30. 分散OTPアプリケーション¶
Erlangは多くの仕事を残してくれましたが、解決策も提供してくれました。 その内の1つが分散OTPアプリケーションの概念です。 分散OTPアプリケーション、あるいはOTPの文脈中では単純に分散アプリケーションとも呼びますが、これはテイクオーバー機構やフェイルオーバー機構を定義できるようにします。 それがどういう意味なのか、どのように動作するのかを確認しつつ、小さなデモアプリケーションを書いてみましょう。
30.1. OTPにさらに追加¶
OTPアプリケーションの章を思い出すと、中心となるアプリケーションコントローラを使って、アプリケーションマスターにディスパッチして、それぞれがアプリケーションの最上位のスーパバイザを監視している、という構成のアプリケーションを簡単に見てきました:
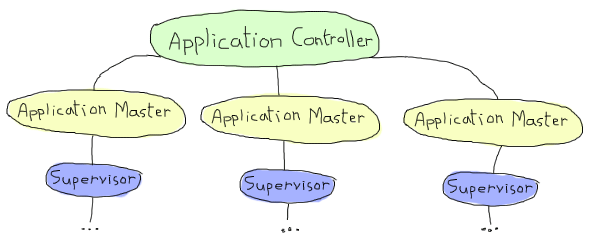
通常のOTPアプリケーションでしゃ、アプリケーションは読み込まれ、起動され、停止または解放されました。 分散アプリケーションでは、動作方法を変えます。まずアプリケーションコントローラは処理を、そのすぐとなりで動作している他のプロセス(通常 dist_ac と呼ばれます)である 分散アプリケーションコントローラ と共有します。
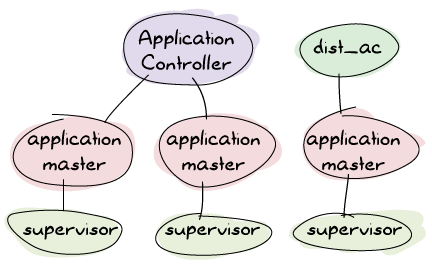
アプリケーションファイルに依存して、アプリケーションの所有権は変更します。 dist_acは全ノード上で起動され、すべてのdist_acはお互いに通信します。 その通信内容は1つの情報以外にはさほど関係ありません。 その1つとは、先にも触れたように、4つのアプリケーションステータスのことで、読み込ま中、起動中、停止中、解放中のいずれかです。分散アプリケーションでは、「起動したアプリケーション」という状態を、「起動した」と「稼働中」の状態に分割しました。
この状態の違いというのは、アプリケーションをクラスタ内でグローバルにしたときに定義できるものです。 このようなアプリケーションは、一度に1つのノード上でしか稼働できず、一方で通常のOTPアプリケーションは他のノードで何が起きていようが気にすることはありません。
このような分散アプリケーションはクラスタの全ノードで起動されますが、1つノード上でしか稼働はしていません。
これは、アプリケーションは起動しているけれど稼働していないノードにとって、どのような意味があるのでしょうか。 このようなノードがすることは、ただただアプリケーションを稼働させているノードが死ぬのを待つことだけです。 つまり、アプリケーションを稼働させているノードが死んだときに、他のノードがそのアプリケーションを代わりに稼働させ始めるのです。 このように、異なるサブシステムに移動してまわることで、サービスが中断することを避ける事ができます。
この動作をさらに詳細に見ていきましょう。
30.2. テイクオーバーとフェイルオーバー¶
分散アプリケーションでの処理で2つの重要な概念があります。 1つ目はフェイルオーバーです。 フェイルオーバーは、先ほど説明したように、アプリケーションが停止したときに、別の場所で再起動することを指します。
これは冗長なハードウェアを持っている場合には、実用的に妥当な戦略です。 何かを「メイン」コンピュータあるいはサーバで稼働させて、もしそれに障害が起きた場合は、バックアップの方に移します。 より大きなスケールのデプロイでは、代わりに50台のサーバがあなたのソフトウェアを稼働させていて(全サーバがだいたい60-70%の負荷)、どこかで障害が起きても、その負荷を稼働中のサーバが吸収するようになっています。 フェイルオーバーの概念というのは、前者において重要で、後者の場合ではそこまで考えられていません。
分散OTPアプリケーションの概念において重要なことの2つ目はテイクオーバーです。 テイクオーバーは、死んだノードが復活し、バックアップノードよりも重要だと知らせ(いいハードウェアなのでしょう)、そして再度アプリケーションを稼働させる、という動作のことを指します。 これは通常、ゆっくりとバックアップアプリケーションを停止させて、代わりにメインアプリケーションを起動します。
