21. OTPでアプリケーションを作る¶
これまで汎用サーバ、有限ステートマシン、イベントハンドラ、スーパバイザの使い方について見てきました。 しかし、それらを一緒に使ってアプリケーションやツールを作る方法はまだ見てきてません。
Erlangアプリケーションは関係するコードとプロセスの集まりです。 特にOTPアプリケーションはプロセスにOTPビヘイビアを使っていて、それらをVMにすべての構築方法と解体方法を伝える非常に明確な構造でラップしています。
この章では、OTPコンポーネントを使ってアプリケーションを作りますが、すべてをOTPで作るわけではありません。その理由は、いまは全体のまとめをしないからです。 完全なOTPアプリケーションの詳細は、少々複雑でそれだけで章を割くに値します。(次の章で扱います) この章では、プロセスプールの実装について説明します。 プロセスプールの後ろにある考えは、システム内で汎用な方法で稼働しているリソースを管理し制限することです。
21.1. プロセスのプール¶
はい、プールによって同時に走らせられるプロセスの数を制限することが出来ます。 またプールは稼働しているワーカの数が上限に達した時に、ジョブをキューに貯めておくことも出来ます。 ジョブはリソースが解放されたらすぐに実行されるか、単純にユーザに何も出来ないと告げてブロックします。 実世界のプールではプロセスプールと似たことはなにもしないにもかかわらず、後者の動作をしたくなる理由があります。 そのような理由には次のようなものを含みます:
- サーバを最大でN個の並列接続に制限する
- アプリケーションによって開かれるファイルの数を制限する
- あるシステムにはより多くのリソースを与え、ほかのものにはより少ないリソースを与えることで、リリースしているシステム中の異なるサブシステムに優先順位を与える。 たとえば、経営のためのレポート生成を担っているプロセスよりもクライアントリクエストのプロセスに多くのリソースを割り当てるということです
- アプリケーションが、不定期に時々起きる一気にアクセスが来る高負荷状況で、キューにタスクを貯めて、安定稼働できるようにする
したがって、私たちのプロセスプールアプリケーションはいくつかの関数をサポートする必要があります:
- アプリケーションの起動と停止
- 特定のプロセスプールの起動と停止(すべてのプールはプロセスプールアプリケーション内にあります)
- プール内のタスクを実行し、プールがいっぱいなら起動できないとあなたに告げる
- 余裕がある場合にはプール内のタスクを実行する。さもなければ、タスクがキューの中にある間は呼び出し元のプロセスを待たせておく。タスクが実行されたら呼び出し元は解放する。
- プール内で、できる限りタスクを非同期に実行する。もし余裕がなければ、タスクをキューに貯め、いつでも実行する。
これらの要求がプログラムの設計をする助けになります。 いまはスーパバイザも使えることも心に留めておいて下さい。 そしてもちろん、スーパバイザを使いたいです。 もし冗長性の点において新たな力を与えてくれるとしたら、柔軟性にある程度の制限もかけるということなのです。 それでは旅を始めましょう。
21.2. 玉ねぎの皮理論¶
スーパーバイザを使ってアプリケーションを設計で楽をするために、何が監視を必要として、どのように監視されば良いのかを考えることが大切です。 異なる設定を持った異なる戦略があることを思い出すでしょう。これらはそれぞれ異なるエラーを持った様々な種類のコードに向いています。 様々なミスがなされうるのです!
新米でも経験豊富なErlangプログラマでもやっかいなことの1つに、状態を失った場合にどう対処するか、というものがあります。 スーパーバイザはプロセスを殺し、状態が失われて、悲しいことです。 これを助けるために、異なる種類の状態を識別します:
- 静的な(static)状態。この状態は設定ファイルや他のプロセス、アプリケーションを再起動しているスーパーバイザから容易に取得できます。
- 動的な(dynamic)状態。これは再計算できるデータからできています。この状態には、初期状態から今現在の状態まで変換しなければならない状態も含まれています。
- 再計算できない動的なデータ。これはユーザの入力、生のデータ、逐次的な外部イベント、などがあります。
ここで、静的なデータはいくばくか扱いやすいものです。 たいていの場合、そのデータはスーパバイザから直接得ることができます。 動的だけど再計算可能なデータについても同様です。 この場合、実際は init/1 関数かあるいはコード中のどこか違う場所でデータを取得して再計算したいと思うでしょう。
最もやっかいな状態は、再計算できず、かつ基本的には失いたくない動的なデータです。 ある場合では、いつもこの選択が良いとは限りませんが、データベースにこのデータを登録するでしょう。
玉ねぎの皮理論の考えは、これらの異なる状態すべてが、お互いに異なる種類のコードを隔離することによって、適切に保護できるようにすることにあります。 つまりプロセスの隔離です。
静的な状態はスーパバイザや、いま起動されてようとしているシステムなどによって扱われます。 子プロセスが死ぬたびに、スーパバイザはそれらを再起動して、いつでも取得できる静的な状態を注入できます。 ほとんどのスーパバイザの定義が生来かなり静的なものなので、追加する監視の各層は、アプリケーションを失敗や状態の喪失から守る盾となっています。
