12. 並列性へのヒッチハイク・ガイド¶
流行遅れとなった21世紀の初頭の未知の僻地のはるか向こうに人知の欠片があった。
この人知の部分集合の中には、まったく重要でない小さな原理がありますが、たとえばフォン・ノイマン型アーキテクチャhああまりにも原始的すぎて、まだ逆ポーランド記法計算機のほうがずっといいアイデアとして認識されています。
この原理には問題があります。あるいはありました。それはこのような問題です:その原理を勉強している大抵の人間はとても長い時間を並行ソフトウェアを書くことに費やすことにうんざりしています。 この問題には多くの解決策が提案されていますが、ほとんどがロックやMutexなどと呼ばれる小さな理論の数々を扱うことに終始しています。 これらの理論は、全体として並列性を必要とする論理の各小さい部品ではなかったので追加されました。
そしてまだ問題は残っています。多くの人は知識が乏しく、たいていの人は悲惨と言ったほうがいい状況でした。たとえ彼らは逆ポーランド記法を使っているほどの人ではあってもその状況です。
多くの場合には並列性をプログラミング言語に追加しようとすることに大きな間違いがあり、プログラムでは初期スレッドを残すべきでなかったという意見が多いです。
Note
銀河ヒッチハイク・ガイド (原題:The Hitchhicker’s Guide to the Galaxy)をパロディにするのは楽しいです。 もし読んだことがなければ是非読んでみてください。 とてもいいですよ!
12.1. パニックになるな!¶
やあ。今日(というかあなたがこれを読んでいる日。ぶっちゃけ明日でもいい)、あなたに並列Erlangのについて教えましょう。 たぶん以前に並列性について読んだり、実際にやってみたりしたことがあるでしょう。 もしかするとマルチコアプログラミングが急に人気が出てきたことに興味も持っていることでしょう。 とにかく、あなたがこの本を読んでいるのは今日話題になっている並列性について話しているから、という可能性はかなり高いです。

しかし警告しておきます。この章のほとんどは理論の話です。もし頭痛があって、プログラミング言語の歴史が好きではなく、単純にプログラムがほしいという人は、 この章の最後 まで読み飛ばすか、次の章まで読み飛ばしてしまいましょう。(より実践的な知識が書いてあります)
すでにこの本の最初でErlangの並列性は、人々が手紙だけでやりとりをしているという例えを使って、メッセージパッシングとアクターモデルに基づいていると説明しました。 後でより詳細に説明しますが、まず何より先に、並列性と並行性の違いを定義しましょう。
多くの場面ではこれら2つの単語は同じ概念をさして位亜M素。Erlangではこの2つはよく違った意味として使われます。 多くのErlang使いにとっては、並列性はたくさんのアクターがそれぞれ独立して動いているという状態を言っています。ただしすべてが同時に走っているありません。 並行性はアクターをまったく同時に走らせることを言います。この定義が計算機科学の他の分野で同じような定義がされているようには思えませんが、この本ではそのような定義で使います。 もし他の本や人が同じ用語を違った意味で使っていても驚かないでください。
Erlangには初めから並列性が備わっていました。すべてがシングルコアプロセッサで処理されていた1980年代でさえです。 各Erlangプロセスは、マルチコアシステムができる前のデスクトップアプリケーションののように、それぞれ決まった実行時間動作します。
それでも並行性は使えます。必要なものはコードを走らせることができて、1つ目のコンピュータとやりとりができる2つ目のコンピュータです。 この設定ではたった2つのアクターしか並行して動作できません。近年ではマルチコアシステムのおかげで1つのコンピュータで並行性を実現できるようになりました。(産業用チップでは何十ものコアを持っているものもあります)そしてErlangではこの能力を極限まで使うことができます。
Don’t drink too much Kool-Aid:
並列性と並行性の区分はきちんと付けておいたほうがいいです。 なぜなら多くのプログラマはErlangは実際にそうなる以前からマルチコアコンピュータに対する準備が出来ていたと思っています。 Erlangは2000年代中期の真に対照的なマルチプロセスにのみ適用できて、ほとんどの実装が2009年のR13Bのリリースできちんと動くようにできました。 それ以前は、SMPはパフォーマンスロスを避けるためにしばしば無効にされてきました。 マルチコアコンピュータでSMPを使わずに並行性を得るためには、代わりに多くのVMインスタンスを立ち上げる必要がありました。
面白いことに、Erlangの並列性は孤立したプロセスで行われるので、言語レベルでは全く概念的な変化を及ぼさず、言語に真の並行性をもたらすには至りませんでした。 すべての変化はユーザに意識させることなくVMで行われ、プログラマの目の届かないところに行きました。
12.2. 並列性の概念¶

かつて、Erlangの言語としての開発は、Erlang自体で書かれた電話交換機で仕事しているエンジニアからの頻繁なフィードバックにより、驚くべき速さで行われました。 こういったやりとりが、彼らの直面した問題をモデルを作るのに、プロセスベースの並列性と非同期メッセージパッシングがいい方法だと証明しました。 さらに、通信業界ではErlangが現れるより前にすでに並列性を目指す文化がありました。 この文化はPLEXというEricsson社がかつて作った言語や、AXEというPLEXで実装された交換機から受け継いでいます。 Erlangはこの傾向を追従して、過去のツールでできたことをより改良しようとしました。
Erlangは良いと思われる以前に満たすべき要求が少しありました。 主なものとしては、スケールアップできることと数多くの交換機上の何千ものユーザをサポートすることでした。 そして高い信頼性を得るために―決して止まらないコードが求められました。
12.2.1. スケーラビリティ¶
まず最初にスケーリングに注目します。いくつかの特性はスケーラビリティを得るために必要だと思われます。 ユーザはある特定のイベントに対して反応しただけのプロセスを表している(つまり、呼び出しを受ける、電話を切るなど)ので、理想的なシステムは小さい計算をし、イベントが来るたびにとても素早く切り替わるプロセスをサポートするでしょう。 効率的にするために、プロセスの立ち上がりをとても速くして、破壊をおっても速くして、切り替えをとても速くできるようにするのは道理にかなっています。 これを達成するためには、プロセスを軽量にすることが必須でした。また、プロセスプールのようなもの(仕事を分散させるための決まった数のプロセス)を持ちたくなかった、ということからも必須でした。 代わりに、必要なだけ多くのプロセスを使えるようにプログラムをデザインするのをたやすくしました。
スケーラビリティに関する他の重要な点は、ハードウェアの限界を回避することができることでしょう。 これには2つの方法があります。ハードウェアを良くするか、ハードウェアを追加するかです。 最初の選択肢はあるところまでは有効で、それ以降は考えられないくらい高価になります。(つまり、スパコンを買うということです) 2番目の選択肢は通常安価で、処理をするコンピュータを追加する必要があります。 言語の一部としてこの機能があるということは分散をするときに便利です。
いずれにせよ、小さなプロセスにするということは、電話通信アプリケーションは信頼性がとても高くないといけないので、プロセスに共有メモリを使うことを禁じるのが最もすっきりするということになりました。 共有メモリはプロセスがクラッシュした後に変な状態を残す原因になったり(特に異なったノード間で共有されたデータなど)、面倒な状況に成り得ました。 代わりに、プロセスはメッセージを送ることでやり取りすべきで、そのときはすべてのデータはコピーされます。 これは速度の低下にはつながりますが、安全です。
12.2.2. フォールトトレランス¶
このことが、Erlangの2番目の要件につながってきます: 信頼性です。 Erlangを最初に書く人は常に障害はよくあることだということを念頭においています。 バグを防ごうとあらゆることをやってみても、たいていの場合は防ぎきれずバグが残ります。 結果としてバグが起きなかったとしても、ハードウェア障害は避けられません。 こういったことから、エラーや障害をすべて防ごうとするのではなくて,それが起きたときにうまく対処する方法をさがそう、というのがアイデアです。
