を入れないということです。 あるデータを修正したときに、他のアクターが同時にそのデータをいじって一日が無駄になってしまう、というような心配をしなくて済むべきです。
29.5.2. 可用性(Availability)¶
可用性の背景にある考え方は、システムにあるデータを要求した場合、応答を取得できるというものです。 もし結果が返ってこなかったら、システムは使い物になりません。 「すみません、私は死んでいるので、結果はわかりません」という応答はちゃんとした応答ではなく、ただの悲しい言い訳にすぎない、ということに注意して下さい。 この応答は、まったく応答がないのと(学術的には別問題として扱われますが)情報量が変わりません。
Note
CAP定理に関する考察で重要なのは、可用性は死んでいないノードに関する懸念でしかないということです。 死んだノードは、そもそも問い合わせを受け取れないため、応答できません。 これはノードが応答を送れない状態とは異なります。なぜなら、ここで問題になっているのは、すでにノードが存在していない状況だからです! ノードが要求を受け取れず、データの変更やエラーメッセージを返したりできない場合は、データの整合性の観点からすると技術的にはシステムのバランスには脅威ではありません。 クラスターの残りのノードが、死んだノードが復活して同期するまでの間、ただ通常よりも高い負荷に耐えればよいだけです。
29.5.3. 分断耐性(Partition Tolerance)¶
これはCAP定理のなかでもややこしい部分です。 分断耐性は通常システムの一部がお互いに通信出来なくなっても、システムが動作し続けられ(て、有用な情報を保持し続けられ)ることを指します。 分断耐性の鍵は、システムがコンポーネント間で失われる可能性があっても動作できるかということです。 この定義はいささか抽象的で締りがないですが、その理由を見ていきましょう。
CAP定理は基本的に、どのような分散システムでもCAPのうち2つだけ、つまりCA、CP、APのいずれかの特性を持つことができる、と語っています。 それらすべての特性を持つことはできません。 これは悪い知らせでもあり良い知らせでもあります。 悪い知らせというのは、ネットワークが壊れている場合においても、すべての特性を良い状態にしておくことは不可能である、ということです。 良い知らせというのは、これが定理であるということです。 もし顧客が3つの特性すべてを成立させるように言ってきたら、彼らにそれはまさに不可能であると言える強みがあり、CAP定理とは何かについての説明に時間を割く必要はありません。
3つの組み合わせの内、通常はCA(一貫性と可用性)の組み合わせは却下できます。 その理由は、この組み合わせを求める場合というのは、ネットワークが絶対に落ちないと言い切る、あるいはネットワークが原子単位として動作している場合(1つが落ちれば同時に他のものもすべて落ちる状態)のみです。
だれかが決して落ちないネットワークとハードウェアを発明しない限り、あるいはシステムの一部が落ちた瞬間にシステム全体を落とす方法を見つけない限り、障害は選択肢の一つです。 CAP定理のうち、APとCPの2つの組み合わせが残りました。 サーバスプリットによって切り離されているシステムでは、可用性か一貫性のどちらかを残すことはできますが、両方は無理です。
Note
システムによっては、’A’の’C’のどちらも残さないという選択をします。 高性能、たとえばスループット(どれくらいの問い合わせに応答することができるか)、あるいは遅延(どれくらい速く問い合わせに応答することができるか)に関する基準によっては、CAP定理の2特性(CA、CP、AP)を考えるのではなく、1つ以下の特性だけを追求することになります。
私たちの生存者の例で言えば、時間が経過して、彼らはかなりの時間ゾンビ集団の攻撃をかわし続けました。 弾丸が脳を貫通して、野球のバットは骨を砕き、何人かが後ろに残されています。 Bill、Zoey、RickそしてDarylのトランシーバーの電池は結局切れてしまい、通信ができなくなってしまいました。 幸いなことに、彼らそれぞれ2つの生存者居留地を発見しました。そこにいる科学者やエンジニアはゾンビからの生存にまさに命を賭けていました。 居留地の生存者は分散プログラミングの概念に慣れており、ライトや鏡の反射を使って、その場で作ったプロトコルで通信をすることにも慣れていました。
BillとZoeyは居留地「チェーンソー」を見つけ、一方でRickとDarylは「クロスボウ」キャンプを見つけました。 私たちの生存者は各居留地では新米で、しばしば外へいって食べ物を見つけたり、そこにいる生存者たちが色々と議論しているすきに、居留地周辺に接近しすぎたゾンビを殺すために派遣されました。この議論こそ、大ゾンビ災害の後にも残った唯一の戦争である「Vim対Emacs論争」でした。
居留地での100日目に、私たちの4人の生存者は、居留地同士で物々交換するために、お互いの中間で落ちあうよう、派遣されました。
居留地を離れる前に、チェーンソーとクロスボウの各居留地の代表が落ち合う場所を決めました。 落ち合う場所や時間が変わりそうなときはいつでも、RickとDarylはクロスボウに、ZoeyとBillはチェーンソーにそれぞれメッセージを送ることができます。 それから各居留地は他方の居留地に対して情報を送ることができ、これによって変更点を他方の生存者に送ることができます:
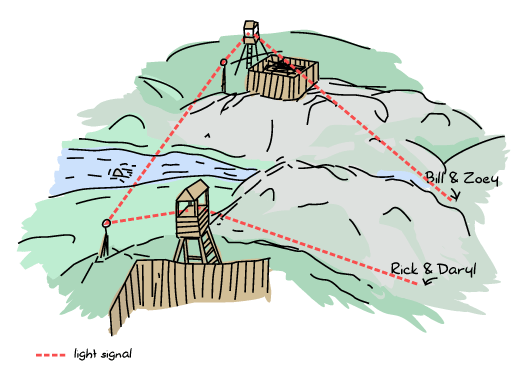
