33. 型仕様とErlang¶
33.1. PLTは最高のサンドイッチ¶

型(あるいはそれを欠いています) で、Dialyzerという、Erlangの型エラーを検知するツールを紹介しました。 この翔では、Dialyzerに完全に焦点を当てて、実際にErlangでの型エラーの検知を行う方法やその他の矛盾を検知するためのDialyzerの使い方を紹介します。 なぜDialyzerが作られたかを見ていくことから始めて、その次にその指針となる原則は何か、そして型に関連するエラーを検知する性能、最後にその使い方の例を紹介します。
Dialyzerは、Erlangコードを解析するときに非常に効率的なツールです。 Dialyzerはあらゆる種類の矛盾、例えば1度も実行されないコードを検知するために使われますが、主な用途はErlangコードベース内の型エラーの検知に関することです。
多くを見る前に、DialyzerのPersistent Lookup Table(永続的参照テーブル, PLT)を作成します。これはDialyzerが、利用している標準Erlangディストリビューションの一部や3rdパーティのアプリケーションやモジュールに関して、確認できるすべての情報をコンパイルする作業です。 コンパイルの完了にはかなり長い時間がかかり、特にHiPE経由でのネイティブコンパイルが無いプラットフォーム(つまりWindows)で実行している、あるいは古いバージョンのErlangを使っている場合は、それが顕著です。 幸いにも時代の経過とともに、処理能力は向上していて、Erlangの最新版(執筆時ではR15B02)ではより速く処理するために並行Dialyzerが使えるようになりました。 ターミナルで次のコマンドを入力して、実行した結果がどうなるか見てみましょう:
$ dialyzer --build_plt --apps erts kernel stdlib crypto mnesia sasl common_test eunit
Compiling some key modules to native code... done in 1m19.99s
Creating PLT /Users/ferd/.dialyzer_plt ...
eunit_test.erl:302: Call to missing or unexported function eunit_test:nonexisting_function/0
Unknown functions:
compile:file/2
compile:forms/2
...
xref:stop/1
Unknown types:
compile:option/0
done in 6m39.15s
done (warnings were emitted)
このコマンドでは、私たちが読み込みたいOTPアプリケーションを指定することでPLTを生成しています。 Dialyzerでは型エラーを探しているときには未知の関数を扱うこともできるので、特に必要なければ警告は無視しても構いません。 これから、なぜ、そしていつ型推論のアルゴリズムがうまくいくのかについ議論するのかを、この章の後半で触れます。 Windowsユーザには「DialyzerがデフォルトのPLTの場所を見つけられるように、環境変数 HOME を設定して下さい」というようなエラーメッセージが表示されるかも知れません。 これは、Windowsでは環境変数 HOME が常に設定されているわけではなく、それによってDialyzerがどこにPLTをダンプしていいかわからないためです。 Dialyzerがファイルを置いてもいい場所をこの環境変数に設定しましょう。
必要であれば、 ssl や reltool といったアプリケーションを --apps に続いて追加することもできますし、既にPLTが生成済みであれば、次のように呼び出すこともできます:
$ dialyzer --add_to_plt --apps ssl reltool
PLTに独自のアプリケーションやモジュールを追加したければ、 -r Directories を使えばいいでしょう。このオプションはすべての .erl ファイルや .beam ファイルを探してPLTに追加します。(ただし、 debug_info 付きでコンパイルされている必要があります)
さらに、Dialyzerはどのようなコマンドでも --plt Name オプションを使うことでいくつでもPLTを生成することができ、また特定のPLTを指定することもできます。 また、互いに素なPLT、つまりお互いに共通のモジュールがまったくないPLTをたくさん作った場合には、 --plts Name1 Name2 ... NameN とすることで、それらを「マージ」することができます。 これはシステム内で異なるプロジェクトあるいは異なるErlangバージョンのために異なるPLTを作りたい時に便利です。 この機能の欠点は、マージされたPLTから得られる情報ははじめから1ファイルとして生成されたPLTほど正確ではないということです。
先ほど実行したPLTのビルドがまだ走っている間に、Dialyzerが型エラーを検知する仕組みについて詳しくなりましょう。
33.2. 成功型付け(Success Typing)¶
たいていの他の動的プログラミング言語ではよくあることですが、Erlangプログラムは常に型エラーで苦しむリスクがあります。 あるプログラマ、たとえばあなたがある引数をある関数に渡し、テストを正しく書いていなかったとします。 プログラムがデプロイされて、すべてがうまくいっているように見えます。 そして朝4時に、ソフトウェアの一部が繰り返しクラッシュして、あなた引き起こしたミスによる負荷にスーパバイザが耐え切れないと、会社の運用担当の携帯が鳴らされるのです。

翌朝、あなたはオフィスに着くと、あなたが仕事のスケジュールをめちゃくちゃにしたことにうんざりした運用担当者が、コンピュータが再フォーマットし、社用車には鍵がかけ、コミット権限は剥奪していたことに気がつくでしょう。
この大失敗は、実行前にプログラムを検証する静的型解析があるコンパイラで防げたはずです。 Erlangは他の動的言語ほど型システムを切望していませんが、ランタイムエラーに対する反応的な手法によって、通常早期の型関連のエラーの検知によってもたらされる追加の型安全性から利益を得ることは、間違いなく素晴らしいことです。
通常、静的型システムがある言語はそのように設計されています。 言語のセマンティクスは、その型システムが許可することしないことに強く影響を受けています。 たとえば、次のような関数を考えます:
foo(X) when is_integer(X) -> X + 1.
foo(X) -> list_to_atom(X).
