10. 関数型っぽく問題を解く¶
これでこれまでに飲み込んだErlangのエキスをもってすれば、実践的なことが出来るでしょう。 これからは何も新しいことは出てきませんが、どうやってこれまで見てきたものを使うかをお見せします。 この章での問題はMiranさんが書いたLearn You a Haskellから取ってきたものです。 好奇心旺盛な読者がお望みどおりErlang版とHaskell版の解答を比較できるよう、同じ解法を採用しました。 比較してみると、2つの言語での最終結果は構文の差異以外はほぼ一緒だと分かるでしょう。 これは一度関数型の概念を知れば、他の関数型言語へ移行するのは比較的簡単だからです。
10.1. 逆ポーランド記法計算機¶
多くの人が、算術式を演算子を数字の間に書く ((2 + 2) / 5) のような書き方で教わったと思います。 たいていの計算機ではこの書き方で式を入力しますし、おそらく学校で大事だと教わった書き方でしょう。 この記法は、演算子の優先順位を知っている必要がるという欠点があります。 掛け算と割り算は足し算と引き算よりも重要(優先順位が高い)というようなものです。
他の記法が存在します。これは前置表記法と呼ばれ、演算子がオペランドの前に来ます。 この記法では (2 + 2) / 5 は (/ (+ 2 2) 5) になります。 例えば + や / が常に2つの引数をとると決めれば、 (/ (+ 2 2) 5) は簡素に / + 2 2 5 と書けます。
しかしながら、代わりに逆ポーランド記法(以後RPN)に注目します。これは前置表記法の逆になります。 演算子はオペランドに続く形になります。今と同じ例を使うと 2 2 + 5 / となります。 他の例では 9 * 5 + 7 や 10 * 2 * (3 + 4) / 2 はそれぞれ 9 5 * 7 + や 10 2 * 3 4 + * 2 / となります。 この記法はメモリの消費が少ないので、初期の計算機によく使われていました。 事実、中には未だにRPN計算機を持ち歩いている人もいます。 これらについて書いていきましょう。
まずはじめに、どのようにRPNの式を読むか理解するのがいいでしょう。 その方法の一つとして、演算子を一つ一つ見つけていき、アリティごとにオペランドをまとめていきます:
10 4 3 + 2 * -
10 (4 3 +) 2 * -
10 ((4 3 +) 2 *) -
(10 ((4 3 +) 2 *) -)
(10 (7 2 *) -)
(10 14 -)
-4
しかしながら、コンピュータや計算機では、単純な方法としてはすべてのオペランドのスタックを見たままに作ることです。 式が 10 4 3 + 2 * - とあったとすると、最初のオペランドは10です。10を最初のスタックに積みます。 その後4がきます。なので4をスタックの先頭に押し込みます。3番目には3があります。 3もそのスタックに積みます。スタックはこのようになります:
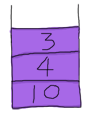
次の文字は+です。これはアリティを2つ持つ関数です。 これを使うために2つのオペランドをスタックから取ってきます。
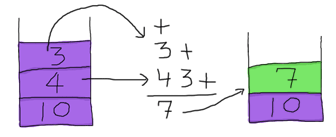
そこで7を持ってきて、スタックに戻します。(ウェー、こんなそのへんを漂ってた汚い数字を持っていたくない!) スタックはいま [7,10] となり残りの式は 2 * - となっています。 2を持ってきて、スタックの先頭に押し込みます。 それから * が見えます。これを動かすには2つのオペランドが必要です。 再度、2つのオペランドをスタックから持ってきます:
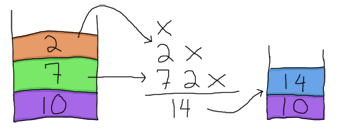
そして14をスタックに戻します。残りは - になります。これも2つのオペランドが必要です。ああ、素晴らしい幸運だ! スタックの中には2つのオペランドが残っています。それを使いましょう!