再計算できる動的な状態はたくさんの解決方法があります。 スーパバイザから送られる静的な状態からプロセスを起動し、他のプロセスやデータベース、テキストファイル、現在の環境などから状態を取り戻します。 再起動ごとに状態を取り戻すのは比較的容易です。 再起動を行うスーパバイザがあるという事実は、状態を生かしておくのには十分に役に立ちます。
動的で再計算ができない状態は、より思慮深い手法が必要です。 玉ねぎの皮手法の本質はここにあります。 それは、最も重要な(または取り戻すのが困難な)データは、最も保護されるべきデータでなければいけない、という考えに基づいています。 実際に失敗できない箇所はアプリケーションの エラーカーネル と呼ばれます。

エラーカーネルは、どこよりも try ... catch を使いたくなる部分で、例外が致命的になる部分です。 ここが、あなたがエラーを無くしたいと思っている部分です。 この辺を注意深くテストしなければいけません。戻す方法がない部分は特にです。 顧客の注文をまだ処理の途中で失いたくはないでしょう。 ある操作は、別の操作よりも安全だと考えられます。これに基づいて、致命的なデータをできるだけ最も安全な核に保存し、いくらか危険なものはすべてその外側に置きます。 言い方を変えれば、お互い関連している操作はすべて同じ関しツリー内にあるべきだし、関係していない操作は別のツリーに分けられるべきです。 同じツリー内で、失敗を生みやすいけれど致命的でない操作は異なるサブツリーにあれば良いでしょう。 可能であれば、ツリー内で再起動が必要な部分だけすれば良いのです。 実際にプロセスプールの監視ツリーを設計するときに、こういったことの例を見ます。
21.3. プールのツリー¶
ではどのようにこのプロセスプールを整理したらよいのでしょうか。 ここで2つの考え方があります。 1つはボトムアップで設計していく(個別のコンポーネントをすべて書いてから必要に応じて組み合わせる)方法と、トップダウンで設計していく(すべてのパーツがすでにあるかのように設計していき、それから組み立てていく)という方法です。 両方の手法とも、そのときの状況や個人的なスタイルによって、同等に正当です。 理解しやすくするために、ここではトップダウンに進めていきます。
では、私たちのツリーはどのようになるべきでしょう。 私たちの要求としては、プールアプリケーションをまとめて起動できる、多くのプールがある、各プールがキューに貯められるたくさんのワーカを持っている、というものがあります。 これは、すでにいくつかの設計の制約条件を示唆しています。
プールごとに1つの gen_server が必要になるでしょう。 このサーバの仕事はワーカがいくつプール内にあるかのカウンターを管理することです。 便利のために、同じサーバがタスクのキューも保持するものとします。 ですが、個々のワーカの面倒がだれがみたらいいんでしょうか。サーバ自身でしょうか。
これをサーバで行うのは面白いことです。 結局、サーバはプロセスの動きを見て数える必要がありますし、サーバ自身でプロセスを監視するのはしゃれた方法です。 さらに、サーバーもプロセスもクラッシュするときは周りの状態もろとも消し去ります。(さもなければ、サーバが再起動したあとにタスクを追跡できません) いくつか不利な点もあります。サーバに多くの責任を与えると、脆弱に見え、また既に存在しているよくテストされたモジュールの機能と重複してしまうことがありえます。
すべてのワーカが適切に管理されるには、そのためだけのスーパバイザを使うべきでしょう。
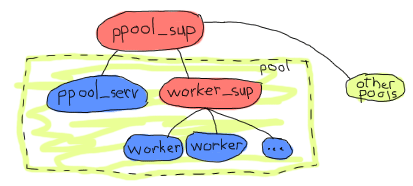
たとえば、上の図は単一のスーパバイザがすべてプールを管理しています。 各プールは実際にプールサーバとスーパバイザとワーカの集合です。 プールサーバはワーカスーパバイザの存在を知っていて、それにアイテムを追加するようにめいじます。 子プロセスを追加することが、とても動的で、その時点でどれくらい動的かわかっていない場合、 simple_one_for_one スーパバイザが使われるべきです。
Note
Erlang標準ライブラリがすでにpoolモジュールを持っているのでppoolという名前にしました。 またプールをかなりもじったものでもあります。
このようにする利点は、 worker_sup スーパバイザが単一の種類のOTPワーカだけを追跡する必要があるため、各プールは単純な管理と定義が容易な再起動戦略をもっているような、明確に定義されたワーカを管理するということが保証されていることです。 ここにある例は、良く定義されているエラーカーネルの1例です。 Web接続のためのソケットプールとログファイル用のサーバプールを使っているなら、アプリケーションでログファイルを扱っている部分での間違ったコードや入り組んだパーミッションが、確実にソケットを管理している部分の邪魔をしないようにします。 もしログファイルのプールが頻繁にクラッシュしたら、それらは終了させたられ、そのスーパバイザは停止するでしょう。 いや、待ってください!