Note
分散プログラミングに関する誤解においては、分散OTPアプリケーションでは、障害が起きたときには、ハードウェア障害によるものだとみなし、サーバスプリットによるものだとは想定しません。 もしハードウェア障害よりもサーバスプリットが起きやすいと思えるのであれば、バックアップとメインのアプリケーションが両方共稼働してしまう可能性を意識すべきで、ネットワーク障害が解決したときにおかしな事が起こりうることを意識しておくべきでしょう。 おそらくこの場合、分散OTPアプリケーションは、正しい機構ではありません。
ここで3つのノードを持つシステムがあって、最初の1つだけがあるアプリケーションを稼働させている状況を想像してみましょう:

いまちょうど A が死んだとして、ノード B と C はバックアップノードとして定義されています:

ほんの少しの間、何も稼働していません。 しばらくして、 B がこの状況に気がついて、アプリケーションを引き継ぐと決めました:
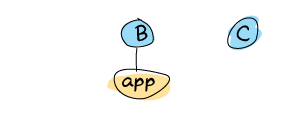
これがフェイルオーバーです。 そして B がしんで、アプリケーションは C 上で再起動します:

さらにフェイルオーバーがおきて、万事良好です。 いま、 A が復活したと想定しましょう。 C はいまアプリケーションを幸せに稼働させていますが、 A は私たちがメインノードと定義したものです。 このときテイクオーバーが発生します。 C 上のアプリケーションは自発的に終了し、 A 上で再起動します:

他の障害においても同様です。
1つ明らかな問題としては、いつでもこのようにアプリケーションを終了すると重要な状態を失いやすいということです。 悲しいことに、この問題はあなたが解決しなければいけません。 こういった致命的になりうる状態を、破壊してしまう前にどこに置いておくか、というのを考えなければならないでしょう。 分散アプリケーションのためのOTP機構は、この問題に関して特別なものは用意していません。
とにかく、実践的にはどのように動かしているか見ていきましょう。
30.3. 魔法の8ボール¶
魔法の8ボールはガチャガチャと振るだけの単純なおもちゃで、これで占いをして有益な結果を取得するのです。 「私の贔屓のスポーツチームは今夜の試合に勝ちますか?」といった質問をすると、あなたが振ったボールは「間違いなく勝つでしょう」というように答えてくれます。 これで安心して試合結果に家の抵当権を掛けることができますね。 ほかにも「将来、投資には慎重になったほうがいいでしょうか?」に対しても「まったく縁はなさそうだ」とか「分からない」といった回答をしてくれます。 魔法の8ボールは過去数十年、西洋の政治的な決定において極めて重要でしたし、これをフォルトトレランスの例として使うのは至って普通のことです。
私たちの例では、DNSラウンドロビンやロードバランサといった、自動的にサーバを見つけるための実世界の切り替え機構は使いません。 それよりも、純粋なErlang実装にこだわり、分散OTPアプリケーションの一部として3ノード(下に A 、 B 、 C と示されています)を持つことにします。 A ノードは魔法の8ボールサーバを稼働させているメインノードで、 B と C はバックアップノードです:
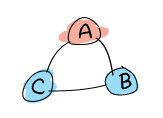
A が落ちたときはいつでも、8ボールアプリケーションは B か C のどちらかの上で再起動されるべきです。そして両ノードともに透過的に8ボールアプリケーションを使えるようになっているでしょう。
分散OTPアプリケーションの設定を行う前に、まずアプリケーション自身を構築します。 これは、設計において驚くほど繊細な作業となります:
動作させるには、スーパバイザ、サーバ、アプリケーションコールバックモジュールの合わせて3つのノードを持つことになります。 スーパバイザはかなり普通なものです。 このスーパバイザを m8ball_sup (Magic 8 Ball Supervisorの略)と命名し、これを通常のOTPアプリケーションでの src/ ディレクトリに置きます:
-module(m8ball_sup).
