11. 一般的なデータ構造への小さな旅¶
11.1. 長くはかかりません、約束します!¶
おそらくもうErlangの関数型っぽい部分は十分理解されたと思いますし、もうたくさんのプログラムを問題なく読むことが出来るようになったでしょう。 しかし、前の章で関数型っぽく問題を解くことが出来るようになったとしても、まだ実際に使い物になるプログラムを書くにはすこし厳しいと思っています。 これは私が学んできた経験でそう感じるだけであって、あなたはうまくやれているというなら、おめでとうございます!
どちらにせよ、私が言いたいのはこれまでに多くのことを学んできました:基本的なデータ型、シェル、モジュールと関数の書き方(再帰も含め)、いくつかのコンパイルの方法、プログラムの制御フロー、例外処理、共通操作の抽象化などです。 またタプルやリスト、また不完全ながらも実装した二分木を使ってデータをどのように保存するかも見てきました。 ここまででまだ見ていないのはErlangの標準ライブラリでプログラマに提供されている他のデータ構造です。

11.2. レコード¶
何よりもまず、レコードはハックです。多かれ少なかれ、言語を補足するものであって、共有するには少々不便なところがあります。その点については後ほど触れます。 それでも小さなデータ構造があって、属性に名前を使って直接アクセス死たい時には十分役に立ちます。 Erlangのレコードそれ自体はまさにCの構造体のようなものです。(Cを知っていれば、のたとえですが)
レコードはモジュールの属性として次のように宣言されます:
-module(records).
-compile(export_all).
-record(robot, {name,
type=industrial,
hobbies,
details=[]}).
これで、4つのフィールドを持ったロボットを表すレコードを表現することができました: 名前(name), タイプ(type), 趣味(hobbies)そして詳細(details)です。 タイプと詳細にはそれぞれ industrial と [] というデフォルト値があります。 レコードを record モジュールの中でどのように宣言するか見てみましょう:
first_robot() ->
#robot{name="Mechatron",
type=handmade,
details=["Moved by a small man inside"]}.
コードを実行してみます:
1> c(records).
{ok,records}
2> records:first_robot().
{robot,"Mechatron",handmade,undefined,
["Moved by a small man inside"]
おっと!ここでハックです!Erlangレコードというのはタプル上の構文糖衣にすぎなかったんですね。 幸いにも、もっと良くする方法があります。Erlangシェルには rr(Module) というコマンドがあって、これでレコード定義をModuleから読み込むことができます:
3> rr(records).
[robot]
4> records:first_robot().
#robot{name = "Mechatron",type = handmade,
hobbies = undefined,
details = ["Moved by a small man inside"]}
おお!これでずいぶんレコードを扱いやすくなりました。 first_robot/0 では趣味(hobbies)フィールドを定義していなかったこと、そして趣味フィールドにはデフォルト値が宣言されていなかったことに気がつくでしょう。 Erlangはデフォルトでそういった値をundefinedに設定してくれます。
robot の定義で設定したデフォルトの動作を確認するために、次の関数をコンパイルしてみましょう:
car_factory(CorpName) ->
#robot{name=CorpName, hobbies="building cars"}.
実行してみます:
5> c(records).
{ok,records}
6> records:car_factory("Jokeswagen").
#robot{name = "Jokeswagen",type = industrial,
hobbies = "building cars",details = []}
これで車を作るような工業ロボット(industrial robot)を作ることができました。
Note
関数 rr() はモジュール名以外も引数に取ることが出来ます。ワイルドカード( rr("*") )や第2引数にどのレコードを読み込むかのリストを渡すことが出来ます。
他にもシェルの中でレコードを扱う関数があります: rd(Name, Definition) はレコードをモジュールの中で使われていたような -record(Name, Definition) と同様の方法で宣言することが出来ます。 rf() はすべてのレコードをアンロードするときに使えます。 rf(Name) や rf([Names]) で特定のレコード宣言を取り除くことが出来ます。
rl() を使ってコピー&ペースト出来るような形で、すべてのレコード定義を表示することが出来ます。 あるいは rl(Name) や rl([Names]) を使って特定のレコードだけを表示することも出来ます。
最後に、 rp(Term) を使って、タプルをレコードに変換することも出来ます。(定義があれば)
レコードを書くだけではあまり意味がありません。そこから値をとり出す方法が必要です。 基本的には2つの方法があります。1つ目は特別な「ドット構文」と呼ばれるものです。 ロボットのレコード定義が読み込まれたとします:
5> Crusher = #robot{name="Crusher", hobbies=["Crushing people","petting cats"]}.