そうなのです。 すべてのプールは同じスーパバイザの下にあるので、与えられたプールやサーバが短期間に再起動し過ぎると、他のプールも落としてしまう可能性があります。 これより、もう1つ監視の層を追加したくなるでしょう。 そうすることで、2つ以上のプールを同時に扱うことがより単純にもなりますので、私たちのアプリケーションのアーキテクチャを次のようにしてみましょう:
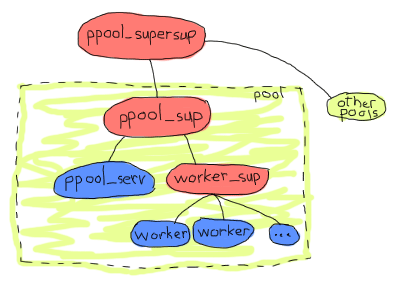
これで少し納得のいくものになります。 玉ねぎの皮理論の観点でいけば、すべてのプールは独立していて、ワーカはお互いに独独立して、 ppool_serv サーバはすべてのワーカから隔離されます。 これはアーキテクチャとして十分良い物で、必要なものがすべてかなっています。 再び、上から下に向かって、実装を始めてみましょう。
21.4. スーパバイザを実装する¶
まず最上位のスーパバイザである ppool_supersup から始めましょう。 このスーパバイザがしなければいけないことは、プールのスーパバイザを必要になったときに起動することだけです。 スーパバイザにいくつかの関数を与えます。アプリケーション全体を起動する start_link/0 、それを停止する stop/0 、特定のプールを作る start_pool/3 そしてその逆の stop_pool/1 です。 また init/1 も忘れてはいけません。スーパバイザビヘイビアに要求される唯一のコールバックです:
-module(ppool_supersup).
-behaviour(supervisor).
-export([start_link/0, stop/0, start_pool/3, stop_pool/1]).
-export([init/1]).
start_link() ->
supervisor:start_link({local, ppool}, ?MODULE, []).
ここで最上位プロセスプールスーパバイザに ppool という名前を付けます。(これは {local, Name} を使うということを説明します。ノード上の gen_* プロセスを登録する上でのOTPの命名規則で、他にもう1つの規則が分散登録のために存在します) この名前を付けた理由は、1つのErlangノードにつき1つの ppool だけが存在し、名前の衝突を心配することなく名前を付けることができるためです。 幸いにも、同じ名前をプールの集合全部を止めるときにも使うことができます:
%% technically, a supervisor can not be killed in an easy way.
%% Let's do it brutally!
stop() ->
case whereis(ppool) of
P when is_pid(P) ->
exit(P, kill);
_ -> ok
end.
コード中のコメントにあるように、スーパバイザを優雅に止めることはできません。 その理由は、OTPフレームワークはすべてのスーパバイザに対して明確に定義された終了手順を提供していますが、いまいる場所からではそれを使えないからです。 次の章でそのやり方を見ますが、いまのところは、強制的にスーパバイザを殺すのが最善な方法です。
いったい最上位のスーパバイザとはなんでしょうか。 唯一のタスクはメモリ上にプールを保持して、それを監視することです。 この場合、子プロセスがいないスーパバイザになります:
init([]) ->
MaxRestart = 6,
MaxTime = 3600,
{ok, {{one_for_one, MaxRestart, MaxTime}, []}}.
さて、個々のプールのスーパバイザの起動とそれらの ppool への追加に注目しましょう。 最初の要件を考えると、プールが受け入れられるワーカの数とワーカスーパバイザが個々のワーカを起動するのに必要な {M,F,A} のタプルという、2つのパラメータが必要になるでしょう。 ついでに名前も追加しましょう。 それから、プロセスプールのスーパバイザを起動するときに ChildSpec をそこに渡します。
start_pool(Name, Limit, MFA) ->
ChildSpec = {Name,
{ppool_sup, start_link, [Name, Limit, MFA]},
permanent, 10500, supervisor, [ppool_sup]},
supervisor:start_child(ppool, ChildSpec).
各プールスーパバイザが永続的なものとして起動され、必要な引数を持っていることがわかりますね。(プログラマが設定したデータをこのようにして静的なデータに変換していることに注目してください) プールの名前はスーパバイザに渡され、子プロセスの仕様で識別子として使われています。 最大停止時間も 10500 と設定されています。 この値を選び出すのは非常に難しいことです。 すべての子プロセスが停止するのに十分大きな時間になるようにさえすればよいです。 あなたの要件とテストを見て、自分で最適化して下さい。 見当がつかなければ infinity を設定しても良いでしょう。
プールを停止するには、 ppool スーパバイザ( supersup です!)に対応する子プロセスを殺すように命じます:
stop_pool(Name) ->
supervisor:terminate_child(ppool, Name),
supervisor:delete_child(ppool, Name).
プールの名前を ChildSpec 識別子に与えたのでこのようにすることが可能です。 すごいですね! つぎに各プールの直接のスーパバイザに注目しましょう!
ppool_sup はプールサーバとワーカースーパバイザの面倒を見ています。
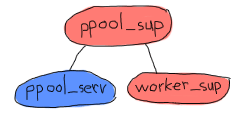
なにか面白いものはみつかりましたか。 ppool_serv プロセスは worker_sup プロセスに連絡が取れるべきです。 同じスーパーバイザによって同時に起動されるようにしたいと思っている場合は、 supervisor:which_children/1 を使って策略を練るか、(ユーザが呼び出せるように) ppool_serv プロセスとスーパーバイザの両方に名前を与えないと、 ppool_serv に worker_sup を知らせる方法がありません。 ここで、私たちはスーパーバイザに名前は与えたくありません。その理由は:
- ユーザは直接それを呼び出す必要がないから
- 動的にアトムを生成する必要があり、そのことに非常に気が立っているから
- もっと良い方法があるから
同時に起動できるようにする方法は、基本的に、動的にワーカスーパバイザをその ppool_sup に配置するためにプールサーバを取得することです。 もしこれが曖昧だと思うのなら、すぐに理解できるようになるでしょう。 いまのところは、サーバだけを起動します:
-module(ppool_sup).
-export([start_link/3, init/1]).