複数のプロセスがメッセージパッシングをするというアプローチはいいアイデアだということがわかりました。 なぜなら、エラー処理が比較的簡単に移植できるからです。 軽量プロセス(素早く再起動やシャットダウンができる)を例にとってみましょう。 大規模ソフトウェアシステムにおけるダウンタイムの主な原因は断続的あるいは一時的なバグでした。( ソース ) それから、データを破損するようなエラーはシステムの障害がある部分をできるだけ早く殺して、システムの他の部分にエラーや悪いデータを伝搬させないようにすべきです。 もう一つのコンセプトとして、システムを終了させるにはいくつもの方法があって、その2つを挙げるとクリーンシャットダウンとクラッシュ(予期しないエラーで終了する)があります。
最悪のケースは、言うまでもなくクラッシュすることです。安全な解決策としてはすべてのクラッシュをクリーンなシャットダウンと同様にすることです:これは共有しない単独アサイン(プロセスのメモリを独立させる)や、ロックを避けたり(ロックはクラッシュ時にロックが解除されないままになって、他のプロセスがデータにアクセスできないままになったり、データが一貫性を保てない状態にしてしまう)など、他にもたくさんのことで達成されます。これ以上は触れませんが、とにかくすべてErlangのデザインの一部です。 こういったことから、データがおかしくなったり、一時的なバグを回避するためにできるだけ早くプロセスを殺す、というのがErlangでの理想的な解決策になります。 軽量プロセスはこの点において重要な要素です。これ以上のエラー処理機構もプロセスが他のプロセスを歌詞することが出来るように言語の一部( エラーとプロセス で紹介されています)として実装されています。 これによっていつプロセスが死んだかを知って、死んだ時に何をするか決めることが出来ます。
クラッシュの際にプロセスを素早くリスタートさせることで十分対応できるというのがわかったとして、次に問題になるのはハードウェア障害です。誰かが稼働中のコンピュータを蹴り飛ばした時にプログラムが確実に動作するようにするにはどうしたらいいでしょうか。 誰かが来たのを知るためにレーザー検知器を置いたり、そもそもこないようにサボテンをいい感じに置いたり、というような素敵な防御システムはある程度は役にはたちますが、それも永遠に続くわけではありません。 解決するヒントしては、単純にプログラムを同時に2つ以上のコンピュータで稼動させることです。これはいずれにせよスケールするときに必要な機能です。 これはメッセージパッシング以外にやりとりをするチャンネルがない独立プロセスのもうひとつの利点です。 これでプロセスがローカルにあろうが違うコンピュータ上にあろうが関係なく同様に扱うことが出来て、プログラマに取ってかなり透過的な形で分散をすることでフォールトトレランスに出来ます。
分散されるということは、どうやってプロセスがお互いにやり取りするかという問題に直結します。 分散における最も大きなハードルは、関数呼び出しをしたときにノード(リモートコンピュータ)が存在したからといって、呼び出しを転送している間ちゃんとノードが存在しているか、あるいはちゃんと呼び出せたかすら分からないということです。 だれかがケーブルにつまずいたり、マシンのケーブルを引っこ抜いたりしたらアプリケーションがハングしたままになるでしょう。あるいはマシンを壊してしまうかもしれません。そうなったときに誰がそれを知ることができるでしょうか。