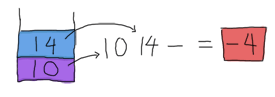
これで結果がでました。このスタックベースのアプローチは比較的誰にでも出来て、計算を始める前にパースをあまりする必要がないということが、なぜ昔の計算機がRPNを使うのがいいとしていたかの説明になると思います。 RPNを使う他の理由があるのですが、これは少々このガイドの範囲外なので、 Wikipediaの記事 を当たってみてください。
Erlangでこの方法を書くのは一度複雑な部分を書いてしまえばそんなに大変なことではありません。 大変なのは、結果を得るためにはどんあ手順が必要かを洗い出す部分だとわかりました。 そして私たちはいまそれをやってしまいました。巧妙です。 calc.erl を開いてください。
最初の懸念点はどのように式を表現すればいいのかということです。 単純にするために、文字列として入力するのがいいでしょう。 "10 4 3 + 2 * -" という具合です。 この文字列には空白があって、これは問題を解く上では必要ないのですが、簡単なトークナイザとして必要です。 その後、トークナイザに掛けるとリストの形式となった ["10", "4", "3", "+", "2", "*", "-"] が使えます。 関数 string:tokens/2 がちょうどそれをやってくれます:
1> string:tokens("10 4 3 + 2 * -", " ").
["10","4","3","+","2","*","-"]
これは式を表現するのにちょうど良いでしょう。次に定義しなければいけないのがスタックです。 どうやったら実現できるでしょうか?Erlangのリストはスタックのように動作することに気づいたかと思います。 cons演算子(|)を [Head|Tail] の形で使えば、 Head をスタック(この場合 Tail )の先頭に積むという動作が出来ます。 リストをスタックとして十分使えるでしょう。
式を読むために、問題を手で解いたときと同じことしなければいけません。 式から1つ1つ値を読んでいって、それが数字ならスタックに積んで、関数なら必要な値をスタックからポップして結果をプッシュします。 一般化するために、すべての式を1度だけループして、結果を積んでいきましょう。 これはfoldを使えば完璧のようですね!
関数 lists:foldl/3 が式の中のすべての演算子とオペランドに適用する関数を考えなければいけません。 この関数は、foldの中で実行されるので、2つの引数を取る必要があります。 最初の1つは式の要素、2つ目の引数はスタックになるでしょう。
これでコードを calc.erl ファイルに書き始められます。 すべてのループと式中の空白除去を行う関数を書きます:
-module(calc).
-export([rpn/1]).
rpn(L) when is_list(L) ->
[Res] = lists:foldl(fun rpn/2, [], string:tokens(L, " ")),
Res.
次に rpn/2 を実装します。式中の各演算子とオペランドはスタックの先頭に積まれるので、解かれた式の結果はスタック上に置かれます。 最後の値をユーザに返す前に取り出さなければいけません。 これが [Res] とパターンマッチして、 Res だけを返す理由です。
さあ、次は難しい部分です。 rpn/2 関数は渡されたすべての値に対してスタックを処理しなければいけません。 関数の先頭はおそらく rpn(Op,Stack) のようになるでしょう。 そして返り値は [NewVal|Stack] というようになるでしょう。 普通の数字を受け取ったら、操作は次のようになります:
rpn(X, Stack) -> [read(X)|Stack].
ここで read/1 は文字列を整数か浮動小数に変換する関数です。 悲しいことに、これをしてくれる組み込み関数がErlangにはありません。(整数だけか、浮動小数だけへの変換は出来ます) 私たちで追加しましょう:
read(N) ->
case string:to_float(N) of
{error,no_float} -> list_to_integer(N);
{F,_} -> F
end.
string:to_float/1 は “13.37” というような文字列を数字に変換します。 しかし、浮動小数として読み取れない場合は {error,no_float} が返ってきます。 そのときは、 list_to_integer/1 を代わりに使わなければいけません。
さて、 rpn/2 に戻りましょう。見つけた数字はすべてスタックに積まれます。 しかしながら、いまのパターンは何でもマッチしてしまうので( Pattern Matching を見てください)、演算子もスタックに積まれてしまいます。 これを避けるために、演算子の場合をこのパターンの前に書いていきます。 まずは足し算の場合です:
rpn("+", [N1,N2|S]) -> [N1+N2|S];
rpn(X, Stack) -> [read(X)|Stack].