-behaviour(supervisor).
start_link(Name, Limit, MFA) ->
supervisor:start_link(?MODULE, {Name, Limit, MFA}).
init({Name, Limit, MFA}) ->
MaxRestart = 1,
MaxTime = 3600,
{ok, {{one_for_all, MaxRestart, MaxTime},
[{serv,
{ppool_serv, start_link, [Name, Limit, self(), MFA]},
permanent,
5000, % Shutdown time
worker,
[ppool_serv]}]}}.
まあこんなところです。 Name は self() 、つまりスーパバイザ自信のPidと一緒にサーバに渡されることに留意してください。 これでサーバがワーカスーパバイザを生成する呼び出しを行えるようになります。変数 MFA はその呼び出しにおいて、 simple_one_for_one スーパバイザにどのようなワーカを走らせるかを知らせるために使われます。
サーバがどのようにあらゆること制御するのかをいずれ見ていきますが、いまは全ワーカの管理をする ppool_worker_sup を書くことで、このアプリケーションのすべてのスーパバイザの実装を終えてしまいましょう。
-module(ppool_worker_sup).
-export([start_link/1, init/1]).
-behaviour(supervisor).
start_link(MFA = {_,_,_}) ->
supervisor:start_link(?MODULE, MFA).
init({M,F,A}) ->
MaxRestart = 5,
MaxTime = 3600,
{ok, {{simple_one_for_one, MaxRestart, MaxTime},
[{ppool_worker,
{M,F,A},
temporary, 5000, worker, [M]}]}}.
単純でしたね。 simple_one_for_one を選んだ理由は、追加されるワーカの数が多く、また速度に対する要求があり、さらにワーカの種類を制限したいためです。 すべてのワーカは一時的なもので、ワーカの起動に {M,F,A} タプルを使っているため、そこではどのようなOTPビヘイビアも使うことができます。

ワーカを一時的にする理由は2つあります。 まず、ワーカが失敗した場合に再起動される必要があるかどうか、あるいはどのような再起動戦略が必要かが分かりません。 次に、ユースケースによりますが、プールは、ワーカの生成元がワーカのPidにアクセスできる場合にのみ役に立ちます。 これが安全かつ単純に動作するためには、ワーカのの生成元を追跡して、再起動の通知をしない限り、勝手にワーカを再起動できません。 これはPidを取得するだけでも状況を非常に複雑にします。 もちろん、ワーカのPidを返さずに勝手に再起動する独自の ppool_worker_sup を書いてもいいです。 本質的にはこの設計においては何も間違っていません。
21.5. ワーカに取り掛かる¶
プールサーバは、すべての巧みなビジネスロジックが組み込まれている部分なので、アプリケーションの最も複雑な部分です。 ここで、私たちがサポートしようとしている操作のおさらいをします。
- プールでタスクを実行して、プールがいっぱいだったら実行できないと通知する
- プールに余裕があればタスクを実行する。さもなければ、タスクがキューにある間は、それが実行されるまで、呼び出し元プロセスを待たせておく
- プール内でタスクをできるだけ非同期に実行する。もし余裕がなければ、それをキューに貯めておき、いつでも実行する。
最初の要件は run/2 という関数で行われ、2つ目の要件は sync_queue/2 で、最後の要件は async_queue/2 で行われます:
-module(ppool_serv).
-behaviour(gen_server).
-export([start/4, start_link/4, run/2, sync_queue/2, async_queue/2, stop/1]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
code_change/3, terminate/2]).
start(Name, Limit, Sup, MFA) when is_atom(Name), is_integer(Limit) ->
gen_server:start({local, Name}, ?MODULE, {Limit, MFA, Sup}, []).
start_link(Name, Limit, Sup, MFA) when is_atom(Name), is_integer(Limit) ->
gen_server:start_link({local, Name}, ?MODULE, {Limit, MFA, Sup}, []).
run(Name, Args) ->
gen_server:call(Name, {run, Args}).
sync_queue(Name, Args) ->
gen_server:call(Name, {sync, Args}, infinity).
async_queue(Name, Args) ->
gen_server:cast(Name, {async, Args}).
stop(Name) ->
gen_server:call(Name, stop).
start/4 と start_link/4 では、 Args はスーパバイザに送られる3要素タプル {M,F,A} の A の部分に渡される追加の引数です。 同期キューでは待ち時間を infinity に設定したことに留意してください。
先にも触れたように、サーバ内からスーパバイザを起動しなければいけません。 私たちがこれから見ていくようにコードを追加するなら、サーバを上から下に向かって読んでいくだけというよりむしろ、機能ごとにコードを追加していくので、空の gen_server テンプレート(あるいはすでに書き終わったファイル)を入れたいと思うでしょう。
最初にすることは、スーパバイザの作成を扱う部分です。 前の章で動的監視について少し触れた部分を思い出すと、 simple_one_for_one は子プロセスをほとんど追加する必要のない場合には必要ないので、 supervisor:start_child/2 がこの機能を担うべきです。 まずワーカスーパバイザの子プロセスの仕様を定義します:
%% The friendly supervisor is started dynamically!
-define(SPEC(MFA),
{worker_sup,
{ppool_worker_sup, start_link, [MFA]},
permanent,
10000,
supervisor,
[ppool_worker_sup]}).