そして、非同期メッセージパッシングがこれまた良いデザインだということがわかりました。 非同期メッセージを持ったプロセスモデルでは、メッセージは1つのプロセスから2つ目のプロセスにむけて送信されて、読み取られるまでは受け取るプロセスのメールボックス内に保存されます。 受け取るプロセスが存在するかどうかを確認するより先にメッセージが送られるのは、確認することが意味が無いことだという点に触れておかなければいけません。 前の段落にあるように、メッセージが送信されてから受け取られるまでの間にプロセスがクラッシュしたかどうかを知ることは出来ません。 そして、メッセージが受け取られたとして、ちゃんと処理されたかを知ることは出来ないし、またそれ以前に受け取るプロセスが死んでしまったかもわかりません。 非同期メッセージはリモート関数呼び出しを安全に行うことが出来ます。なぜなら何が起きるか推測することが全くないからです。 プログラマだけが知ることができるのです。メッセージちゃんと届いたか確認したい場合は、元のプロセスに2つ目のメッセージを送り返さないといけません。 このメッセージも同様に安全に関数呼び出しが出来ます。そしてこの原理に基づいて、どんなプログラムやライブラリを書いていても安全に関数呼び出しが出来ます。
12.2.3. 実装¶
はい、これで、Erlangでは軽量プロセスと非同期メッセージパッシングというアプローチが取られることが決まりました。 ではどうやってこれを動作させましょう?まず、なにより先に、プロセスを扱うときにOSは信用できません。 OSがプロセスを扱うときにいくつもの異なった方法があって、そのパフォーマンスは多岐にわたります。 すべてとは言えないとしても多くの場合は、標準のErlangアプリケーションで必要としていることと比べると遅すぎたり重すぎたりします。 こういったことを仮想マシンの中で行うことで、Erlangで実装している人は最適化と信頼性を制御できます。 最近では、Erlangのプロセスは300語程度のメモリを持ち、起動はマイクロ秒単位で出来ます。 – これは今日のメジャーOSで出来ることではありません。
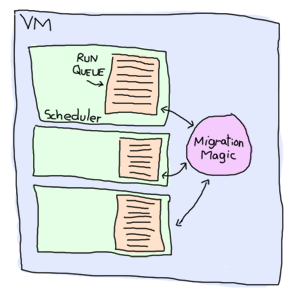
プログラム内で生成出来る、この強力なプロセスを扱うために、VMはコア1つに対してスケジューラとして1つのスレッドを起動します。 このスケジューラはそれぞれ実行キュー、つまりErlangプロセスのリストを持っていて、そのリストに対して一定時間の処理を行います。 もし1つのスケジューラに対して、実行キューにあるタスクが多すぎた場合には、その中のいくつかは他のスレッドに移されます。 これはつまり、各Erlang VMは負荷分散の面倒を見ていて、プログラマはその点は何も考えなくていいということです。 他にもいくつかの最適化があります。たとえば過負荷なプロセスに対して遅れるメッセージの量が制限して、負荷を制限したり分散したりしています。
大変なことはすべてErlang VMにあって、あなたのために管理されています。これこそ、Erlangが並列処理を用意にしているものなのです。 並列化するということは2つ目のコアを追加すれば速さが2倍になり、さらの4コア追加すれば4倍分速くなるということです。わかありますね? このような、速度の向上がコア数/プロセッサ数に対応している現象をリニアスケールと言います。(下のグラフを見てください) 実生活では、ただより高いものはありません。(えっと、お葬式ではありますが、それでも誰かが何処かしらでお金を払わなければなりません。)
12.3. すべてが線形にスケールするわけではない¶
線形のスケールを得る事の難しさは言語によるものではなく、むしろ解決しようとしてる問題の性質に依存します。 耳にたこが出来るほど言われていますが、うまくスケールする問題は並行処理なものです。 インターネットでこれぞ並行処理の問題を探すと、おそらくレイトレーシング(3次元イメージを作る方法)、暗号化での総当り攻撃、天気予報のような例が見つかると思います。
時々、IRC、フォーラム、MLに現れてErlangでそういう問題を解くことができるかとかGPUに関する問題に使えるか聞く人がいます。 その答えは常に「いいえ」です。理由は比較的簡単です:こういった問題は通常データの分解を伴う数値計算に終始するからです。 Erlangはこういう分野が不得意です。
Erlangでよく言われている並行処理の問題は高次元での話です。 通常、こういった問題はチャットサーバ、電話のスイッチ、 Webサーバ、メッセージキュー、Webクローラ、あるいは処理が論理的に個別なエンティティ(アクターと、あと他に何かありましたっけ?)で表されるアプリケーションなどの概念を扱わなければいけません。 こういった問題はほぼ線形のスケールで効果的に解決できます。