#robot{name = "Crusher",type = industrial,
hobbies = ["Crushing people","petting cats"],
details = []}
6> Crusher#robot.hobbies.
["Crushing people","petting cats"]
あー、美しくない構文ですね。これはタプルとしてのレコードの性質です。これはある種コンパイラを騙してるだけなので、どのレコードどのレコードに定義されているかを表すキーワードを書いておかなければなりません。その結果が Crusher#robot.hobbies の #robot 部分です。悲しいですが、他に方法はないのです。さらに悪いことに、ネストしたレコードはかなり醜くなります:
7> NestedBot = #robot{details=#robot{name="erNest"}}.
#robot{name = undefined,type = industrial,
hobbies = undefined,
details = #robot{name = "erNest",type = industrial,
hobbies = undefined,details = []}}
8> (NestedBot#robot.details)#robot.name.
"erNest"
そうなんです、括弧は必須なんです。
Update
R14Aから、ネストしたレコードを括弧なしで呼び出すことが出来るようになりました。 上の NestedBot の例では NestedRobot#robot.details#robot.name と書いて同様の動作をするようになっています。
レコードがタプルに依存していることをもっと見るには、次の例を見てみましょう:
9> #robot.type.
3
これが出力しているのは、それが後ろにあるタプルのどの要素なのか、という事です。
レコードの欠点を補う特徴としては、関数の頭の中でパターンマッチやガードとして使うことができるという点です。 ファイルの先頭で次のように新しいレコードを宣言して、関数をその下に追加します:
-record(user, {id, name, group, age}).
%% use pattern matching to filter
admin_panel(#user{name=Name, group=admin}) ->
Name ++ " is allowed!";
admin_panel(#user{name=Name}) ->
Name ++ " is not allowed".
%% can extend user without problem
adult_section(U = #user{}) when U#user.age >= 18 ->
%% Show stuff that can't be written in such a text
allowed;
adult_section(_) ->
%% redirect to sesame street site
forbidden.
変数と任意のフィールドを束縛する構文は admin_panel/1 関数の中で示されています。(変数と一つ以上のフィールドを束縛することが出来ます) 重要なのは、 adult_section/1 関数はすべてのレコードを変数に束縛するために SomeVar = #some_record{} としなければいけないことです。あとはいつもどおりにコンパイルします:
10> c(records).
{ok,records}
11> rr(records).
[robot,user]
12> records:admin_panel(#user{id=1, name="ferd", group=admin, age=96}).
"ferd is allowed!"
13> records:admin_panel(#user{id=2, name="you", group=users, age=66}).
"you is not allowed"
14> records:adult_section(#user{id=21, name="Bill", group=users, age=72}).
allowed
15> records:adult_section(#user{id=22, name="Noah", group=users, age=13}).
forbidden
これで、関数を書いているときには、タプルのすべての構造をパターンマッチする必要はないことや、要素がいくつあるかさえ知らなくてよいことがわかります:必要なのはそれだけなので age や group だけパターンマッチさせればよく、ほかのすべての要素のことは忘れてしまって構いません。 これを普通のタプルでやろうとしたら、関数定義は function({record, _, _, ICareAboutThis, _, _) -> .... というようになります。 要素をタプルに追加しようと思ったらいつでも、他の誰かがそのタプルが使われている関数すべてを更新しに行かなければなりません。(おそらくそれでかなり怒るでしょう)
次の関数はレコードの更新方法を示しています(これが出来なかったらレコードは役立たずですよね):
repairman(Rob) ->
Details = Rob#robot.details,
NewRob = Rob#robot{details=["Repaired by repairman"|Details]},
{repaired, NewRob}.
そして:
16> c(records).
{ok,records}
17> records:repairman(#robot{name="Ulbert", hobbies=["trying to have feelings"]}).