-behaviour(supervisor).
-export([start_link/0, init/1]).
start_link() ->
supervisor:start_link({global,?MODULE}, ?MODULE, []).
init([]) ->
{ok, {{one_for_one, 1, 10},
[{m8ball,
{m8ball_server, start_link, []},
permanent,
5000,
worker,
[m8ball_server]
}]}}.
これが、永続ワーカプロセスである1つのサーバ( m8ball_server )を起動するスーパバイザです。 これは10秒ごとに失敗することが許されています。
魔法の8ボールサーバは先程より少々複雑になっています。 これは次のようなインターフェースを持ったgen_serverとして構築します:
-module(m8ball_server).
-behaviour(gen_server).
-export([start_link/0, stop/0, ask/1]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
code_change/3, terminate/2]).
%%%%%%%%%%%%%%%%%
%%% INTERFACE %%%
%%%%%%%%%%%%%%%%%
start_link() ->
gen_server:start_link({global, ?MODULE}, ?MODULE, [], []).
stop() ->
gen_server:call({global, ?MODULE}, stop).
ask(_Question) -> % the question doesn't matter!
gen_server:call({global, ?MODULE}, question).
ここで、どのようにサーバが {global, ?MODULE} を名前として使って起動され、また各呼び出しにおいて同じタプルを使ってどのようにサーバがアクセスされるかを見てください。 これは前の章で見た、 global モジュールで、ビヘイビアに適用されています。
次に、実際の実装であるコールバックが来ます。 これをどのように構築するかお見せする前に、どのような動作を期待しているかを説明しましょう。 魔法の8ボールは、多くの設定ファイルの中にある返答の中からランダムに1つを選択します。 渡したい回答の追加や削除が簡単にできるので設定ファイルが望ましいです。
まずはじめに、物事をランダムに行いたいときには、init関数の中でなんらかのランダムさを設定する必要があります:
%%%%%%%%%%%%%%%%%
%%% CALLBACKS %%%
%%%%%%%%%%%%%%%%%
init([]) ->
<<A:32, B:32, C:32>> = crypto:rand_bytes(12),
random:seed(A,B,C),
{ok, []}.
このような書き方は ソケットの章 で見ました。ここではランダムな12バイドを使って、 random:uniform/1 関数で使われるランダムシードの初期値を設定しています。
次の手順は、設定ファイルから回答を読み込んで1つを選択する部分です。 OTPアプリケーションの章 を思い出すと、設定を用意する最も簡単な方法は app ファイルを( env タプルの中で)使うことでした。 このように設定してみましょう:
handle_call(question, _From, State) ->
{ok, Answers} = application:get_env(m8ball, answers),
Answer = element(random:uniform(tuple_size(Answers)), Answers),
{reply, Answer, State};
handle_call(stop, _From, State) ->
{stop, normal, ok, State};
handle_call(_Call, _From, State) ->
{noreply, State}.