これらの前提で、4人の生存者は日曜日の朝に居留地を離れ、金曜日の夜明け前に落ちあうために、徒歩で長い旅に出ました。 (ときどき長い間生きているゾンビとの戦闘がある以外は)すべては順調でした。
不運にも、水曜日に強い雨とゾンビが勢いを増したことによってBillとZoeyは離れ離れになってしまい、道に迷い、予定よりも遅れてしまいました。 いまは次の図のような状況です:
さらに悪いことに、通常2つの居留地の間には晴れた空が広がっているのですが、雨が降ったあと霧がかかって、チェーンソーにいる計算機科学者たちはクロスボウの人々と通信できなくなってしまいました。 霧がなければ万事問題ないのですが、いまこの状況はまさしくサーバスプリットが起きているのと同じ状況です。
もし居留地が両方とも一貫性と分断耐性が保たれる手法を選べば、ZoeyとBillは新しい待ち合わせ時間を設定できないようにするでしょう。 CPの手法は、一貫性が保たれるように通常データの変更を止めて、すべての生存者が個々の居留地にときどき日程を確認することができるようにしておきます。 日程を変更することだけが出来ないようになっています。 変更不可にすることで、ある生存者が決定済みの待ち合わせ時間を混乱させることがないようにします。それでもなお、あらゆる連絡手段を絶たれた生存者は、何が起きても、独立して待ち合わせ場所に予定された日時で落ち合うことができます。
もし居留地が両方とも可用性と分断耐性が保たれる手法を選んだ場合、生存者は待ち合わせ日時を変更することができます。どちらの居留地も、待ち合わせに関する情報を自分たちで管理することができます。 したがって、Billが新しい待ち合わせ日時を金曜日の夜に設定した場合、全体の状態は次のようになります:
チェーンソー: 金曜日の夜 クロスボウ: 金曜日の夜明け前
分断された状態が続く限り、BillとZoeyはチェーンソーからのみ、RickとDarylはクロスボウからのみ情報を得ることになります。 これによって、生存者は必要とあれば各自で待ち合わせ情報を変更することができるのです。
ここで面白い問題は、分断が解消されたとき(霧が晴れたとき)にどのように異なるバージョンの情報を扱うのかということです。 CPの手法は、かなり単刀直入です。データは変更されなかったので、何もすることはありません。 APの手法はより柔軟なので、問題を解かなければいけません。 通常異なる戦略が採用されます:
- 「最後の書き込みが勝つ(Last Write Wins)」 は、最終更新がなんであろうとも、それが採用される、という衝突の解決法です。 これは分散の設定においては、タイムスタンプがずれていたり、あるいはまったく同じ時間に事象が発生したりするので、扱いにくいものになっています。
- あるいはランダムに書き込まれる値が選択される、というのも手です。
- より洗練された方法としては、最後の書き込みが勝つけれど、相対時計を使って時間を測る、というような時間を基準にした方法を使って衝突を減らすというものです。 相対時計は絶対時刻を刻んでいるものではなく、誰かがファイルを修正するたびに値を増加させていくものです。 相対時計について知りたい場合は、Lamportの論理クロックあるいはベクタークロックについて調べてみてください。
- 衝突をした場合にどうすべきかを選択する負担はアプリケーション(いまの例では生存者)に押し付けることもできます。 受け取る側は単に衝突している値の内どれが正しい値かを選択すればいいだけです。 これはSubversion、Mercurial、Gitといったソース管理において衝突をマージするときに起きていることと似ています。
どの方法がいいのでしょうか。 これまでの説明だと、オン/オフスイッチのように、完全にAPにするか、あるいは完全にCPにするかの2択しかないように考えてしまいます。 実世界では、この”Yes/No”の質問を、定足数のようなものを使って、どれくらいの一貫性が必要かを選ぶことができる目盛りに変えることができます。
定足数の仕組みはいくつかの非常に簡潔な規則で決めることができます。 システム内に N ノードがあるとして、データを変更できるようにするには、そのうち M ノードの同意が必要になるとします。 一貫性が比較的低くても大丈夫なシステムでは、全ノードのたった15%が同意すればデータの修正が可能になります。 高い一貫性を求める場合は、変更を行うにはおそらく全ノードの75%、つまりシステムのほとんどが稼働していなければならないでしょう。 この状況で、数ノードだけが孤立している場合、これらのノードにはデータを変更する権限はありません。 しかし、お互いに接続しあっているシステムの大部分は依然として順調に稼働しています。
変更に必要なノード数 M の値を N (ノードの総数)に変更することで、完全に一貫したシステムにすることができ、 M の値を 1 に変更することで、完全にAPなシステム、つまり一貫性が全く保証されないシステムになります。
さらに、この値を問い合わせ毎に調整することも可能です。つまり、あまり重要でない問い合わせが来ている場合(誰かがログインした!)には、求められる一貫性は低いでしょうし、在庫や会計に関する問い合わせに関しては、より高い一貫性が求められるでしょう。 これらをそれぞれの場合において、異なる衝突解決法を混ぜることで、驚くほど柔軟なシステムを構築することができます。
利用できる異なる衝突解決法を組み合わせることで、分散システムを構築する際にたくさんの選択肢ができますが、その実装は依然として非常に複雑なものです。 これらの詳細は詰めていかないですが、異なる選択肢が可能だということに気づくために、どのような事が出来るのかを考えることは重要だと思います。