{repaired,#robot{name = "Ulbert",type = industrial,
hobbies = ["trying to have feelings"],
details = ["Repaired by repairman"]}}
これでロボットが直りました。ここでレコードを更新する構文はちょっと特別です。 ここではレコードを直接書き換えたように見えます( Rob#robot{Field=NewValue} )が、これはすべて erlang:setelement/3 関数を呼び出すためにコンパイラを騙すためのものです。
レコードについて最後にもう一つ。レコードはとても便利で、コードの重複にはイライラさせられるので、Erlangプログラマはしばしばヘッダファイルの助けを借りてレコードをモジュール内で共有します。 ErlangのヘッダファイルはCの同様のものとよくよく似ています: これはただのスニペットに過ぎず、はじめてモジュールに追加されたかのように書いてあります。 records.hrl という名前でファイルを開いて次のようにコードを書きます:
%% this is a .hrl (header) file.
-record(included, {some_field,
some_default = "yeah!",
unimaginative_name}).
これを records.erl に含めるために、モジュール内に次のコードを加えてみましょう:
-include("records.hrl").
そして、次の関数を試します:
included() -> #included{some_field="Some value"}.
これでいつもどおりに試せます。
18> c(records).
{ok,records}
19> rr(records).
[included,robot,user]
20> records:included().
#included{some_field = "Some value",some_default = "yeah!",
unimaginative_name = undefined}
すっげえ!これでレコードについてはおしまいです。醜いかもしれませんが、役には立つのです。 構文はは醜く、ただのハックで、コードのメンテナンス性を上げるには比較的重要です。

11.3. キーバリューストア¶
ちょっと前の章で二分木を実装してもらいました。その使い道はアドレス帳として使うためのキーバリューストアでした。 あのアドレス帳は全然使い物になりません: 削除したり、使い道あるものに変換も出来ません。 あれは再帰のデモとしてはよかったんですが、それ以上のなにものでもありません。 ようやくあるキーにひもづいたデータを保管するのに役立つたくさんのデータ構造とモジュールを紹介するときが来ました。 すべての関数がそれぞれ何を表すか定義するとかモジュールを端から見ていくとかそういうことはしません。 単純にドキュメントへのリンクを張るだけです。たとえば、私が「Erlangでのキーバリューストアを啓蒙する立場」的な何かだったとしましょう。 いい肩書きですね。なにか勲章が必要ですね。
少量のデータには、基本的には2つのデータ構造しか使えません。1つ目は proplist と呼ばれるものです。 proplistは [{Key,Value}] の形をしたタプルのリストです。これ以外の規則がないので変に思えるかもしれません。 実際規則が非常に緩いため、リストには真偽値や整数値、その他諸々好きなものを格納することができます。 しかし、ここではリストにキーと値のタプルを持たせるというアイデアに興味があるのでこのまま話を進めます。 proplistを扱うには、 proplists モジュールを使いましょう。 proplists:delete/2, proplists:get_value/2, proplists:get_all_values/2, proplists:lookup/2, proplists:lookup_all/2 といった関数があります。
ここでリストに追加や更新をする関数がないことに気が付くでしょう。 このことが、proplistがデータ構造としてどれだけ緩いかを示しています。 これらの機能を使うには、手動で要素を結合する([NewElement|OldList])か lists:keyreplace/4 のような関数を使います。 1つの小さなデータ構造に2つのモジュールを使うというのは、すっきりしないことではありますが、proplistの定義がとても緩いので、設定用のリストや与えられた要素の説明をするのによく使われます。 proplistは完全なデータ構造ではありません。オブジェクトや要素を持ったリストやタプルを扱うのに、もっと一般的なパターンがあります。 proplistモジュールはそのようなパターンのうちの一つにすぎません。
少量のデータに対して完全なキーバリューストアを使いたいなら、 orddict モジュールがまさに必要なものでしょう。 Orddict(順序付き辞書)はproplistを厳格にしたものです。キーは一意でなくてはならかったり、リスト全体として検索速度が平均でより速くなるように並びかえられていたりします。 CRUD用の一般的な関数として orddict:store/3, orddict:find/2 (キーが辞書内にあるかどうかわからない場合に使う), orddict:fetch/2 (辞書にキーがあるとわかっているとき), orddict:erase/2 があります。

orddictは一般的には75要素くらいまでは複雑さと効率の兼ね合いがとれています。( ベンチマーク を見てください) それ以上大きくなった場合には別のキーバリューストアに切り替えるべきです。
大量のデータを扱うのに、基本的に2つのキーバリュー構造/モジュールがあります。 dicts と gb_trees です。 辞書はorddictと同じインターフェースを持っています: dict:store/3, dict:find/2, dict:fetch/2, dict:erase/2 です。 そしてそのほかにもたくさんの関数があります。たとえば dict:map/2 や dict:fold/2 があります。 (データ構造全体を処理するのにとても便利です!)