最初の節に私たちがしたいことが書いてあります。 すべての回答が env タプル内の answers 内に保持されていることを期待します。 なぜタプルなのでしょうか。 それは単純に、タプルの要素へのアクセスは定数時間で行える操作で、一方でリストからの取得は線形に時間がかかる(したがってリストが大きければ長い時間がかかる)からです。 それから回答を返します。
Note
サーバは質問が来るたびに application:get_env(m8ball, answers) を使って回答を読み込みます。 もし application:set_env(m8ball, answers, {"yes","no","maybe"}) のような呼び出し方で、新しい回答を設定した場合は、直ちにそれ以降の呼び出しにおいてこの3つの回答が選択肢となります。
長時間稼働させるのであれば、回答をサーバの起動時に1度だけ読んでしまうのがいくらか効率的でしょうが、回答を更新する唯一の方法がアプリケーションの再起動のみとなってしまします。
これまで、聞かれた質問に関しては何も気にしていないということに気がついたでしょうか。質問はサーバに渡されてすらいませんでした。 回答をランダムに返しているので、質問をあるプロセスから別のプロセスにコピーするのはまったくの無駄なのです。 これを完全に無視することで仕事を節約しています。 最終的なインターフェースがより自然になるので、回答はそこに残しています。 また、そうしたいときには魔法の8ボールをいじって、同じ質問には常に同じ回答をするようにもできますが、いまのところはこういったことはしません。
モジュールの残りの部分は、一般的なget_serverが何もしないときと同じです:
handle_cast(_Cast, State) ->
{noreply, State}.
handle_info(_Info, State) ->
{noreply, State}.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) ->
ok.
次に、より本格的な部分です。つまり、アプリケーションファイルとコールバックモジュールです。 まずは後者のコールバックモジュールである、 m8ball.erl です:
-module(m8ball).
-behaviour(application).
-export([start/2, stop/1]).
-export([ask/1]).
%%%%%%%%%%%%%%%%%
%%% CALLBACKS %%%
%%%%%%%%%%%%%%%%%
start(normal, []) ->
m8ball_sup:start_link().
stop(_State) ->
ok.
%%%%%%%%%%%%%%%%%
%%% INTERFACE %%%
%%%%%%%%%%%%%%%%%
ask(Question) ->
m8ball_server:ask(Question).
これは簡単ですね。 次に、これに紐付いた .app ファイルの m8ball.app です:
{application, m8ball,
[{vsn, "1.0.0"},
{description, "Answer vital questions"},
{modules, [m8ball, m8ball_sup, m8ball_server]},
{applications, [stdlib, kernel, crypto]},
{registered, [m8ball, m8ball_sup, m8ball_server]},
{mod, {m8ball, []}},
{env, [
{answers, {<<"Yes">>, <<"No">>, <<"Doubtful">>,
<<"I don't like your tone">>, <<"Of course">>,
<<"Of course not">>, <<"*backs away slowly and runs away*">>}}
]}
]}.
すべてのOTPアプリケーションと同様に、 stdlib と kernel に依存しています。またサーバ内のランダムシードを設定するために crypto に依存しています。 回答はすべてタプル内にあることに留意してください。サーバ内で必要になる回答用のタプルはパターンマッチされます。 この場合、回答はすべてバイナリですが、文字列の書式はあまり関係ありません。リストでもちゃんと動作します。
30.4. アプリケーションを分散化する¶
これまでは、すべて完全に通常のOTPアプリケーションと同様でした。 分散OTPアプリケーションとして動作させるためにファイルに加える変更はほとんどありません。 事実、先ほどの m8ball.erl モジュールに、たった1つ関数節を加えるだけです:
%%%%%%%%%%%%%%%%%
%%% CALLBACKS %%%
%%%%%%%%%%%%%%%%%
start(normal, []) ->
m8ball_sup:start_link();
start({takeover, _OtherNode}, []) ->
m8ball_sup:start_link().