多くの問題ではそういうスケールの性質は必要とされてません。 事実、1つ操作のシーケンスが存在していればそれで事足りてしまいます。 並行の問題はこのシーケンスで一番遅い部分にしか関係してきません。 こういった現象の例はモールにいったときに見受けられます。 何百人も同時に買い物が出来て、お互いが干渉することはほぼありません。 そして支払いの時に、会計が処理できる人数よりも多くの人が並んでしまった場合、すぐに行列が出来ます。
お客さん一人一人に対応するまで会計を増やすことができますが、今度はお客さんそれぞれにドアが必要になります。 なぜならお客さんは一度にモールに入ったり出たりできるわけではないからです。
他の方法を考えて、お客さんが自分の好きな商品を並行して選ぶことができたとして、お店の中で一人だろうと何千人いようと基本的に十分な時間を掛けて買い物をしたとしても、それでもなおお金を払うため待たなければなりません。 それゆえ買い物の時間は列に並んでお金を払う時間よりも決して短くなることはないのです。
この原理を一般化したものがアムダールの法則(Amdahl’s Law)と呼ばれるものです。 これはシステムが並行化したときにどれくらい高速化出来るか、そしてどのように高速化するかを示しています。
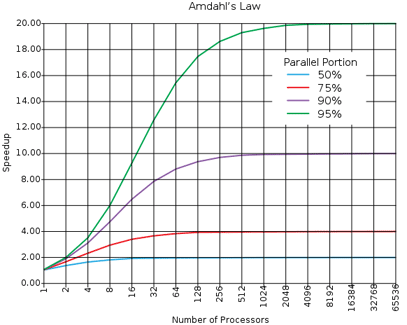
アムダールの法則によれば、50%並行にしたコードはそうする前よりも2倍以上は速くはなりえず、95%並行にしたものは十分なプロセッサがあれば理論上は20倍速くなります。 このグラフで面白いのは、最初あまり並行化されていないプログラムのシーケンシャルな部分を取り除いたときの高速化よりも、並行化がされて残りあと少しのシーケンシャルな部分を取り除いたときの高速化のほうが理論的にずっと大きな高速化になるということです。
Don’t drink too much Kool-Aid:
並行化はすべての問題を解決するわけではありません。 状況によっては、並行化することでかえってアプリケーションを遅くしてしまいます。 これはプログラムが100%シーケンシャルだけどマルチプロセスは使っているというときに起きえます。
この例として最もよいのはリングベンチマークです。 リングベンチマークは何千ものプロセスがデータ片をぐるっと順番に回すテストです。 必要とあらば伝言ゲームを想像してみてください。このベンチマークではある瞬間はたった1つのプロセスだけが意味のある動作していますが、Erlang VMは複数コアに負荷を分散しようとして、すべてのプロセスに一定の動作時間を与えます。
これは多くのよくあるハードウェア最適化に反していて、VMが無駄な時間を過ごすことになってしまいます。 純粋にシーケンシャルなアプリケーションが複数コア上だとシングルコア上で走らせた時よりずっと遅くなるのはこのせいです。 この場合、対称型マルチプロセスを無効にする($ erl -smp disable)のがいいでしょう。
12.4. さようなら、いままで魚をありがとう! (So long and thanks for all the fish!)¶
もちろん、この章はErlangの並列性に必要な3つの原則を提示するまで終わりません: 新しいプロセスをspawnする、メッセージを送る、メッセージを受け取るの3つです。 実際には本当に信頼のおけるアプリケーションを作るにはもっと多くの機構が必要ですが、いまのところはこれで十分です。
この問題をすっ飛ばしてきて、まだプロセスが一体何かという話もしていませんでした。 プロセスは単なる関数に過ぎません。プロセスは関数を実行して、実行が終わったら消えます。 技術的には、プロセスはいくつか状態を隠し持って(メッセージのメールボックスなど)いますが、関数という説明で今は十分です。
新しいプロセスを開始するために、Erlangでは spawn/1 という関数を使います。これは1つ関数を受け取って実行します:
1> F = fun() -> 2 + 2 end.