ここからは、Erlangにおける分散システムの基礎をしっかりと学んでいきたいと思います。
29.6. Erlangクラスタを設定する¶
分散コンピューティングに関する誤解を扱う部分以外で、分散Erlangで最も難しいのは、最初に物事をきちんと設定することです。 異なるホスト間にまたがるノード同士を接続するのは、格別に面倒な作業です。 こういったことを避けるために、通常は1台のコンピュータ上で多くのノードを稼働させようとします。これで物事が簡単になります。
先ほども言ったように、Erlangは各ノードに名前を振って、各ノードの場所を探して連絡を取れるようにします。 ノード名は Name@Host の形式で、ここでホストはDNSエントリに基づいていて、ネットワーク越しに取得できるものか、コンピュータのホストファイル( OS X、Linuxあるいは他のUnixライクなOSであれば /etc/hosts 、Windowsでは C:\Windows\system32\drivers\etc\hosts )にあるものです。 ノード名は衝突を避けるためにすべて一意なものでなければいけません。もしまったく同じホストにある他のノードと同じ名前でノードを起動しようとすると、非常に恐ろしいクラッシュメッセージが表示されるでしょう。
このようにシェルを立ち上げてクラッシュを引き起こす前に、ノード名についてもう少し学ぶ必要があります。 ノード名には短い名前と長い名前の2つの種類があります。 長い名前は完全修飾ドメイン名( aaa.bbb.ccc )に基づいていて、多くのDNSリゾルバはドメイン名の中にピリオド( . )があった場合には、それは完全修飾であると判断します。 短い名前はピリオドがないホスト名に基づいていて、ホストファイル内にあるものやDNSエントリ内で取得できるものが選択されます。 このような理由から、一般的には1台のコンピュータ上で大量のErlangノードを設定するときは長いノード名ではなく短いノード名を使うので、簡単です。 最後にもう1つ。ノード名は一意である必要があるので、短い名前のノードは長い名前のノードとやり取りができず、逆もまた然りです。
Erlang VMを起動する際に、2つの異なるオプションを与えることで、長い名前あるいは短い名前を選択することができます。 erl -sname short_name@domain または erl -name long_name@some.domain のどちらかです。 また erl -sname short_name や erl -name long_name でもノードを起動することができます。 ErlangはOSのシステム設定に基づいて自動的にホスト名を与えてくれます。 最後に、 erl -name name@127.0.0.1 のように直接IPアドレスを渡して名前を降ることもできます。
Note
Windowsユーザは erl の代わりに werl を使うべきです。 しかしながら、分散ノードを起動して名前を振るためには、ノードの起動はショートカットや実行可能バイナリをクリックすることで起動するのではなく、コマンドライン経由で行うべきです。
2つのノードを起動しましょう:
erl -sname ketchup
...
(ketchup@ferdmbp)1>
erl -sname fries
...
(fries@ferdmbp)1>
fries を ketchup に接続させ(て、美味しいクラスタを作)るには、1つ目のシェルにいって、次の関数を実行しましょう:
(ketchup@ferdmbp)1> net_kernel:connect(fries@ferdmbp).
true
net_kernel:connect(NodeName) 関数は、他のErlangノードとの接続を確立します。(チュートリアルによっては net_adm:ping(Node) を使っていますが、 net_kernel:connect/1 のほうがしっかりしていて、信頼できます!) 関数呼び出しの結果が true となっていたら、おめでとうございます、分散Erlangのモードに入りました。 もし false となっていたら、ネットワークをうまく動作させるためにはただでは済まない状況になっています。 ぱっと動かすなら、ホストファイルを編集して、どんなホストも受け入れるようにしてください。 再度実行してみて、ちゃんと動くか見てみましょう。
自分のノード名はBIFである node() を呼び出すことで確認できます。そして、接続先はやはりBIFの nodes() で確認できます:
(ketchup@ferdmbp)2> node().
ketchup@ferdmbp
(ketchup@ferdmbp)3> nodes().
[fries@ferdmbp]
ノードをお互いに通信させるために、非常に単純な作業をします。 各シェルのプロセスをローカルの shell として登録します:
(ketchup@ferdmbp)4> register(shell, self()).
true
(fries@ferdmbp)1> register(shell, self()).
true
こうすると、プロセスを名前で呼び出すことができます。 {Name, Node} にメッセージを送ればこれが可能です。 両方のシェルで試してみましょう:
(ketchup@ferdmbp)5> {shell, fries@ferdmbp} ! {hello, from, self()}.