これで "+" の文字列がきたらいつでも2つの数字( N1,N2 )をスタックの上から持ってきて、足し算をしてから結果をスタックの上に積みます。 これは手で問題を解いていたときと全く同じ論理です。 ちゃんとプログラムが動くかどうか見てみましょう:
1> c(calc).
{ok,calc}
2> calc:rpn("3 5 +").
8
3> calc:rpn("7 3 + 5 +").
15
あとは些細なものです。他の演算子を全部追加してやればいいだけです:
rpn("+", [N1,N2|S]) -> [N2+N1|S];
rpn("-", [N1,N2|S]) -> [N2-N1|S];
rpn("*", [N1,N2|S]) -> [N2*N1|S];
rpn("/", [N1,N2|S]) -> [N2/N1|S];
rpn("^", [N1,N2|S]) -> [math:pow(N2,N1)|S];
rpn("ln", [N|S]) -> [math:log(N)|S];
rpn("log10", [N|S]) -> [math:log10(N)|S];
rpn(X, Stack) -> [read(X)|Stack].
ログを取るなどの関数は1つしか引数を取らないのでスタックから1要素しかポップする必要がないことに気をつけてください。 読者のみなさんには ‘sum’ や ‘prod’ といった関数を演習として追加してもらいましょう。 それぞれ、それまでの要素のすべての和と積を出す関数です。 手助けとして、すでに渡しが実装したものが calc.erl にあります。
これがうまく動くか確認するために、とても簡単なユニットテストを書きましょう。 Erlangの = 演算子は assertion 関数として使うことが出来ます。 アサーションは予期しない値に当たったときにはクラッシュするべきです。これはまさに必要としていた機能です。 もちろん、Erlangには Common Test や EUnit のような、もっと高機能なテストフレームワークがあります。 これらはあとで見るとして、今は基本的な = 演算子で事足りるでしょう:
rpn_test() ->
5 = rpn("2 3 +"),
87 = rpn("90 3 -"),
-4 = rpn("10 4 3 + 2 * -"),
-2.0 = rpn("10 4 3 + 2 * - 2 /"),
ok = try
rpn("90 34 12 33 55 66 + * - +")
catch
error:{badmatch,[_|_]} -> ok
end,
4037 = rpn("90 34 12 33 55 66 + * - + -"),
8.0 = rpn("2 3 ^"),
true = math:sqrt(2) == rpn("2 0.5 ^"),
true = math:log(2.7) == rpn("2.7 ln"),
true = math:log10(2.7) == rpn("2.7 log10"),
50 = rpn("10 10 10 20 sum"),
10.0 = rpn("10 10 10 20 sum 5 /"),
1000.0 = rpn("10 10 20 0.5 prod"),
ok.
テスト関数はすべての操作を試みます。 もし例外が1つも出なかったら、テストは成功したと言えるでしょう。 最初の4つのテストは基本的な算術関数がちゃんと動いているか確認しています。 5番目の関数はまだ説明していない動作を確認します。 try ... catch は式がうまく動かないので、badmatchエラーを期待しています:
90 34 12 33 55 66 + * - +
90 (34 (12 (33 (55 66 +) *) -) +)
rpn/1 の最後に、-3947と90がスタックに残ります。なぜならそこに残っている90に働きかける演算子がないからです。 この問題を扱うのに2つ方法があります。1つは無視してスタックの一番上にあるもの(最後の計算結果)を持ってくる。 もう1つは算術が間違っているのでクラッシュさせる、です。 Erlangのポリシーは「クラッシュさせる」なので、2番目を選びましょう。 実際にクラッシュするのは rpn/1 の [Res] の部分です。 このパターンで確実にスタックに結果として要素が1つだけ残るようにしています。
`true = FunctionCall1 == FunctionCall2 という形のテストが幾つかありました。 理由は関数呼び出しを = の左手側では行えないからです。 それでもなおアサートのように振る舞います。比較結果がtrueになるように比較しているからです。
sumとprodについてのテストケースも追加しましたので、演習として自分で実装してみてテストすることが出来ます。 すべてのテストに成功したら、続きを見てみましょう:
1> c(calc).