一方で、一般的な平衡木はもっとずっと多くの関数があり、データ構造をどう使うかがわかるデータ制御が可能になっています。 gb_treesには基本的に2つのモードがあります:データ構造の入出力が分かるモード(これを「スマートモード」と呼んでいます)と、それがわからないモード(これを「ネイティブモード」と呼んでいます)があります。 ネイティブモードでは、 gb_trees:enter/2, gb_trees:lookup/2, gb_trees:delete_any/2 というような関数があります。 他にも gb_trees:insert/3, gb_trees:get/2, gb_trees:update/3, gb_trees:delete/2 というような賢い関数があります。 gb_trees:map/2 もあります。こいつはいつでも必要なときにいい働きをしてくれる関数です。
「ネイティブ」な関数が「スマート」なものに比べて不利な点は、gb_treesが平衡木なので、新しい要素を挿入する(あるいは削除する)ときにはいつでも木は平衡を保つような処理を擦る必要がでてくる鴨しれないということです。 この処理は時間とメモリを消費します。(たとえ必要ないとしても確認するためだけに必要です) 「スマート」関数はすべてキーが木の中に存在すると想定しています。これによって安全性チェックをスキップして、より速く結果を返すことが出来るようになります。
ではいつdictではなくgb_treesを使えばいいのでしょうか。それはすっきり決められるものではありません。 私が書いた keyval_benchmark.erl のベンチマークモジュールが示すところでは、 gb_trees と dicts は多くの点である程度似たパフォーマンスを出しています。 しかしながら、ベンチマークはdictsは読み取り速度が最も速く、一方でgb_treesは他の操作においていくらか速い傾向が見られました。 必要に応じてどちらが適切か判断してくださいね。
ああ、あとdictsにはfold関数があるけれど、gb_treesにはないということも覚えておいてください。 代わりにiterator関数があります。これは木の一部を返して、これから gb_trees:next(Iterator) を呼び出して順番的に次の値を取得することができます。 このことは、gb_treesの根元で一般的なfoldを呼び出すのではなく、自分で再帰関数を書いてそれを呼び出してやる必要がある、ということを意味しています。 一方で、gb_treesは gb_trees:smallest/1 と gb_trees:largest/1 を使って木から最小値と最大値の要素を素早く取り出すことが出来ます。
したがって、アプリケーションに必要なのは何がどのキーバリューストアを使うべきかを選ぶことにあると言えるでしょう。 どれだけのデータを保存しなければいけないか、何をしなければいけないか、何が重要でないかと行った異なる要因が絡んできます。 測定して、プロファイルをとって、ベンチマークをして、これらを確認するのです。
Note
異なる大きさのリソースを扱うために特別なキーバリューストアがいくつかあります。 このキーバリューストアは ETSテーブル, DETSテーブル, mnesiaデータベース です。 しかしながら、その使い方はマルチプロセスと分散の概念に強く結びついています。 このため、これらに関しては後ほど触れることにします。 ここでは興味をそそらせるために参考リンクだけ貼っておくので、興味のある人は見てみてください。
11.4. 配列¶
しかし、数値のキーしか持たないデータ構造が必要なコードの場合はどうでしょうか。 そういった状況のために、配列があります。配列を使うと、数字のインデックスを使って要素にアクセスができ、データ構造全体をfoldする際も、未定義のスロットは無視して処理することができます。
Don’t drink too much kool-aid:
Erlangの配列は、他の手続き型言語の配列とは逆に、一定時間での挿入や検索が出来ません。 これらは破壊的代入をサポートしている言語に比べると通常は遅く、Erlangでなされるプログラミングスタイルでは配列や行列と結びつける必要がなく、実際にはめったに使われないからです。
一般的に行列操作が必要なErlangプログラマや配列が必要なユーザは Ports と呼ばれる概念を使って、他の言語にロードをさせています。あるいは C-Nodes, Linked in drivers, NIFs といったものを使っています。(R13B03+での実験的なサポート)