より重要なノードがバックアップノードから引き継いだときに {takeover, OtherNode} 引数が start/2 に渡されてます。 魔法の8ボールアプリケーションの場合では、特に何も変更することなく、同時にスーパバイザを起動するだけです。
コードを再コンパイルして、ほぼ準備完了です。 しかしちょっと待って下さい。どのようにどのノードがメインでどのノードがバックアップかを定義するのでしょうか。 答えは設定ファイルにあります。 システムには3つのノード( a 、 b 、 c )があるので、3つの設定ファイルが必要になります。(これらを a.config 、 b.config 、 c.config と命名して、アプリケーションディレクトリ内の config/ に置きます。)
[{kernel,
[{distributed, [{m8ball,
5000,
[a@ferdmbp, {b@ferdmbp, c@ferdmbp}]}]},
{sync_nodes_mandatory, [b@ferdmbp, c@ferdmbp]},
{sync_nodes_timeout, 30000}
]}].
[{kernel,
[{distributed, [{m8ball,
5000,
[a@ferdmbp, {b@ferdmbp, c@ferdmbp}]}]},
{sync_nodes_mandatory, [a@ferdmbp, c@ferdmbp]},
{sync_nodes_timeout, 30000}
]}].
[{kernel,
[{distributed, [{m8ball,
5000,
[a@ferdmbp, {b@ferdmbp, c@ferdmbp}]}]},
{sync_nodes_mandatory, [a@ferdmbp, b@ferdmbp]},
{sync_nodes_timeout, 30000}
]}].
一般的な構造は常に同じです:
[{kernel,
[{distributed, [{AppName,
TimeOutBeforeRestart,
NodeList}]},
{sync_nodes_mandatory, NecessaryNodes},
{sync_nodes_optional, OptionalNodes},
{sync_nodes_timeout, MaxTime}
]}].
変数 NodeList は通常 [A, B, C, D] のような形式です。この場合、 A をメインにするときには、 B が1つ目のバックアップ、 C がその次のバックアップという具合になります。 他の構文も可能で、 [A, {B, C}, D] というリストを渡すと、 A はやはりメインノードで、 B と C は同等のセカンダリバックアップで、さらの他のノードが、と続きます。

sync_nodes_mandatory タプルは sync_nodes_timeout と一緒に動作します。 分散仮想マシンを、それ用に設定された値で起動するとき、すべての必須ノードが起動しロックされるまで、ロックされ続けます。 そのあと、必須ノードは同期され、システムが稼働します。 もしすべてのノードが立ち上がるのに MaxTime 以上の時間がかかったら、稼働する前に全ノードがクラッシュします。
他にも多くのオプションが設定可能なので、さらに深く知りたい場合は kernelアプリケーションのドキュメント を参照してください。
さて、 m8ball アプリケーションを動かしてみましょう。 3つのVMすべてを起動させるのに30秒では足りないと思った場合には、 sync_nodes_timeout を好きなだけ増やしましょう。 それから、3つのVMを起動します:
$ erl -sname a -config config/a -pa ebin/
$ erl -sname b -config config/b -pa ebin/
$ erl -sname c -config config/c -pa ebin/
3つ目のVMを起動するとき、すべてが同時にロック解除されます。 3つのVMすべてにいって、次々と crypto と m8ball を applications:start(AppName) の両方を起動しましょう。
それから、接続したノードであらばどれでも魔法の8ボールを呼び出すことができます:
(a@ferdmbp)3> m8ball:ask("If I crash, will I have a second life?").
<<"I don't like your tone">>
(a@ferdmbp)4> m8ball:ask("If I crash, will I have a second life, please?").
<<"Of Course">>
(c@ferdmbp)3> m8ball:ask("Am I ever gonna be good at Erlang?").
<<"Doubtful">>
やる気が出ますね。 今の状況を確認するために、 applications:which_applications() を全ノードで呼び出してみます。 ノード a だけが m8ball を動かしていると思います:
(b@ferdmbp)3> application:which_applications().
[{crypto,"CRYPTO version 2","2.1"},
{stdlib,"ERTS CXC 138 10","1.18"},
{kernel,"ERTS CXC 138 10","2.15"}]
(a@ferdmbp)5> application:which_applications().