{ok,calc}
2> calc:rpn_test().
ok
3> calc:rpn("1 2 ^ 2 2 ^ 3 2 ^ 4 2 ^ sum 2 -").
28.0
28は実際 sum(1² + 2² + 3² + 4²) - 2 と等しいです。 好きなだけ試してみましょう。
私たちの計算機をよりよくするために1つ追加するとしたら、よくわからない演算子やスタックに値が残っていてクラッシュするときに今の badmatch エラーではなく badarith エラーを上げるようにすることです。 そうすることでcalcモジュールのユーザがよりデバッグをしやすくなります。
10.2. ヒースローからロンドンへ¶
次の問題も Learn You a Haskell から採用した問題です。 あなたはあと1時間でヒースロー空港に着陸する飛行機に乗っています。 あなたはできるだけ早くロンドンに到着しなければいけません。 というのもあなたのお金持ちのおじさんが死にそうで、遺産相続の権利を最初に主張したいからです。
ヒースローからロンドンに行くためには2つの道があって、そこに繋がっている小さい道がたくさんあります。 速度制限と交通事情で、道路のいくつかの場所と小さな道では他に比べて長い時間がかかってしまいます。 茶栗する前におじさんの家までの最適な経路を見つけて、遺産をもらうチャンスを最大化してください。 ここにあなたがラップトップ内で見つけた地図があります:
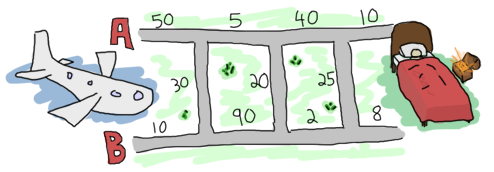
このオンラインブックを読んでErlangの大ファンになったので、あなたはこの問題をErlangで解くことに決めました。 地図を利用しやすくするために、 road.txt と名前をつけたファイルに次のようにデータを入力しました:
50
10
30
5
90
20
40
2
25
10
8
0
道は A1, B1, X1, A2, B2, X2, ..., An, Bn, Xn というパターンで敷かれています。 Xは地図のA側とB側をつないでいる道のどれかです。最後のX区間に0を入れました。 何をしようが、目的地に着いているからです。 データは3要素のタプルの形 {A,B,X} としてまとめることが出来るでしょう。
次に気づいたことは、Erlangで解こうにも、まずはじめに手で解けなければ意味が無いということです。 これをするために、再帰が教えてくれたことを実践してみましょう。
再帰関数を書くときは、最初に終了条件を見つけました。 この問題では、もし解析するタプルが1つしかなかったら、つまり A か B かの選択しかなかったどうか、ということです。(この場合、間に通っている X はどちらにせよ目的地なので意味がありません)
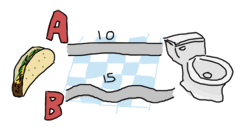