{hello,from,<0.52.0>}
(fries@ferdmbp)2> receive {hello, from, OtherShell} -> OtherShell ! <<"hey there!">> end.
<<"hey there!">>
見て分かる通り、メッセージを受け取って、他方のシェルにメッセージを送り返しています。他方のシェルも送り返されたメッセージを受け取っています:
(ketchup@ferdmbp)6> flush().
Shell got <<"hey there!">>
ok
ご覧のとおり、タプル、アトム、Pid、バイナリを問題なく自然に送信しました。 ほかのErlangデータ構造でも大丈夫です。 これでおしまいです。 これでもう分散Erlangの使い方は学んびました! 他にもまだ便利なBIFがあります。たとえば erlang:monitor_node(NodeName, Bool) です。 この関数は Bool の値を true にして呼び出したプロセスが、対象ノードが死んだときに {nodedown, NodeName} という形式のメッセージを受け取れるします。
他のノードの死活を確認に依存する特別なライブラリを書いているわけでなければ、 erlang:monitor_node/2 を使う必要が出てくることは滅多にないでしょう。 その理由は、 link/1 や monitor/2 がノードをまたいでも使えるためです。
fries ノードから次の設定をしてみましょう:
(fries@ferdmbp)3> process_flag(trap_exit, true).
false
(fries@ferdmbp)4> link(OtherShell).
true
(fries@ferdmbp)5> erlang:monitor(process, OtherShell).
#Ref<0.0.0.132>
それから ketchup ノードを殺すと、 fries シェルのプロセスは 'EXIT' とモニターメッセージをを受信します:
(fries@ferdmbp)6> flush().
Shell got {'DOWN',#Ref<0.0.0.132>,process,<6349.52.0>,noconnection}
Shell got {'EXIT',<6349.52.0>,noconnection}
ok
実際にやってみるとこのようなメッセージが表示されるはずです。 しかし、ちょっと待って下さい。 なぜPidがこのような形式になっているんでしょうか。 これは正しいPidですか。
(fries@ferdmbp)7> OtherShell.
<6349.52.0>
なんだって。これは <0.52.0> になるべきじゃないの。 いいえ、違います。 Pidの表示は単にプロセス識別子が実際はどうなっているかを見た目で表したでけです。 最初の番号はノードを表していて( 0 はプロセスが現在のノードにあることを意味しています)、2つ目の数字はカウンター、3つ目の数字は大量のプロセスを立てたときにカウンター数が足りなくなった場合の予備のカウンターです。 実際のPidの表現はこのようになっています:
(fries@ferdmbp)8> term_to_binary(OtherShell).
<<131,103,100,0,15,107,101,116,99,104,117,112,64,102,101,
114,100,109,98,112,0,0,0,52,0,0,0,0,3>>
バイナリ列 <<107,101,116,99,104,117,112,64,102,101,114,100,109,98,112>> が <"ketchup@ferdmbp">> のLATIN-1(あるいはASCII)表現の実際の姿で、プロセスが存在するノード名を表しています。 ここで2つのカウンター <<0,0,0,52>> と <<0,0,0,0>> があり、最後の値(3)はPidが古いノードから来たのか、死んだノードからきたのかなどを区別するためのトークン値です。 これがPidが透過的にどこでも使える理由です。
Note
ノードを切断するために殺す代わりに、BIFの erlang:disconnect_node(Node) を使ってノードを終了させずに取り除くこともできます。
Note
Pidがどのノードから来たものかわからない場合に、ノード名を知るためにバイナリに変換する必要はありません。 node(Pid) を呼び出すだけで、Pidのプロセスが動いているノード名を文字列として返してくれます。
他に面白いBIFとしては、 spawn/2 、 spawn/4 、 spawn_link/2 、 spawn_link/4 があります。 これらの関数は離れたノードに対してプロセスを生成するという以外は、他の spawn のBIFとまったく同様です。 ketchupノードで次のコマンドを試してみましょう:
(ketchup@ferdmbp)6> spawn(fries@ferdmbp, fun() -> io:format("I'm on ~p~n", [node()]) end).