配列はインデックスがない数少ないデータ構造の一つという点で変わっています。(タプルやリストとは逆です) 正規表現モジュールも同様です。ともに注意してください。
11.5. セットのセット¶
もし数学のクラスで集合論を勉強したことがあれば、セットで何が出来るか分かると思います。 もし勉強したことがなければ、気にしなくていいです。しかし言いたいのは、セットは一意な要素を持った集合で、そのそれぞれの要素は比較や何かの処理が出来るということです。 操作というのは例えばどの要素が2つの集合に存在するか、あるいは存在しないか、片方にしか、あるいはもう片方にしかないのかというようなことです。 もっと複雑な操作もあって、関係を定義したり、その関係に対する操作をしたり、その他様々なことが出来ます。 理論自体に踏み込むことはしませんので(再度いいますが、理論はこの本の範囲外です)、とりあえずこのようなものだとして進めます。
Erlangでセットを扱うモジュールは主に4つあります。最初は少し変に思うかもしれませんが、セットを作るのに「最適な」方法がないというのが開発者の間で同意がとれるということに気がつけば、それも納得できることでしょう。 4つのモジュールは ordsets, sets, gb_sets, sofs (セットの集合)です。
- ordsets
- ordsetsはソート済みリストとして実装されています。これは主に小さいセットに便利で、一番遅いセットけれどすべてのセットの中で一番単純で可読性の表現をしています。 ordsetsには標準関数として、 ordsets:new/0, ordsets:is_element/2, ordsets:add_element/2, ordsets:del_element/2, ordsets:union/1, ordsets:intersection/1, などがあります。
- sets
- set(モジュール名)はdictで使われた構造と似た構造の上に実装されています。 ordsetsと同じインターフェースを実装していますが、よりスケールします。 辞書と同様に、特に読み込み中心の操舵にはよいです。たとえばある要素がセット内にあるかどうかを確認するといった操作です。
- gb_sets
- gb_sets自身はgb_treesモジュールで使われたのと同様に、一般的な平衡木上に作成されています。 gb_setsはgb_treesがdictで実現していた事と同様のことをsetで実現しています。 実装は読み込み以外の操作が早くなっています。自前で多くの実装をしなければならないのも一緒です。 gb_setsはsetsやordsetsと同じインターフェースを実装している一方で、setsやordsetsはより多くの関数を持っています。 gb_treesのように、スマートとネイティブの対比があります。関数、イテレータ、小さい値や大きい値に大して速くアクセスできるか、などです。
- sofs
- セットのセット(sofs)はソート済みリストで実装されていて、内部ではメタデータを持ったタプル内のスタックになっています。 このモジュールはセット、ファミリー、強制セットタイプ間の関係をすべて制御したいときに使います。 これらは一意な要素の集合がほしい「だけ」というより数学的な概念が必要なときにだけ使うものです。
Don’t drink too much kool-aid:
セットの実装が複数あるのはなんだかいい事のように思えますが、実装の詳細はぼやっとしていて苦痛なものになるでしょう。 たとえばgb_sets, ordsets, sofsはすべて == 演算子を値の比較に使います。 もし数字で2と2.0があれば、同じものとみなされてしまうでしょう。
しかしながら、setsモジュールでは =:= 演算子を使います。 これはつまり、実装を必要に応じて好きなように切り替えられるというわけではないことを示しています。 正確な動作が1つ必要な状況があった時に、複数の実装があることの利点を失う場合があります。
いろんな意見があるとちょっと混乱してしまいますよね。 Erlang/OTPチームであり、 Wings3D のプログラマであるBjörn Gustavssonはほとんどの状況でgb_setsを使うことを提案しています。 orddictは自分が書いたコードで処理を明確に表現する必要があるときに使って、setsは =:= 演算子が必要なときにつかっています。(ソースは こちら )
どんな場合でも、キーバリューストアの時と同じように、最善策はベンチマークをとって、実装してるアプリケーションにどれが一番適しているか見ることです。