[{m8ball,"Answer vital questions","1.0.0"},
{crypto,"CRYPTO version 2","2.1"},
{stdlib,"ERTS CXC 138 10","1.18"},
{kernel,"ERTS CXC 138 10","2.15"}]
この場合、 c ノードは b ノードとおなじものを表示するでしょう。 ここで、もし a ノードを殺すと(Erlnagシェルを起動させている端末を無理矢理閉じるだけです)、アプリケーションは当然もうそこでは稼働していません。 代わりにどこに行ったか見てみましょう:
(c@ferdmbp)4> application:which_applications().
[{crypto,"CRYPTO version 2","2.1"},
{stdlib,"ERTS CXC 138 10","1.18"},
{kernel,"ERTS CXC 138 10","2.15"}]
(c@ferdmbp)5> m8ball:ask("where are you?!").
<<"I don't like your tone">>
b が優先順位では上なので、予想通りです。 5秒後(タイムアウトを5000ミリ秒に設定しました)、 b はアプリケーション稼働中だと表示するでしょう:
(b@ferdmbp)4> application:which_applications().
[{m8ball,"Answer vital questions","1.0.0"},
{crypto,"CRYPTO version 2","2.1"},
{stdlib,"ERTS CXC 138 10","1.18"},
{kernel,"ERTS CXC 138 10","2.15"}]
依然として、アプリケーションは順調に動いています。 では、先ほど a を取り除いたときとと同じように b を乱暴に殺してみます。 すると c は5秒後にアプリケーションを稼働させます:
(c@ferdmbp)6> application:which_applications().
[{m8ball,"Answer vital questions","1.0.0"},
{crypto,"CRYPTO version 2","2.1"},
{stdlib,"ERTS CXC 138 10","1.18"},
{kernel,"ERTS CXC 138 10","2.15"}]
最初に行ったようにノード a を再起動すると、ハングします。 設定ファイルでは、 b に a のバックアップとして動作するように明記しました。 もし、このような動作を期待しないのであれば、たとえば b か c をオプションにしておく必要がるでしょう。 こうすれば a と b の両方が起動したとき、アプリケーションは自動で戻ってきます。お分かりになるでしょうか。
(a@ferdmbp)4> application:which_applications().
[{crypto,"CRYPTO version 2","2.1"},
{stdlib,"ERTS CXC 138 10","1.18"},
{kernel,"ERTS CXC 138 10","2.15"}]
(a@ferdmbp)5> m8ball:ask("is the app gonna move here?").
<<"Of course not">>
あー、これはダメだ。 この機構がうまく動作するためのポイントは、アプリケーションがノードの起動手順の一部として起動する必要があるということです。 たとえば、うまく動作させるには次のように出来るでしょう:
erl -sname a -config config/a -pa ebin -eval 'application:start(crypto), application:start(m8ball)'
...
(a@ferdmbp)1> application:which_applications().
[{m8ball,"Answer vital questions","1.0.0"},
{crypto,"CRYPTO version 2","2.1"},
{stdlib,"ERTS CXC 138 10","1.18"},
{kernel,"ERTS CXC 138 10","2.15"}]
そして c 側では:
=INFO REPORT==== 8-Jan-2012::19:24:27 ===
application: m8ball
exited: stopped
type: temporary
これは -eval オプションがVMの起動手順の一部として評価されたからです。 明らかに、うまく設定するのであればリリースを使ったほうが綺麗にできますが、その場合はこれまでやってきたことをすべて合わせなければいけないので、例を作るのはかなり面倒になります。
一般的なこととして、分散OTPアプリケーションは、システムに必要な部品がすべて適切な位置に確実にあるようにするリリースを使ったときに、最もうまく動作する、ということを覚えておいてください。
先に述べたように、多くのアプリケーションにおいて(魔法の8ボールも含まれています)、ときどき、アプリケーションを1箇所だけで稼働させるよりも、多くのインスタンスを1度に稼働させてデータを同期するほうが単純になります。 一旦設計が決まったら、それをスケールさせるのも単純です。 フェイルオーバー機構やテイクオーバー機構が必要な場合には、分散OTPアプリケーションがそれを満たしてくれるでしょう。