I'm on fries@ferdmbp
<6448.50.0>
これは本質的にはリモートプロシージャコールです。つまり任意のコードを他のノードで実行できるのです。しかも通常のRPCよりも難しいということはなく、です! 面白いことに、関数は他のノードで動作しているのですが、出力はローカルで受信します。 これは正しい結果で、出力でさえ、透過的にネットワーク越しにリダイレクトされるのです。 この理由は、グループリーダーの考えに基づいています。 グループリーダーは、それらがローカルか否かと同じ方法で継承されます。
以上が、Erlangで分散システムのコードを書くために必要な道具です。 これで、ナタと懐中電灯と口ひげが揃いました。 いまやあなたは、このような分散のレイヤがない他のプログラミング言語では非常に長い時間をかけてようやく到達するレベルまでやって来ました。 いよいよモンスターを狩るときがやってきました。 まずは手始めに、クッキーモンスターについて学ぶ必要があります。
29.7. Cookies¶

この章の始めを思い出すと、すべてのErlangノードはメッシュの様に設定されていると言っていました。 誰かがノードに接続した場合、ほかのすべてのノードに接続したことになります。 同じハードウェア上で、異なるErlangノードクラスタを走らせたいことが度々あると思います。 そのような場合に、間違って別のErlangノードクラスタに一緒に接続してしまいたくないでしょう。
このような理由から、Erlangの設計者は Cookie と呼ばれる小さなトークン値を追加しました。 公式なErlangドキュメントでは、Cookieをセキュリティに関する部分に書いていますが、それはセキュリティに関するものではありません。 もし本当にセキュリティのためにこれを用意したのであれば、冗談にしか思えません。なぜなら、誰もCookieを安全なものだと思っていないからです。 なぜかって? 単純に、Cookieは小さな一意な値で、お互いが接続するためにノード間で共有されているからです。 これはパスワードというよりユーザ名に近いもので、だから誰もユーザ名(それ以外の要素なしで)をセキュリティのために使おうとは思わないでしょう。 Cookieは認証機構としてよりも、ノードクラスタを分割するための機構に使われると理解すれば合点が行きます。
ノードにCookieを与えるには、ノードを起動するときに -setcookie Cookie という引数をコマンドラインに追加するだけでできます。 新規に2つのノードで試してみましょう:
$ erl -sname salad -setcookie 'myvoiceismypassword'
...
(salad@ferdmbp)1>
$ erl -sname mustard -setcookie 'opensesame'
...
(mustard@ferdmbp)1>
いま、両ノードとも異なるCookieを持っていて、各ノードはお互いに通信できては行けないはずです:
(salad@ferdmbp)1> net_kernel:connect(mustard@ferdmbp).
false
これは拒否されました。 出力に特に説明はありません。 一方で、mustardノードを見てみると:
=ERROR REPORT==== 10-Dec-2011::13:39:27 ===
** Connection attempt from disallowed node salad@ferdmbp **
わかりやすいですね。 ここでもし、saladとmustardのノードを一緒にしたくなったらどうしたら良いでしょうか。 erlang:set_cookie/2 というBIFがいま期待している事を行なってくれます。 erlang:set_cookie(OtherNode, Cookie) を呼び出すと、そのCookieを指定したノードに接続するときにだけ使うようになります。 ここで代わりに erlang:set_cookie(node(), Cookie) と呼び出すと、そのノードでそれ以降の接続に使うCookieを変更することになります。 変更を確認するには erlang:get_cookie() を使います:
(salad@ferdmbp)2> erlang:get_cookie().
myvoiceismypassword
(salad@ferdmbp)3> erlang:set_cookie(mustard@ferdmbp, opensesame).
true
(salad@ferdmbp)4> erlang:get_cookie().
myvoiceismypassword
(salad@ferdmbp)5> net_kernel:connect(mustard@ferdmbp).
true
(salad@ferdmbp)6> erlang:set_cookie(node(), now_it_changes).
true
(salad@ferdmbp)7> erlang:get_cookie().
now_it_changes
すばらしい。 最後にCookieの機構についてもう1つ確認することがあります。 この章の始めのほうに出ていた例を試してみたならば、ホームディレクトリを見てみてください。 そこに .erlang.cookie という名前のファイルがあるはずです。 中身を見てみると、 PMIYERCHJZNZGSRJPVRK というようなランダムな文字列があると思います。 Cookieを与えるコマンドを明示しなくても、Erlangでは分散ノードを立ち上げたときにはいつでもこのファイルを作成して、このような文字列をファイルに追加します。 その後、Cookieを指定せずにノードを再び起動した時にはいつでも、そのVMはホームディレクトリを確認して、Cookieファイルの中にあるCookieを使います。
29.8. リモートシェル¶
Erlangでまずはじめに学んだことの1つに、実行中のコードを ^G ( CTRL + G )を使って中断する方法がありました。 これを実行したときに、分散シェルのメニューを見ました:
(salad@ferdmbp)1>
User switch command
--> h
c [nn] - connect to job
i [nn] - interrupt job
k [nn] - kill job
j - list all jobs
s [shell] - start local shell
r [node [shell]] - start remote shell
q - quit erlang
? | h - this message
r [node [shell]] オプションがいま探しているものです。 次のようにして、mustardノードでジョブを起動します:
--> r mustard@ferdmbp
--> j
1 {shell,start,[init]}
2* {mustard@ferdmbp,shell,start,[]}
--> c
Eshell V5.8.4 (abort with ^G)
(mustard@ferdmbp)1> node().
mustard@ferdmbp
そして、ローカルのシェルと同様にリモートシェルを使うことができます。 古いバージョンのErlangでは、たとえば自動補完が効かないなどの、多少の違いはあります。 これは、 -noshell オプションで稼働しているノードで変更を行う必要がある時には非常に便利です。 もし -noshell のノードに名前が付いていたら、それに接続してモジュールの再読み込みやコードのデバッグなどの管理作業を行うことができます。
再度 ^G を実行すると、元のノードに戻ります。 しかし、セッションを閉じるときは注意してください。 q() や init:stop() を呼び出すと、リモートノードを終了してしまいます!