11.6. 有向グラフ¶
もうひとつここで触れておきたいデータ構造があります。(この章で触れたもの以外のデータ構造がないわけではりません) それが有向グラフです。セットに続き再び、 有向グラフ は既にこれに関連する数学的理論を知っている方だけでなく多くの読者が対象になっています。
Erlangでの有向グラフは2つのモデルとして実装されています。 digraph と digraph_utils です。 digraphモジュールは基本的に有向グラフの生成と変更ができるものです。具体的にはエッジと辺の操作、経路や周の検索などです。 一方でdigraph_utilsモジュールではグラフの誘導(後行順、先行順)、cycle, arborescences, 木のテスト、隣のノードの検索などを担っています。
有向グラフは集合論と深く結びついているので、’sofs’モジュールにはファミリーと有向グラフを相互変換する関数がいくつか(families_to_digraphs/2, digraphs_to_families/2 )あります。
11.7. キュー¶
queue モジュールは両端FIFO(First In, First Out)キューで実装されてます:
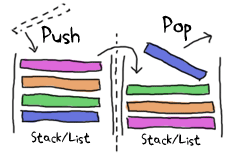
上図のように実装されていて(この場合だとスタック)、要素を前からでも後ろからで素早く追加できるようになっています。
queueモジュールは基本的に感覚的に3つのインターフェース(あるいはAPI)を持った関数群に分けられて、複雑さの度合いによってそれぞれ「オリジナルAPI」「拡張API」「Okasaki API」と呼ばれます。
- オリジナルAPI
- オリジナルAPIはキューの概念を元にした関数があります。 new/0 は空のキューの作成に、 in/2 は新しい要素の挿入に、 out/1 は要素の削除に使われます。他にもリストとキューの相互変換や特定の値がキューにあるかの検索をする関数などがあります。
- 拡張API
- 拡張APIは主に内部を見る機能と柔軟性が加わったものです。 たとえばキューの先頭の要素ポップするとことなく見るとか( get/1 や peek/1 を確認してください)、要素を中身を確認せずに削除するとか( drop/1 )です。 これらの関数はキューの概念においては本質的なものではないですが、とはいえ一般的には便利なものです。
- Okasaki API
- Okasaki APIはちょっと変わっています。これはChris Okasakiの Purely Functional Data Structures に由来しています。 APIは上に挙げた2つのAPIで使えるものと同様の操作ができるようになっていますが、関数名が逆向きに書いてあったりもして、全体としては比較的特有なものとなります。 このAPIを使いたいというのでなければ、これ以上説明して困らせないようにします。
来た順に並んでいるようなものが確実にほしい場合にキューを使いたくなってくるでしょう。 これまでの例では、リストをアキュムレータとして使って、その後それを逆順に並び変えていました。 すべての並びを一変に逆順に出来なくて、要素が頻繁に追加されるような状況では、queueモジュールがまさにほしいものだと思います。 (でも、最初にテストして、計測すべきですよ!いつもテストと計測をまずはじめにやってください!)
11.8. 小さな旅の終わりに¶
ここではErlangでのデータ構造の旅をしてきました。ここまで運転お疲れ様でした! もちろん、あといくつかご紹介できる、違う問題を解決できるデータ構造があります。 ここでは良く遭遇する、あるいはErlangの一般的な使い方をしているときに最大限の補助をしてくれるものを紹介しました。 標準ライブラリ や 拡張ライブラリ を眺めてみて、もっと多くの情報を見ることをお勧めします。
これで私たちの手続き型(関数型)Erlangへの旅は完了しました。おめでとうございます。 Erlangを始める多くの人が、並行性と並列性とそれ以外という見方をしてしまうのは知っていますし、理解できます。 それこそがErlangが本当に輝ける舞台だからです。監視ツリーや便利なエラー管理、分散、などなど。 私もこういった話題を書くまで、だいぶ辛抱してきましたので、読者の中には早く読みたくて我慢ならない人もいるでしょう。
しかし、Erlangの並行性の話をする前に関数型の部分をする方がよりわかりやすいと判断したので、このような進め方をしてきました。 その方が後の内容や新しい概念を理解しやすいのです。さあ、次に行きましょう!