その場合、選択肢は経路Aか経路Bのどちらか短いほうを選ぶということになります。 もし再帰を正しく理解したなら、終了条件に収束するようにすべきだと分かっているはずです。 これはつまり、1つ進めるたびに、問題を小さくして次のステップでAかBを決めるようにしたいのです。
地図を展開して、始めて見ましょう:
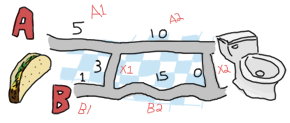
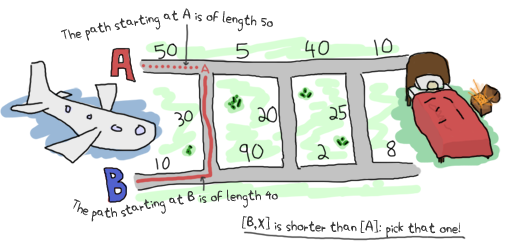
あら!おもしろいことになりました!どうやって3つ組 {5,1,3} を減らしてAかBかの厳しい選択にすることが出来るでしょうか? Aがどういう選択を取れるか見てみましょう。 A1 と A2 の交差点(ここでは A1 地点とします)に行くためには、直接 A1 を行くか(5)、B1 から来て(1)それから*X1*を横切ってくるか(3)のどちらかを選べます。 この場合、最初の選択肢(5)は2番目のもの(4)よりも値が大きいです。選択肢Aにとっては、最短経路は [B, X] です。 ではBについてはどうでしょうか? A1 から進んで(5)、その後 X1 を横切る(3)のか、直接 B1 を通るか(1)です。
できました!ここでわかったのは最初の交差点Aまでの経路 [B, X] は長さ4で、最初の B1 と B2 の交差点までの経路 [B] は長さ1です。 それでは、2番目の地点A( A2 と X2 の交差点)まではどの道を通ればいいか決めましょう。 そのためには、いまやったことと同じことをするのはどうでしょうか。 と言っても私がこの文章を書いているので、あなたはこの提案を受け入れるしかないんですが。 ではいきましょう!
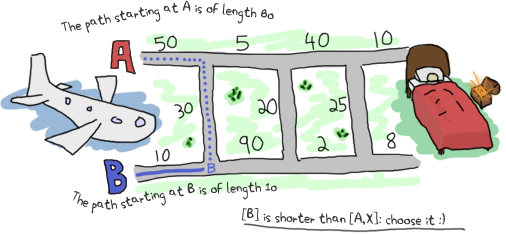
この場合通れるすべての経路は前にやった方法と同じやり方で探せます。 次の地点Aに行くには [B, X] から経路A2を通過して行くか、 [B] から B2 を経由して X2 を通って行くかです。 前者は長さ14 (14 = 4 + 10)で、後者は長さ16 (16 = 1 + 15 + 0)になります。 この場合、経路 [B, X, A] のほうが [B, B, X] よりも良いです。
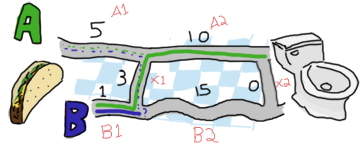
また、次の地点Bに行くには、 [B, X] から経路A2を行き、X2を渡っていくか、 [B] からB2を通過して行くかです。 前者は長さ14 (14 = 4 + 10 + 0)で、後者は長さ16 (16 = 1 + 15) です。ここでは最適な経路は前者の [B, X, A, X] となります。
このすべての処理が終わると、いよいよ最後の2経路だけが残ります。AまたはBです。ともに長さは14です。 どちらの経路を選択してもいいでしょう。最後の区間は、最後のXが長さ0なので、どちらも常に同じ長さになります。 この問題を再帰的に解くことによって、最終的には最短経路を選ぶことが出来ます。悪く無いですよね。どうでしょう?