29.9. 隠しノード¶
Erlangノードは net_kernel:connect/1 を呼び出すことで接続できますが、ノード間のどのようなやりとりも接続を確立してしまうということを意識しなければいけません。 spawn/2 を呼び出す、あるいは外のPidにメッセージを送ることで自動的に接続を確立してしまうのです。
このような状況は、大きなクラスタがあったときに、1つのノードに接続してちょっとしたやりとりをしたいような場合にはイライラします。 管理ノードをクラスターに統合して、「タスクを渡すことが出来る新しい同僚が来た」くらいにしか思っていない他のノードと接続させたくはないでしょう。 クラスターに接続せずにメッセージを送るには、滅多に使うことのない、 erlang:send(Dest, Message, [noconnect]) 関数を使うことで、接続を張らずにメッセージを送ることができますが、これはかなりエラーを起こしやすいです。
代わりに、ノードを設定するときに -hidden フラグを立てて起動するのがいいでしょう。 たとえば、まだmustardとsaladのノードを稼働させたままだとしましょう。 いまから3つ目のノードの olives を起動して、これをmustardにのみ接続させます(Cookieは同じにして下さい!):
$ erl -sname olives -hidden
...
(olives@ferdmbp)1> net_kernel:connect(mustard@ferdmbp).
true
(olives@ferdmbp)2> nodes().
[]
(olives@ferdmbp)3> nodes(hidden).
[mustard@ferdmbp]
やった! ノードはketchupには接続しておらず、また最初は一見mustardにも接続していないように見えました。 しかし、 node(hidden) を呼び出すと、mustardに接続していることがわかります! mustardノードに何が見えているか確認してみましょう:
(mustard@ferdmbp)1> nodes().
[salad@ferdmbp]
(mustard@ferdmbp)2> nodes(hidden).
[olives@ferdmbp]
(mustard@ferdmbp)3> nodes(connected).
[salad@ferdmbp,olives@ferdmbp]
同様ですが、ここで nodes(connected) というBIFを使って、接続の種類によらず、すべての接続を確認しました。 olivesには、特に接続するように指示しない限り、ketchupノードは決して見えませんでした。 nodes/1 の面白い使い方として最後に1つ挙げると、 nodes(known) という使い方があって、これは現在のノードがこれまでに接続したすべてのノードを表示します。
リモートシェルとCookieと隠しノードを使うことで、分散Erlangシステムの管理はより簡潔になります。
29.10. 火の壁があり、ゴーグルは役に立たなかった¶
分散Erlangでファイアウォールを通過したい(そしてトンネリングはしたくない)なら、Erlangの通信用にいくつかポートを開けたいと思うでしょう。 ポートを開けたいのであれば、EPMDのデフォルトポートである4369番ポートを開けたくなると思います。 このポートは、Ericssonによって公式にEPMD用ポートとして登録されているので、便利です。 つまり、標準規格に準拠したあらゆるOSは、EPMD用に容易されたこのポートを自由に使うことができます。
その後ノード間である範囲のポートを通信用に開けたくなったとしましょう。 問題はErlangはノード間の通信にランダムのポート番号を割り当てるということです。 しかしながら、2つの隠しアプリケーション変数にポート番号の割り当て範囲を指定できるものがあります。 この2つのは kernel アプリケーションにある inet_dist_listen_min と inet_dist_listen_max です。
次の例のように、Erlangを erl -name left_4_distribudead -kernel inet_dist_listen_min 9100 -kernel inet_dist_listen_max 9115 というように起動して、Erlangノード用に15個の範囲でポートを開ける事ができます。 あるいは代わりに、次のような ports.config という設定ファイルを作成することもできます。
[{kernel,[
{inet_dist_listen_min, 9100},
{inet_dist_listen_max, 9115}
]}].
このようにファイルを作成してから、 erl -name the_army_of_darknodes -config ports というようにErlangノードを起動します。 変数も同様に設定されます。
29.11. 彼方からの電話¶
これまでに見てきたBIFや概念に加えて、分散を扱う開発者に役立つモジュールがいくつかあります。 まず最初は net_kernel で、これはノードの接続に使いました。そして先にも述べたように、切断にも使いました。
他にも洒落た機能がいくつかあって、たとえば分散でないノードを分散ノードに変換することができます:
erl
...
1> net_kernel:start([romero, shortnames]).
{ok,<0.43.0>}
(romero@ferdmbp)2>
erl の起動オプションである -sname や -name と同等のことをするために、 shortnames や longnames というオプションを使うことができます。 さらに、ノードが大きいメッセージを送る事がわかっていて、それによってノード間のハートビートを大きくする必要があるとわかってる場合は、リストの中に3つ目の引数を渡すことができます。 net_kernel:start([Name, Type, HeartbeatInMilliseconds]) がそれです。 デフォルトでは、ハートビート遅延( tick time とも呼ばれています)は15秒、つまり15000ミリ秒に設定されています。
他にも set_net_ticktime(Ms) という関数があって、これは切断を避けるためにtick timeを変更するときに使います。また net_kernel:stop() は分散状態を辞めて通常モードに戻るときに使います。
(romero@ferdmbp)2> net_kernel:set_net_ticktime(5000).
change_initiated
(romero@ferdmbp)3> net_kernel:stop().