特別なことはなにもありません。 それから、サーバの内部状態を定義できます。 実行できるプロセスの数、スーパバイザのPid、すべてのジョブのためのキューなど、いくつかのデータを追跡しなければいけないでしょう。 いつワーカの処理が完了したかを知り、起動するためにキューからタスクを取り出すためには、個々のワーカをサーバから追跡する必要があるでしょう。 これを行う真っ当な方法は、モニターを使うことです。したがって、すべてのモニターの参照も保存しておくために refs フィールドも状態レコードに追加しましょう:
-record(state, {limit=0,
sup,
refs,
queue=queue:new()}).
この準備ができたら、 init 関数の実装を始められます。 自然な実装をすると次のようになるでしょう:
init({Limit, MFA, Sup}) ->
{ok, Pid} = supervisor:start_child(Sup, ?SPEC(MFA)),
{ok, #state{limit=Limit, refs=gb_sets:empty()}}.
次に進みましょう。 と言いたいところですが、このコードは間違っています。 物事が gen_* ビヘイビアと連携する方法は、ビヘイビアを生成するプロセスが、処理を再開する前に、 init/1 関数が戻り値を返すまで待機する、という方法でした。 これはつまり、そこで supervisor:start_child/2 を呼び出すことで、次のようなデッドロックを引き起こすということです:
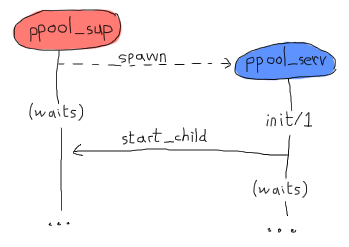
両プロセスともにどちらかがクラッシュするまでお互いを待ち続けてしまいます。 これを回避する最も綺麗な方法は、サーバが自分自身に送り特別なメッセージを作り、それが返されたら(そしてプールスーパバイザが自由になったら)すぐに handle_info/2 で処理できるようにすることです:
init({Limit, MFA, Sup}) ->
%% We need to find the Pid of the worker supervisor from here,
%% but alas, this would be calling the supervisor while it waits for us!
self() ! {start_worker_supervisor, Sup, MFA},
{ok, #state{limit=Limit, refs=gb_sets:empty()}}.
こちらのほうがすっきりしています。 それから handle_info/2 関数については、次のような節を追加します:
handle_info({start_worker_supervisor, Sup, MFA}, S = #state{}) ->
{ok, Pid} = supervisor:start_child(Sup, ?SPEC(MFA)),
{noreply, S#state{sup=Pid}};
handle_info(Msg, State) ->
io:format("Unknown msg: ~p~n", [Msg]),
{noreply, State}.
ここで、最初の節はおもしろい部分です。 自分自身に送ったメッセージ(必ず最初に受信するもの)を見て、プールスーパバイザにワーカスーパバイザを追加するように命じて、このPidを追跡して、できあがりです! ようやく私たちのツリーは完全に初期化されました。 やれやれです。 すべてのコンパイルしてみて、ここまでミスが無いことを確認してみてください。 残念ながら、まだ全然実装が終わってないのでアプリケーションをテストできません。
Note
実行前にアプリケーション全体を実装するという考えが好きではないとしても心配要りません。 物事がよどみなく全体の論理展開がされるようしています。 全体の設計(先に図示したものと同じ)を心の中で行なっている間、このプールアプリケーションを、あちこちに書いたいくつかのテストと大量のリファクタリングでちょっとしたテスト駆動開発のやり方で書き始め、すべてを関数型に保つようにしました。
最初に書き終わった状態で製品水準のコードを書けるErlangプログラマ(他のほとんどの言語のプログラマでもそうですが)はほとんどいません。そして、筆者は本書で取り上げている例がそう思わせるほどには賢くありません。
さて、少し物事が片付きましたね。 今度は run/2 関数について取り掛かりましょう。 これは、 {run, Args} という形式のメッセージを伴った同期呼び出しで、次のような動作をします:
handle_call({run, Args}, _From, S = #state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{reply, {ok,Pid}, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_call({run, _Args}, _From, S=#state{limit=N}) when N =< 0 ->
{reply, noalloc, S};
関数の先頭部分長いですが、処理のほとんどがそこで行われいることが分かります。 プールの中に余裕があるときはいつでも(プログラマが最初にプールを追加することで決定された元々の制限の N )、ワーカを起動することを許可します。 そのあと、いつ処理が終わったかを知るためにモニターを設定し、これらをすべて状態内に保存し、カウンターをデクリメントして、おしまいです。
プール内に余裕が無いときは、単純に noalloc を返します。
sync_queue/2 に対する呼び出しは非常に似た実装をしています:
handle_call({sync, Args}, _From, S = #state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{reply, {ok,Pid}, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_call({sync, Args}, From, S = #state{queue=Q}) ->
{noreply, S#state{queue=queue:in({From, Args}, Q)}};
もっ多くのワーカを稼働できる場所があれば、最初の節は run/2 で実装したものと全く同じになります。 ワーカが全く稼働できないときに違いが出てきます。 run/2 でそうしたように noalloc を返すのではなく、今回は呼び出し元に対して戻り値を返さず、 From の情報を保持し、あとでワーカが稼働できる余裕ができた時のためにキューに貯めます。 これをどのようにキューから取り出して扱うかはすぐあとで見ますが、いまは、 handle_call/3 コールバックの実装を次のような節を追加して終えましょう:
handle_call(stop, _From, State) ->
{stop, normal, ok, State};
handle_call(_Msg, _From, State) ->
{noreply, State}.