微妙かもしれませんが、再帰関数を構築するのに必要な基本的な理論を説明しました。 実装したければ出来るとおもいますが、前にお約束したように実際に自分で再帰関数を書くのはほんの少しでしょう。 畳み込み(fold)を使いましょう。
Note
畳み込み(fold)がリストと一緒に使われている例をお見せした中で、foldはアキュムレータを用いたデータ構造に渡るイテレーションに関して幅広い概念を提供しています。 このような理由から、foldは木構造や辞書、配列、データベース表など多岐の実装に渡って使うことが出来ます。
上の地図とfoldのような抽象化を使うような実験の歳には非常に役に立ちます。 foldを使うことで、独自のロジックを使う場合に起きるデータ構造の差し替えを容易にします。
で、何を話してたんでしたっけ?あ、そうです!入力として使うファイルを準備してました。 ファイル操作をするためには fileモジュール が最適です。 fileモジュールには他のプログラミング言語にもよくあるようなファイル操作用の多くの関数が用意されています。 (パーミッションの設定、ファイルの移動、リネーム、削除、などなど)
またfileモジュールにはファイルの読み込み/書き込み用の関数も含まれています。たとえば file:open/2 や file:close/1 は名前の通りの操作が出来ます。(ファイルを開く/閉じる!)また file:read/2 はファイルの中身の取得が出来ます。(文字列またはバイナリの形式で取得出来ます)。 file:read_line/1 は1行を読み込み、 file:position/3 はファイルを開くポインタの位置を指定された場所に移動させることが出来ます。
たくさんのショートカット関数もあります。たとえば file:read_file/1 (ファイルを開いて、バイナリで読み込む)、 file:consult/1 (ファイルを開いて、Erlang項としてパースする)、あるいは file:pread/2 (読み込む場所を変更して読み込む)や file:pwrite/2 (書きこむ場所を変更して書きこむ)があります。
これらの関数がすべて使えるので、road.txtを読み込む関数を見つけるのは簡単でしょう。このファイルは比較的小さいと分かっているので、 file:read_file("read.txt"). を使います。
1> {ok, Binary} = file:read_file("road.txt").
{ok,<<"50\r\n10\r\n30\r\n5\r\n90\r\n20\r\n40\r\n2\r\n25\r\n10\r\n8\r\n0\r\n">>}
2> S = string:tokens(binary_to_list(Binary), "\r\n\t ").
["50","10","30","5","90","20","40","2","25","10","8","0"]
ここで、空白(" ")やタブ("\t")を適切なトークンに追加しました。これでファイルは “50 10 30 5 90 20 40 2 25 10 8 0”という形式で書くことが出来ます。 このリストが与えられたら、今度は文字列から整数に変換する必要があります。逆ポーランド記法計算機でやったのと同じやり方でやってみます:
3> [list_to_integer(X) || X <- S].
[50,10,30,5,90,20,40,2,25,10,8,0]
では新しいモジュール road.erl を開いて、このロジックを書き始めてみましょう:
-module(road).
-compile(export_all).
main() ->
File = "road.txt",
{ok, Bin} = file:read_file(File),
parse_map(Bin).
parse_map(Bin) when is_binary(Bin) ->
parse_map(binary_to_list(Bin));
parse_map(Str) when is_list(Str) ->
[list_to_integer(X) || X <- string:tokens(Str,"\r\n\t ")].
ここで関数 main/0 はファイルからコンテンツを読み込んで、 parse_map/1 に渡しています。 road.txt から関数 file:read_file/1 を使って読み込んでいるので、バイナリ形式で読み込まれます。 したがって、 parse_map/1 はリストでもバイナリでも動作するように実装いたしました。バイナリの場合は、文字列をリストに変換して、同名の関数を呼び出すだけです。(文字列を分割する関数はリストにのみ動作します)
次に、地図をパースしてデータを上で使ったような {A,B,X} の形式にします。悲しいことに、1度にリストから3つの要素を取り出す一般的で簡単な方法がないので、再帰関数内でパターンマッチを使って処理します:
group_vals([], Acc) ->
lists:reverse(Acc);
group_vals([A,B,X|Rest], Acc) ->
group_vals(Rest, [{A,B,X} | Acc]).
この関数は通常の末尾再帰の形式に則っています。何も複雑なことは行われていません。 parse_map/1 をちょっと変更してこの関数を呼び出してやる必要があります。
parse_map(Bin) when is_binary(Bin) ->
parse_map(binary_to_list(Bin));
parse_map(Str) when is_list(Str) ->
Values = [list_to_integer(X) || X <- string:tokens(Str,"\r\n\t ")],
group_vals(Values, []).
これらをコンパイルすると、ほしい地図が得られます。
1> c(road).
{ok,road}
2> road:main().