#Fun<erl_eval.20.67289768>
2> spawn(F).
<0.44.0>
spawn/1 の結果(<0.44.0>)は プロセス識別子 と呼ばれて、よく PID, Pid, pid と書かれます。 プロセス識別子はVM稼働中のある瞬間に存在している(あるいは存在していた)あらゆるプロセスを表す任意の値です。 この値はプロセスとやり取りするときのアドレスとして使われます。
ここで、関数 F の結果を見ることが出来ないということに気づいたと思います。pidを取得しただけです。 その理由はプロセスが何も返さないからです。
ではどうやったらFの結果を見ることができるでしょうか。方法は2つあります。簡単な方は結果を出力するだけです:
3> spawn(fun() -> io:format("~p~n",[2 + 2]) end).
4
<0.46.0>
これは本物のプログラムにおいては実用的ではありませんが、Erlangがプロセスをどのように処理するか見るときに役立ちます。 幸いにも io:format/2 は実験するには十分です。10個のプロセスをパッと起動して timer:sleep/1 関数の助けを借りてしばらく停止させます。 timer:sleep/1 は整数値 N を引数に取って、続きのコードを実行する前に N ミリ秒停止します。 遅延の後、プロセス内の値が出力されます。
4> G = fun(X) -> timer:sleep(10), io:format("~p~n", [X]) end.
#Fun<erl_eval.6.13229925>
5> [spawn(fun() -> G(X) end) || X <- lists:seq(1,10)].
[<0.273.0>,<0.274.0>,<0.275.0>,<0.276.0>,<0.277.0>,
<0.278.0>,<0.279.0>,<0.280.0>,<0.281.0>,<0.282.0>]
2
1
4
3
5
8
7
6
10
9
順番がよくわかりませんね。ようこそ並行の世界へ。このような順番になった理由は、プロセスが同時に走っていて、もはやイベントの順番は保証されないからです。 またそうなる理由はErlang VMが時間を効率的に使えるように、どのプロセスを実行するかを決めるのに多くの処理を行っているからです。 多くのErlang製サービスがプロセスとして実装されていてます。あなたがタイプしているシェルもその一つです。 プロセスはシステムとうまく調和しなければならず、これが順番がおかしくなる原因です。
Note
結果は対称型マルチプロセスサポートが有効になっていても無効になっていても同様になります。 $ erl -smp disable でErlang VMを起動するだけでそれを確認出来ます。
もしErlang VMが対称性マルチプロセスサポートで起動してるかどうかを確認するには、新しいVMをオプションなしで起動して、最初の行になんと書いてあるか見れば確認出来ます。 もし [smp:2:2] [rq:2] という文字があれば、SMPサポートありで動作していて、2つの実行キュー( rq, スケジューラのこと)が2つのコア上で動作しています。 もし [rq:1] しか書いていなかったら、SMPサポートなしで動作しています。
知りたい方のために、 [smp:2:2] は2つのコアが使えて、2つのスケジューラがあるという意味です。 [rq:2] は2つの実行キューがアクティブだということを意味しています。 Erlangの以前のバージョンでしゃ、複数のスケジューラを持てたのですが、共有実行キューは1つだけでした。 R13Bからは実行キューはデフォルトではスケジューラにつき1つしかなく、これによって並行がよりうまく出来るようになりました。
シェル自体が通常のプロセスで実装されているということを証明するために、BIFの self/0 を使ってみましょう。 これは現在のプロセスのpidを返します:
6> self().
<0.41.0>
7> exit(self()).
** exception exit: <0.41.0>
8> self().