これは未知の条件も対応と、 stop/1 の呼び出しを行います。 さて async_queue/2 を動作させることに焦点を当ててみます。 async_queue/2 は基本的にワーカがいつ実行されたかは気にせず、まったく戻り値を期待していないので、呼び出しというよりもメッセージの投入をするものとして決められました。 この関数のロジックを見れば、前の2つのオプションと恐ろしいほど似ていることに気がつくでしょう:
handle_cast({async, Args}, S=#state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{noreply, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_cast({async, Args}, S=#state{limit=N, queue=Q}) when N =< 0 ->
{noreply, S#state{queue=queue:in(Args,Q)}};
%% Not going to explain this one!
handle_cast(_Msg, State) ->
{noreply, State}.
再度確認しますが、戻り値を返さない以外の唯一の大きな違いは、ワーカを実行する余裕がないときには、キューに貯められるという部分です。 しかし今回は From 情報がなく、 From 情報なしにキューに送るだけです。この場合制限は変化しません。
いつ、キューからなにかを取り出す時間だと知るのでしょうか。 そういえば、私たちにはそこら中にモニターを設定していて、その参照を gb_sets に保存していたのでした。 ワーカが落ちたときには、いつでも通知されます。 そこから実装を始めてみましょう:
handle_info({'DOWN', Ref, process, _Pid, _}, S = #state{limit=L, sup=Sup, refs=Refs}) ->
io:format("received down msg~n"),
case gb_sets:is_element(Ref, Refs) of
true ->
handle_down_worker(Ref, S);
false -> %% Not our responsibility
{noreply, S}
end;
handle_info({start_worker_supervisor, Sup, MFA}, S = #state{}) ->
...
handle_info(Msg, State) ->
...
このスニペットで行なっていることは、 'DOWN' メッセージがワーカから取得できるようにすることです。 このメッセージがワーカから来ないとき(それ自体は驚くべきことなんですが)には、ただ無視します。 しかしながら、メッセージがまさに欲しいものだったときには、 handle_down_worker/2 という関数を呼び出します:
handle_down_worker(Ref, S = #state{limit=L, sup=Sup, refs=Refs}) ->
case queue:out(S#state.queue) of
{{value, {From, Args}}, Q} ->
{ok, Pid} = supervisor:start_child(Sup, Args),
NewRef = erlang:monitor(process, Pid),
NewRefs = gb_sets:insert(NewRef, gb_sets:delete(Ref,Refs)),
gen_server:reply(From, {ok, Pid}),
{noreply, S#state{refs=NewRefs, queue=Q}};
{{value, Args}, Q} ->
{ok, Pid} = supervisor:start_child(Sup, Args),
NewRef = erlang:monitor(process, Pid),
NewRefs = gb_sets:insert(NewRef, gb_sets:delete(Ref,Refs)),
{noreply, S#state{refs=NewRefs, queue=Q}};
{empty, _} ->
{noreply, S#state{limit=L+1, refs=gb_sets:delete(Ref,Refs)}}
end.
かなり複雑なものになりました。 ワーカが死んでいるので、キューを見にいって次のワーカを実行します。 これをキューから要素をポップし、結果を見ることで行なっています。 もし少なくとも1つの要素がキューにあったら、 {{value, Item}, NewQueue} の形式になるでしょう。 もしキューが空なら、 {empty, SameQueue} を返します。 さらに、 {From, Args} という値を持っているときは、これが sync_queue/2 かあるいは async_queue/2 から来たものだということが分かります。
{From, Args} がどちらの関数から来たものでも、両方場合ともにほぼ同様の動作をします。つまり新しいワーカーがワーカスーパバイザに配置されて、古いワーカのモニターの参照は取り除かれて、新しいワーカの参照に置き換えられます。 唯一異なる点は、同期呼び出しの場合は手動で戻り値を返し、非同期呼び出しの場合はなにもしないままでいることです。 それだけです。
キューが空の場合は、ワーカの制限を1つインクリメントする以外は何もする必要がありません。
最後に、標準のOTPコールバックを追加します:
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) ->
ok.
以上です。あるいはプールはすでに使われています! しかし、とても不親切なプールですね。 必要な関数はすべてあちこちに散らばっています。 いくつかは ppool_supersup にあって、いくつかは ppool_serv にあります。 さらにモジュール名は意味もなく長いです。 もうちょっとましにするために、次のようなAPIモジュール(呼び出しを抽象化するだけ)をアプリケーションディレクトリに追加します。
%%% API module for the pool
-module(ppool).
-export([start_link/0, stop/0, start_pool/3,
run/2, sync_queue/2, async_queue/2, stop_pool/1]).
start_link() ->
ppool_supersup:start_link().
stop() ->
ppool_supersup:stop().
start_pool(Name, Limit, {M,F,A}) ->
ppool_supersup:start_pool(Name, Limit, {M,F,A}).
stop_pool(Name) ->
ppool_supersup:stop_pool(Name).
run(Name, Args) ->
ppool_serv:run(Name, Args).
async_queue(Name, Args) ->
ppool_serv:async_queue(Name, Args).
sync_queue(Name, Args) ->
ppool_serv:sync_queue(Name, Args).
ついに実装が終わりました!