[{50,10,30},{5,90,20},{40,2,25},{10,8,0}]
いいですね、見た目いい感じです。これで関数を書かなければいけない部分にたどり着きました。 その関数をfoldに合うように変更してやります。そのためにはよいアキュムレータが必要です。
何をアキュムレータとして使うか決めるのに、私が思う最も簡単な方法は、自分自身が実行中のアルゴリズムの中にいることを想像することです。 いまこの問題の場合は、今2番目のタプル({5,90,20})の経路で最も短いものを見つけようとしているところを想像します。 どちらの経路が最適か決めるために、過去のタプルの結果を保持している必要が出てきます。 幸運にも、そのやり方は分かっています。なぜならアキュムレータも必要なく、ロジックはすでに分かっているからです。 Aに対しては:
2つの経路のうちで最短のものを選びます。Bに対しても同様です:
これで、Aから来るための最善の経路は [B, X] で、長さは40だということがわかります。 Bでは最善の経路は単純に [B] で、長さは10です。 この情報を使って、次のAとBそれぞれの最善経路を同じロジックで見つけることが出来ます。 ただし、前回分の経路も考慮します。他にはユーザに表示できるようにどの経路を通ってきたかの履歴も必要となります。 2つの経路(A、Bそれぞれ1つずつ)とそれぞれの積算の長さが必要な場合は、アキュムレータは次のような形になります。 {{DistanceA, PathA}, {DistanceB, PathB}} このようにして、foldのそれぞれのイテレーションはすべての状態を調べることができ、最終的な経路をユーザに見せることが出来ます。
これで、これから実装する関数に必要なすべてのパラメータが揃いました。 {A,B,X} のタプルとアキュムレータの形式 {{DistanceA,PathA}, {DistanceB,PathB}} です。
アキュムレータがちゃんと計算されるように、次のようなコードを書きます:
shortest_step({A,B,X}, {{DistA,PathA}, {DistB,PathB}}) ->
OptA1 = {DistA + A, [{a,A}|PathA]},
OptA2 = {DistB + B + X, [{x,X}, {b,B}|PathB]},
OptB1 = {DistB + B, [{b,B}|PathB]},
OptB2 = {DistA + A + X, [{x,X}, {a,A}|PathA]},
{erlang:min(OptA1, OptA2), erlang:min(OptB1, OptB2)}.
ここで, OptA1 はAの最初の選択肢で(Aを経由する)、 OptA2 は2番目の選択肢(BとXを経由する)です。 変数 OptB1 と OptB2 は地点Bに対して同様のことを行ったものです。 結果として、アキュムレータを得られた経路とともに返します。
上記のコードで保存された経路について、 [x] ではなく [{x,X}] の形式を使うことにした、という点に注目してください。 その理由は単純で、ユーザがそれぞれの区間の長さを知ることが出来るほうがいいと思ったからです。 他には、経路を逆順に積算しています( {x,X} は {b,B} の前に来る)。 これは末尾再帰であるfoldをしているためです。リストが全体として逆順になっているので、最後の1つはその他のものより前に走査される必要があります。
最終的に、 erlang:min/2 を使って最短経路を求めています。比較関数をタプルに使うのは辺に思えるかもしれませんが、すべてのErlang項は他のものと比較できることを思い出してください! 長さがタプルの最初の要素なので、このようにして並び替えることが出来ます。
残りの作業は、foldの中にその関数を入れることです:
optimal_path(Map) ->
{A,B} = lists:foldl(fun shortest_step/2, {{0,[]}, {0,[]}}, Map),
{_Dist,Path} = if hd(element(2,A)) =/= {x,0} -> A;
hd(element(2,B)) =/= {x,0} -> B
end,
lists:reverse(Path).
foldの最後で、両方の経路が最後の {x,0} を除いて、同じ距離になるように終わるべきです。 if で両方の経路で最後に訪れた要素を見て、 {x,0} に行かない方の経路を返します。 ステップが一番少ない経路を選んでもいいでしょう。( length/1 を使って比較) 最短経路がを選んだら、逆順に並び替えます。(末尾再帰のお作法です。逆順にしなければいけません。) これで結果をお披露目することができます。あるいはそっと秘密にしておいて、お金持ちのおじさんの遺産を得るのもいいでしょう。 そうするために、main関数で optimal_path/1 を呼ぶように変更しなければなりません。 それでコンパイル出来るようになります。
- main() ->
- File = “road.txt”, {ok, Bin} = file:read_file(File), optimal_path(parse_map(Bin)).