<0.285.0>
pidが変わったのは、プロセスが再起動されているからです。 これがどのように動作しているか、詳しいことは後ほどご紹介します。 今はとりあえず基本的なことを見ていきましょう。 今最も重要なことは、どうやってメッセージを送るかを知ることです。 誰もプロセス結果を出力することだけに終始して、他のプロセスに手動で値を入れるなんていうことはしたくないでしょう。 (少なくとも私はしたくないです)
メッセージパッシングに必要なプリミティブは演算子 ! で、これは bang シンボルとして知られています。 左辺にはpidをとり、右辺にはあらゆるErlang項をとります。 Erlang項はpidで表されるプロセスに送られます:
9> self() ! hello.
hello
メッセージはプロセスのメールボックスに置かれますが、まだ読まれまていません。 ここにある2番目の hello は送信の操作の返り値です。これはつまり、こんなふうにすれば同じメッセージをたくさんのプロセスに送ることができるということです:
10> self() ! self() ! double.
double
これは self() ! (self() ! double). と等価です。 プロセスのメールボックスについて注意しておくことは、メッセージは受信した順に保存されているということです。 メッセージは常に突っ込まれた順に読まれます。 再度言いますが、これは導入部で例に挙げた人々が手紙を書く例に少し似ています。
現在のメールボックスの中身を確認するのに、シェル内では flush() を使えます:
11> flush().
Shell got hello
Shell got double
Shell got double
ok
この関数は受け取ったメッセージを表示する単なるショートカットです。 つまりまだ結果を変数に束縛する方法は分かっていませんが、少なくともあるプロセスから他のプロセスにメッセージを送って、それが受け取られたか確認することは出来るようになりました。
誰も読まないメッセージを送ることは情緒不安定な詩を書くことほどしか役に立ちません。 つまり全く役に立ちません。なので、receive文を知る必要があるわけです。 長すぎるサンプルをシェルで実行するよりも、イルカについての短いプログラムを書いて、その方法を見てみましょう:
-module(dolphins).
-compile(export_all).
dolphin1() ->
receive
do_a_flip ->
io:format("How about no?~n");
fish ->
io:format("So long and thanks for all the fish!~n");
_ ->
io:format("Heh, we're smarter than you humans.~n")
end.
見てお分かりのとおり、 receive は構文的には case ... of に似ています。 事実、パターンは case と of の間の式ではなく、来たメッセージを変数に束縛する以外は、全く同じように動作します。 receive ではガードもできます:
receive
Pattern1 when Guard1 -> Expr1;
Pattern2 when Guard2 -> Expr2;
Pattern3 -> Expr3
end
これで上のモジュールをコンパイルして、実行して、イルカとのコミュニケーションを始められます:
11> c(dolphins).
{ok,dolphins}
12> Dolphin = spawn(dolphins, dolphin1, []).
<0.40.0>
13> Dolphin ! "oh, hello dolphin!".
Heh, we're smarter than you humans.
"oh, hello dolphin!"
14> Dolphin ! fish.
fish
15>
ここで、 spawn/3 を使った新しいspawnの方法を紹介します。 spawn/3 は1つの関数だけを引数に取るのではなく、モジュール、関数とその引数を引数に取ります。 関数が実行されたら、次のイベントが起こります:
- 関数はreceive文に当たります。プロセスのメールボックスが空だった場合、イルカはメッセージを取得するまで待機します。
- メッセージ “oh, hello dolphin!” を受け取ります。関数は do_a_flip に対してパターンマッチしようとします。これは失敗するので、パターン fish にパターンマッチしようとして、やはり失敗します。最終的に、メッセージはcatch-all節(_)まで行って、そこでマッチします。
- プロセスは “Heh, we’re smarter than you humans.” というメッセージを出力します。
私たちが送信した最初のメッセージが動作したら、2番目のメッセージはプロセス <0.40.0> から一切の反応を起こさないという点に注目してください。 これは関数が一度 “Heh, we’re smarter than you humans.” という出力をしたら、関数はそれでおしまいで、プロセスもそこで終わるということです。 イルカを再起動する必要があります。
8> f(Dolphin).
ok
9> Dolphin = spawn(dolphins, dolphin1, []).