Note
私たちのプロセスプールはキューに貯めることができる要素数の制限を設けていないことに気がついたでしょう。 ある場合では、実際のサーバアプリケーションでは、メモリを使いすぎてクラッシュしないように、いくつキューできるか上限を設ける必要があります。この問題は run/2 と sync_queue/2 を一定数の呼び出し元からしか使わないようにすることでとりあえず回避はできるのですが、上限があったほうがいいでしょう。(もしすべてのコンテンツ生成器がプール内の余裕を待っている場合、はじめから多くのコンテンツを生成するのを辞めます)
キューのサイズに上限を設けることは、読者のみなさんへの宿題としますが、比較的単純ではないので心してください。 新しいパラメータをすべての関数からサーバに至るまで渡す必要があり、キューに追加する前に上限を確認する必要があるでしょう。
さらに、システムの負荷を制御するために、同期呼び出しを使って、時々呼び出し元に制限をかけたく鳴るでしょう。 同期呼び出しは、コンシューマより速いプロデューサによってシステムが多忙極まりなくなっているときに、やってくる問い合わせをブロックすることが出来ます。 これによって、全体的に混乱状態になって負荷が高い状態よりは反応は良くできます。
21.6. ワーカを書く¶
私の事をよく見て下さい。私はいつも嘘をついています! プールはまだ使う準備ができていません。 まだワーカがありません。 忘れてました。 並列アプリケーションを書く章 では素敵なタスクリマインダーを作った私たちが、こんなことを忘れていたなんて、恥もいいところです。 私にとってはあのリマインダーは十分ではなかったので、ここでは、もっとうるさくつついてくれるものを書きましょう。
基本的には、タスクごとにワーカを書いて、ワーカはタスクの期日が来るまでメッセージを繰り返し送ることでしつこく通知します。 このアプリは次のことができます:
- どのタスクが通知をするかの時間遅延を設ける
- メッセージが送られるべき場所を伝えるためのアドレス(Pid)の取得
- プロセスのメールボックスに送られた通知メッセージと、呼び出せるように通知元のPidを取得すること
- タスクが完了したことを伝え、リマインダーがリマインドを止めることができる停止関数
それでは実装してみましょう:
%% demo module, a nagger for tasks,
%% because the previous one wasn't good enough
-module(ppool_nagger).
-behaviour(gen_server).
-export([start_link/4, stop/1]).
-export([init/1, handle_call/3, handle_cast/2,
handle_info/2, code_change/3, terminate/2]).
start_link(Task, Delay, Max, SendTo) ->
gen_server:start_link(?MODULE, {Task, Delay, Max, SendTo} , []).
stop(Pid) ->
gen_server:call(Pid, stop).
そうです、さらに別の gen_server を使っています。 人々がそこかしこで gen_server を使っていて、たとえそれが適切でない時でも使われていることに気付くでしょう! 私たちのプールは gen_server だけでなく、どんなOTP準拠のプロセスでも受け入れることができるということを意識しておくことが大切です。
init({Task, Delay, Max, SendTo}) ->
{ok, {Task, Delay, Max, SendTo}, Delay}.
基本的なデータだけを取って、それを転送します。 再度になりますが、 Task はメッセージを送るもので、 Delay は個々のメッセージを送るのに使われた時間、 Max はメッセージが送られる回数、 SendTo はメッセージが送られる先のPidか名前です。 Delay はタプルの3つ目の要素として渡され、これは timeout が handle_info/2 に Delay ミリ秒後に送られるということを意味します。
上で作ったAPIを使えば、たいていのサーバはかなり素直な実装になります:
%%% OTP Callbacks
handle_call(stop, _From, State) ->
{stop, normal, ok, State};
handle_call(_Msg, _From, State) ->
{noreply, State}.
handle_cast(_Msg, State) ->
{noreply, State}.
handle_info(timeout, {Task, Delay, Max, SendTo}) ->
SendTo ! {self(), Task},
if Max =:= infinity ->
{noreply, {Task, Delay, Max, SendTo}, Delay};
Max =< 1 ->
{stop, normal, {Task, Delay, 0, SendTo}};
Max > 1 ->
{noreply, {Task, Delay, Max-1, SendTo}, Delay}
end;
handle_info(_Msg, State) ->
{noreply, State}.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) -> ok.
ここで handle_info/2 関数の中にいくらか複雑な部分があります。 gen_serverの章 で見たように、時間制限にひっかかったときはいつでも(この場合は Delay ミリ秒後)、 timeout メッセージがプロセスに送られます。 これに基づいて、私たちがメッセージをより多く送らなければいけないのか、それとももう間に合っているのかを知るために、メッセージが何通送られたかを確認します。 このワーカの実装が完了したら、いよいよプロセスプールを実際に試せます!
21.7. プールよ、走れ¶
ようやく、すべてのファイルをコンパイルして、プールで遊ぶことができます。プールの最上位のスーパーバイザを起動しましょう:
$ erlc *.erl
$ erl
Erlang R14B02 (erts-5.8.3) [source] [64-bit] [smp:4:4] [rq:4] [async-threads:0] [hipe] [kernel-poll:false]
Eshell V5.8.3 (abort with ^G)
1> ppool:start_link().
{ok,<0.33.0>}
これから、プールとしてのタスク通知ツールのたくさんの異なる機能を試せます:
2> ppool:start_pool(nagger, 2, {ppool_nagger, start_link, []}).
{ok,<0.35.0>}
3> ppool:run(nagger, ["finish the chapter!", 10000, 10, self()]).
{ok,<0.39.0>}
4> ppool:run(nagger, ["Watch a good movie", 10000, 10, self()]).