おお、見てください!正しい答えが得られました!グッジョブ!
1> c(road).
{ok,road}
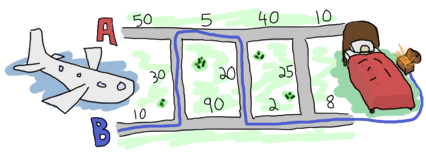
2> road:main().
[{b,10},{x,30},{a,5},{x,20},{b,2},{b,8}]
あるいは視覚的に表示してみましょう:
しかし、何が本当に有用なのかわかりますか?Erlangシェルの外側でプログラムを実行出来ることが大事です。 ここで再度main関数を変更する必要があります:
main([FileName]) ->
{ok, Bin} = file:read_file(FileName),
Map = parse_map(Bin),
io:format("~p~n",[optimal_path(Map)]),
erlang:halt().
mein関数はこれでアリティが1になりました。コマンドラインからパラメータを受け取らなければいけないからです。 また erlang:halt/0 という関数も追加しました。この関数は呼ばれた後にErlang VMをシャットダウンさせます。 さらに optimal_path/1 を io:format/2 でラップしました。こうしないと、Erlangシェルの外部で結果を見られないからです。
これらをまとめると、 road.erl はこのような見た目になると思います。(コメントは除去してください):
-Module(road).
-compile(export_all).
main([FileName]) ->
{ok, Bin} = file:read_file(FileName),
Map = parse_map(Bin),
io:format("~p~n",[optimal_path(Map)]),
erlang:halt(0).
%% Transform a string into a readable map of triples
parse_map(Bin) when is_binary(Bin) ->
parse_map(binary_to_list(Bin));
parse_map(Str) when is_list(Str) ->
Values = [list_to_integer(X) || X <- string:tokens(Str,"\r\n\t ")],
group_vals(Values, []).
group_vals([], Acc) ->
lists:reverse(Acc);
group_vals([A,B,X|Rest], Acc) ->
group_vals(Rest, [{A,B,X} | Acc]).
%% Picks the best of all paths, woo!
optimal_path(Map) ->
{A,B} = lists:foldl(fun shortest_step/2, {{0,[]}, {0,[]}}, Map),
{_Dist,Path} = if hd(element(2,A)) =/= {x,0} -> A;
hd(element(2,B)) =/= {x,0} -> B
end,
lists:reverse(Path).
%% actual problem solving
%% change triples of the form {A,B,X}
%% where A,B,X are distances and a,b,x are possible paths
%% to the form {DistanceSum, PathList}.
shortest_step({A,B,X}, {{DistA,PathA}, {DistB,PathB}}) ->
OptA1 = {DistA + A, [{a,A}|PathA]},
OptA2 = {DistB + B + X, [{x,X}, {b,B}|PathB]},
OptB1 = {DistB + B, [{b,B}|PathB]},
OptB2 = {DistA + A + X, [{x,X}, {a,A}|PathA]},
{erlang:min(OptA1, OptA2), erlang:min(OptB1, OptB2)}.
そして、コードを実行してみます:
$ erlc road.erl
$ erl -noshell -run road main road.txt
[{b,10},{x,30},{a,5},{x,20},{b,2},{b,8}]
やりました、正しい結果です!これら全部で、ちゃんと動作するようになりました。これをbashスクリプトやバッチファイルにまとめて、1つの実行可能ファイルにすることも出来ますし、同様の結果を得るのに escript を使うこともできます。
これら2つの演習を通して、問題を解く際には全部をまとめて解く前に、小さな部分に分割して個々に問題を解くほうがずっと簡単だとわかったでしょう。また、問題を理解する前に急いでプログラムを書き始めるのも意味が無いとわかったでしょう。 最後に、いくつかのテストを行うことが大事です。そうすることですべてがちゃんと動作することが確認でき、最終的な結果を変更することなくコードを変更できるようになります。