ok
4>
次に分散に便利なモジュールは global です。 globalモジュールは、新しい代替のプロセスレジストリです。 これは自動的にデータを接続しているノードに拡散して、そこにデータを複製して、ノードの障害に対応して、ノードが再びオンラインになったときに異なる衝突解決法をサポートします。
global:register_name(Name, Pid) を呼び出して名前を登録し、 global:unregister_name(Name) で登録を解除できます。 もし、名前の移動をしたい時は、 global:re_register_name(Name, Pid) を呼び出せばいいでしょう。 またプロセスIDは global:whereis_name(Name) で、メッセージの送信は global:send(Name, Message) で可能です。 必要な物はすべてあります。 特に素晴らしいのは、プロセスを登録する際に使う名前は どのような 名前でも良いということです。
2つのノードが接続していて、両ノードが同じ名前を持つ2つの異なるプロセスを持っていた場合、名前の衝突が起きます。 この場合、globalはデフォルトではランダムでどちらかのプロセスを殺します。 この動作を上書きすることもできます。 プロセス名を登録または再登録するときにはいつでも、関数に3つ目の引数を渡してください:
5> Resolve = fun(_Name,Pid1,Pid2) ->
5> case process_info(Pid1, message_queue_len) > process_info(Pid2, message_queue_len) of
5> true -> Pid1;
5> false -> Pid2
5> end
5> end.
#Fun<erl_eval.18.59269574>
6> global:register_name({zombie, 12}, self(), Resolve).
yes
Resolve 関数はメールボックス内のメッセージが一番多いプロセスを選びます。(関数が返すPidのプロセスです) 代わりに、両プロセスに接続して、一番サブスクライバが多いかを訊くか、あるいは最初のプロセスだけを返信する、などの方法も採れますね。 もし、 Resolve 関数がクラッシュしたり、Pid以外のものを返したら、プロセス名は登録解除されています。 便利のために、globalモジュールはすでに3つの関数を事前定義してくれています:
- global:random_exit_name/3 関数はランダムにプロセスを殺します。これはデフォルトのオプションです。
- global:random_notify_name/3 関数は2つのプロセスの内から、生かしておくのプロセスをランダムに1つ選んで、 {global_name_conflict, Name} というタプルを殺されるプロセスに送ります。
- global:notify_all_name/3 関数は両方のPidに対応するプロセスを登録解除して、両プロセスに {global_name_conflict, Name, OtherPid} というメッセージを送り、両プロセスに再登録できるように自分で衝突の問題を解決させます。

global モジュールには1つ欠点があって、名前衝突とノードが落ちたことを検知するのがかなり遅いと言われています。 それ以外は良いモジュールで、ビヘイビアにすらもサポートされています。 gen_Something:start_link(...) でローカルの名前( {local, Name} )を使った呼び出しをすべて {global, Name} に変更して、すべての呼び出しとキャスト(とそれに対応するもの)を、単に Name ではなく {global, Name} を使うように変更してあげれば、分散して動くようになります。
便利なモジュールリストにある次の候補は rpc です。これは リモートプロシージャコール を意味する略語です。 このモジュールにはリモートノード上でコマンドを実行できる関数が含まれていて、並行操作を促進する関数もいくつか含んでいます。 これらを試してみるために、2つの異なるノードを起動して、お互いに接続させてみましょう。 やり方はみなさんもうお分かりだと思うので、今回はここでは示しません。 2つのノード名は cthulu と lovecraft です。
最も基本のrpcの操作は rpc:call/4-5 です。 これは、与えられた操作を離れたノード上で実行し、結果をローカルで取得できるようにします:
(cthulu@ferdmbp)1> rpc:call(lovecraft@ferdmbp, lists, sort, [[a,e,f,t,h,s,a]]).
[a,a,e,f,h,s,t]
(cthulu@ferdmbp)2> rpc:call(lovecraft@ferdmbp, timer, sleep, [10000], 500).
{badrpc,timeout}
cthuluノードでのこの call で見てわかるように、この関数で4つの引数がある場合は rpc:call(Node, Module, Function, Args) という形式となります。 5つ目の引数を取る場合はタイムアウトが加わります。 rpc呼び出しは、関数の実行結果が返してきたものはなんでも返し、失敗したときは {badrpc, Reason} を返します。
以前に、分散コンピューティングあるいは並行コンピューティングの概念についえ研究したことがあれば、promiseについて聞いたことがあるでしょう。 promiseはリモートプロシージャコールに少し似ていますが、非同期である点が異なります。 rpc モジュールは次のような機能を提供しています:
(cthulu@ferdmbp)3> Key = rpc:async_call(lovecraft@ferdmbp, erlang, node, []).
<0.45.0>
(cthulu@ferdmbp)4> rpc:yield(Key).
lovecraft@ferdmbp
rpc:async_call/4 関数の結果と rpc:yield(Res) 関数の結果を結合することで、非同期リモートプロシージャコールを行うことができ、あとで結果を取得することができます。 これは特に、いまから実行しようとしているRPCが返り値を取得するのに時間がかかると分かっているときには便利です。 このような場合、非同期RPCを実行してしまい、しばらく他の作業(他の呼び出し、データベースからレコードの取得、お茶を飲むなど)を処理し、さらに他にすることが残っていなければ結果を待ちます。 もちろん、必要があれば、自分のノード上で関数呼び出しを行なってもいいでしょう:
(cthulu@ferdmbp)5> MaxTime = rpc:async_call(node(), timer, sleep, [30000]).