{ok,<0.41.0>}
5> flush().
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.39.0>,"finish the chapter!"}
ok
6> ppool:run(nagger, ["clean up a bit", 10000, 10, self()]).
noalloc
7> flush().
Shell got {<0.41.0>,"Watch a good movie"}
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.41.0>,"Watch a good movie"}
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.41.0>,"Watch a good movie"}
...
同期のキューを使わない部分に関してはかなりうまく動いているように見えます。 プールが起動されて、タスクが追加され、メッセージが正しい目的地に送られました。 許可された数より多くのタスクを動かそうとしたら、拒否されました。 片付けをしている時間はありません、ごめんなさい! しかし、他のタスクはまだちゃんと動いています。
Note
ppool は start_link/0 で起動しました。もしシェルでエラーが起きたら、プール全体を落として、再び起動してください。 この問題については次の章で触れます。
Note
もちろん、より実装が綺麗なタスクシステムであれば、おそらくすべての適切なメディアにメッセージを正しく転送するために使われるイベントマネージャを呼び出すことでしょう。 しかしながら、実践では、プロトコルとライブラリは変化しやすく、私はいつもひとたび外部依存のライブラリが旬を過ぎたら読むに値しないものになるような本を嫌っています。 ですから、私はなるべく外部依存のものが比較的少なくなるようにして、できればチュートリアルには全く出ないようにいます。
では、キューイング(非同期)についてもみてみましょう:
8> ppool:async_queue(nagger, ["Pay the bills", 30000, 1, self()]).
ok
9> ppool:async_queue(nagger, ["Take a shower", 30000, 1, self()]).
ok
10> ppool:async_queue(nagger, ["Plant a tree", 30000, 1, self()]).
ok
<wait a bit>
received down msg
received down msg
11> flush().
Shell got {<0.70.0>,"Pay the bills"}
Shell got {<0.72.0>,"Take a shower"}
<wait some more>
received down msg
12> flush().
Shell got {<0.74.0>,"Plant a tree"}
ok
すばらしい! これでキューも動いていますね。 ここではログはすべてが綺麗に表示されているわけではありませんが、ここで起きていることは、最初の2つのリマインダーをなるべく早く起動しようとしています。 それからワーカの上限に達して、3つ目のタスク(木を植える)にはキューが必要になります。 請求を支払う、というタスクが完了したら、木を植えるためのリマインダがスケジュールされ、後ほどメッセージが送られます。
同期のものは異なった動作をします:
13> ppool:sync_queue(nagger, ["Pet a dog", 20000, 1, self()]).
{ok,<0.108.0>}
14> ppool:sync_queue(nagger, ["Make some noise", 20000, 1, self()]).
{ok,<0.110.0>}
15> ppool:sync_queue(nagger, ["Chase a tornado", 20000, 1, self()]).
received down msg
{ok,<0.112.0>}
received down msg
16> flush().
Shell got {<0.108.0>,"Pet a dog"}
Shell got {<0.110.0>,"Make some noise"}
ok
received down msg
17> flush().
Shell got {<0.112.0>,"Chase a tornado"}
ok
ログは自分で試してみたときほどすっきりとはわからないでしょう。(ご自分で試されることをおすすめします) 基本的なイベントの流れは2つのワーカがプールに追加されるというものです。 これら2つのワーカは実行していることを止められることなく、また3つ目のワーカを追加しようとすると、シェルは( nagger という名前のプロセス下の) ppool_serv が、ワーカが落ちたというメッセージを受け取るまで(”received down msg”)ロックされます。 その後、 sync_queue/2 の呼び出しが戻り値を返せるようになり、新しいワーカのPidを教えてくれます。
プール全体を取り除くことが出来ます: We can now get rid of the pool as a whole:
18> ppool:stop_pool(nagger).
ok
19> ppool:stop().
** exception exit: killed
すべてのプールは、 ppool:stop() を呼ぶだけで終了させられますが、大量のエラーメッセージを受け取る事になります。 これは、 ppool_supersup プロセスを正常終了させる(すべての子のプールを次々にクラッシュさせる)のではなく、強制終了したためです。 しかし次の章ではどのように綺麗にプロセスを落とすかについて触れます。
21.8. プール清掃¶
すべてを振り返って見ると、なんとかリソース確保をある程度簡潔な方法で行うプロセスプールを書来ました。 すべてが並行に処理され、制限もかけられ、他のプロセスからも呼び出せました。 クラッシュするアプリケーションの部品も、スーパバイザのおかげで、すべての構造を壊すことなく、透過的に置き換えることができました。 一度、プールアプリケーションが準備できてしまえば、驚くほど大きなリマインダーアプリケーションを、とても少ないコードで書きなおすことができました。
1台のコンピュータでの失敗の隔離も考慮され、並列化が扱われ、いまや非常に堅牢なサーバサイドソフトウェアを作る上で、たとえまだシェルで動作させる良い方法を見ていないとしても、十分に構造化された部品を手にすることができました。
次の章では、どのように ppool アプリケーションをパッケージ化して本当のOTPアプリケーションにし、配布準備を整え、他の製品で使えるようにするかをお見せします。 これまで、私たちはOTPの応用機能に関しては見て来ませんでした。しかし、いまやあなたはOTPとErlang(少なくとも分散に関係しない部分)についての初期の応用的な議論を行う上での最も中心となるものを理解できるレベルにきたと言えるでしょう。 本当にすばらしいことです!