<0.53.0>
10> Dolphin ! fish.
So long and thanks for all the fish!
fish
今度はfishというメッセージでちゃんと動作します。 io:format/2 を使うよりも、dolphinから返り値を受け取れる方が便利だとは思いませんか? もちろん、そうですよね?(なんで聞いているでしょうか) この章の最初の方で、プロセスがメッセージを受け取ったかどうかを知るには返り値を送るしか方法がないということに触れました。 これは郵便でも同じことです。誰かに手紙の返事をしてもらいたければ、住所を付け加えてあげる必要があります。 Erlang項では、プロセスのpidをタプルに詰めることで同様の事が出来ます。 メッセージは最終的に {Pid, Message} というような感じになります。 それでは早速この様なメッセージを受け付ける新しいdolphin関数を書いてみましょう:
dolphin2() ->
receive
{From, do_a_flip} ->
From ! "How about no?";
{From, fish} ->
From ! "So long and thanks for all the fish!";
_ ->
io:format("Heh, we're smarter than you humans.~n")
end.
見てお分かりの様に、 do_a_flip や fish をメッセージとして受けとるのではなく、 From という変数も必要になってきます。ここにプロセス識別子が入るわけです。
11> c(dolphins).
{ok,dolphins}
12> Dolphin2 = spawn(dolphins, dolphin2, []).
<0.65.0>
13> Dolphin2 ! {self(), do_a_flip}.
{<0.32.0>,do_a_flip}
14> flush().
Shell got "How about no?"
ok
ちゃんと動いている様に見えますね。送ったメッセージ(各メッセージに対して住所を付け加える必要があります)に対して返信を受け取る事が出来ますが、まだ各関数呼び出しに対して新しいプロセスを立ち上げる必要があります。 再起によってこの問題を解決できます。 プロセスが終了せずに、常にメッセージを受け取れる状態にしたいので、ただ関数呼び出しをする必要があるだけです。 これを実際にやってみたのが次の dolphin3/0 関数です:
dolphin3() ->
receive
{From, do_a_flip} ->
From ! "How about no?",
dolphin3();
{From, fish} ->
From ! "So long and thanks for all the fish!";
_ ->
io:format("Heh, we're smarter than you humans.~n"),
dolphin3()
end.
ここで、catch-all節と do_a_flip 節は両方共 dolphin/3 のおかげでループします。 これらのメッセージが送られ続ける限り、dolphinプロセスは無限ループします。 しかし、 fish メッセージを送った場合、プロセスは止まります:
15> Dolphin3 = spawn(dolphins, dolphin3, []).
<0.75.0>
16> Dolphin3 ! Dolphin3 ! {self(), do_a_flip}.
{<0.32.0>,do_a_flip}
17> flush().
Shell got "How about no?"
Shell got "How about no?"
ok
18> Dolphin3 ! {self(), unknown_message}.
Heh, we're smarter than you humans.
{<0.32.0>,unknown_message}
19> Dolphin3 ! Dolphin3 ! {self(), fish}.
{<0.32.0>,fish}
20> flush().
Shell got "So long and thanks for all the fish!"
ok
これは dolphins.erl に書いてあります。お分かりのとおり fish での呼び出しを除いては、すべてのメッセージに対して1度返信し、そのまま継続しるという期待した動作をします。 イルカは頭がいかれた人間のおかしな態度にうんざりして、永遠にそのままにしてくれるでしょう。

これでおしまいです。これがErlangの並列性において中心となるもののすべてです。 これまでにプロセスと基本的なメッセージパッシングを見てきました。 本当に便利で信頼のおけるプログラムを作るためにはもっと多くの概念があります。 それらのうちのいくつかは次の章で、そしてそれ以外も後続の章で触れます。