<0.48.0>
(cthulu@ferdmbp)6> lists:sort([a,c,b]).
[a,b,c]
(cthulu@ferdmbp)7> rpc:yield(MaxTime).
... [long wait] ...
ok
どうしても、 yield/1 関数をタイムアウト値付きで使いたい場合は、 rpc:nb_yield(Key, Timeout) を代わりに使いましょう。 結果をポーリングで待つには、 rpc:nb_yield(Key) を使います。(これは rpc:nb_yield(Key,0) と等価です):
(cthulu@ferdmbp)8> Key2 = rpc:async_call(node(), timer, sleep, [30000]).
<0.52.0>
(cthulu@ferdmbp)9> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)10> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)11> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)12> rpc:nb_yield(Key2, 1000).
timeout
(cthulu@ferdmbp)13> rpc:nb_yield(Key2, 100000).
... [long wait] ...
{value,ok}
結果を気にしないのであれば、 rpc:cast(Node, Mod, Fun, Args) を使って、コマンドを他のノードに送って、それきりにすることができます。
いまは未来はあなたのものです! しかし、待ってください。もし、一度に2つ以上のノードに対してRPCを行いたい場合はどうしたらいいでしょうか。 私たちの小さなクラスターに3つのノード minion1 、 minion2 、 minion3 を加えてみましょう。 これらはcthuluの子分(minion)です。 これらのノードに何か聞きたいときは、3つ別々に呼び出しを行わなければならず、命令を下すときは、3回命令を投入しなければなりません。 これはかなり面倒ですし、非常に大きな軍隊になった場合にはスケールしません。
コツは呼び出しと投入に対して、それぞれ rpc:multicall(Nodes, Mod, Fun, Args) (引数 Timeout もオプションで渡せます)と rpc:eval_everywhere(Nodes, Mod, Fun, Args) という、2つのRPC関数を使うことです:
(cthulu@ferdmbp)14> nodes().
[lovecraft@ferdmbp, minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp]
(cthulu@ferdmbp)15> rpc:multicall(nodes(), erlang, is_alive, []).
{[true,true,true,true],[]}
これは、まさに、全4ノードは生きてい(て、誰も答えられない状態でい)るということを示しています。 タプルの左側が生きている、右側が死んでいるということです。 erlang:is_alive() というのは単にノードが生きているか否かを返すだけの関数です。少し見た目はおかしいかもしれません。 さらにもう一度、分散の設定においては、 alive というのは「到達できない」ということを意味していて、「稼働していない」ということではありません。 たとえば、cthuluが子分のことを評価していなくて、子分を殺す決意をした、あるいはさらに彼らに殺し合いをするように命じたとしましょう。 これは命令なので、メッセージを投入します。 このような理由なので、子分ノード上での init:stop() を呼び出しで eval_everywhere/4 を使います:
(cthulu@ferdmbp)16> rpc:eval_everywhere([minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp], init, stop, []).
abcast
(cthulu@ferdmbp)17> rpc:multicall([lovecraft@ferdmbp, minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp], erlang, is_alive, []).
{[true],[minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp]}
誰が生きているかを再び確認したときには、たった1つのノード、lovecraftだけが残っています。 子分(minion)は従順な生き物なのです。 RPCには他にもいくつかもっと面白い関数があるのですが、主な使い方はここで確認できました。 もっと知りたい場合は、モジュールのドキュメントを綿密に読むことをおすすめします。
29.12. Distribunomiconを埋める¶
さあ、これで分散Erlangの基礎はだいたいおしまいです。 考えなければいけないことがたくさんあって、覚えておく属性がたくさんありますね。 分散アプリケーションを開発しなければならないときはいつでも、(あるとすれば)いま挙がった分散コンピューティングの誤解のうち、どれに遭遇しそうかを考えてみましょう。 もし顧客が一貫性と可用性を保ったままサーバスプリットを扱うようなシステムを構築するように依頼してきたら、CAP定理を丁寧に説明するか、逃げるか(一番簡単なのは窓から飛び降りることです)のどちらかを剃る必要があるでしょう。
一般的に、何千もの孤立したノードがあるアプリケーションでは、各ノードが通信やお互いに依存なしに自分の処理を行うのが最もスケールしやすいです。 ノード間の依存が形成されればされるほど、どのような分散レイヤを用意しても、スケールはしづらくなります。 これは(冗談抜きで)ゾンビのようです。 ゾンビは、非常に大量にいる上に、集団で来ると殺すのが非常に難しいので、恐ろしいです。 たとえ、個々のゾンビはとても鈍く、脅威ではなくとも、大群になると、たとえその中から多くのゾンビが殺されたとしても、とてつもない被害を与えてきます。 人間の生存者集団は、彼らの知性を結集して、一緒にコミュニケーションを取ることで、偉業を成し遂げることができますが、各個人の死は皆に大きくのしかかり、士気に影響します。
それはそれとして、事を運ぶための道具は手に入れました。 次の章では、分散OTPアプリケーションの概念を紹介します。これはハードウェア障害のテイクオーバーやフェイルオーバー機構を提供しますが、一般的な分散とは違います。死んだゾンビを再生性する、と言ったほうが正しいでしょう。