大抵の型システムでは、上のような関数の型を正しく表現する事ができません。 型システムから見たら、その関数は整数またはリストを受け取り、整数またはアトムを返すように見えますが、関数の入力の型と出力の型の依存関係までは辿ってくれません。(条件型や交差型ではできますが、冗長になる可能性があります) つまり、Erlangではごく普通なこのような関数を書くと、これらの関数がコード内で後ほど使われるときに、型解析においてはなにかしらの不確実性をもたらすことになります。
一般的に言って、解析器は、数学的に証明されるように、実際にランタイムに型エラーがない状態であることを証明したいのです。 つまり、いくつかの状況で、型チェッカーが特定の実用的に正しい操作を、クラッシュを引き起こしかねない不確実性を取り除くために無効にしているということです。
このような型システムを実装することは、Erlangにセマンティクスを変更させることをほぼ意味しています。 問題は、Dialyzerが登場するまでに、Erlangは広く大きなプロジェクトで既に使われていたことです。 Dialyzerのようなツールが受け入れられるためには、Erlangの哲学を尊重する必要があります。 もしErlangが型に関してランタイムにだけ解決されるまったく無意味な状態を許可しているのであれば、そのままの状態にさせておくべきです。 型チェッカーにはその状態に関して文句を言う資格はありません。 自分のプログラムがプロダクション環境で既に数ヶ月稼働しているのに、そのプログラムは実行できないなどと言ってkるツールを好きになるプログラマなどいないでしょう。
他の選択肢は、エラーが無いことを証明するのではなく、エラーを可能な限り見つける型システムを持つことです。 このような検出器をうまく作ることは可能ですが、完璧にはなりえません。 これはトレードオフです。
したがってDialyzerの型システムは、プログラムが型に関してエラーが無いことを証明するのではなく、実世界において矛盾が起きないようにできるだけ多くのエラーを検出するにとどまるようにすることに決めました:
私たちの主な目的は、Erlangコード内の暗黙的な型情報を明らかにして、プログラム上で明示的に利用できるようにすることです。 典型的なErlangアプリケーションのサイズを考えると、型推論は完全に自動で行われるべきですし、言語の操作性セマンティクスを誠実に尊重すべきです。 さらに、型推論によって一切のコードを書き直しを無理強いするべきではありません。 その理由は単純です。 書き直しは、しばしば安全性に関して致命傷になり、何十万行にもなるコードからなるアプリケーションが型推論を満たすためだけにそれを行うのは、大きな成功を得るための選択肢にはなりえません。 しかしながら、大きなソフトウェアアプリケーションは維持されなければならず、それもしばしば元の作者とは別の人がそれを行わなけれbなりません。 既に存在している型情報を自動的に明らかにすることによって、プログラムとともに発達し、かつ古くなってしまうことのないドキュメントを自動で生成できます。 また私たちは正確さと可読性のバランスを保つことも重要だと思っています。 最後に一番大事なことは、推論された型は決して間違ってはいけないということです。
Dialyzerの根拠となっている Success Typingsの論文 が説明するように、Erlangのような言語の型チェッカーは(ヒントがあるのはいいですが)型宣言なしでも動作すべきで、簡潔で可読性が高く、言語に適用し(言語が適用してはいけません)、クラッシュすることが確実にわかる型エラーのみをエラーを表示すべきです。
したがって、Dialyzerはすべての関数が正しく動作しているという楽観的な推測から解析を開始します。 Dialyzerはプログラム内の関数がすべてきちんと動作していて、すべての入力を受け入れ、できるだけあらゆる出力を返しているとみなします。 未知の関数がどのように使われていても、それは良い使われ方をされているとみなします。 これがPLTを生成するときに、未知の関数に関する警告があまり意味が無いといった理由です。 それらはちゃんと動いているのです。型推論においてはDialyzerは生まれつきの楽天家なのです。
解析が進むにつれ、Dialyzerはあなたの書いた関数をより深く知っていきます。 深く知るにつれ、Dialyzerはコードを解析が進み、いくつか面白いことを理解しだします。 たとえば、ある関数にはその両引数の間に + の演算子があって、加算の値を返すとします。 ここでDialyzerは、この関数がどんな引数も受け付け、どんな返り値でも返せるとは推測せず、引数は数字で(整数か浮動小数点数の値)、返り値は同様に数字だと推測するでしょう。 この関数はこの事実に関連した、2つの数字を受け取り1つの数字を返す、という基本的な型を持つことになります。
今度は、ある関数が、いま説明した関数をアトムと数字を引数に取って呼び出したとしましょう。 Dialyzerはコードを考えて、「ちょっと待って、アトムと数字を + 演算子に使うことはできないよ!」といいます。 そして、Dialyzerは、さっきは数字を返すと分かった関数があらゆる返り値を返せるはずがないということで、パニックになってしまいます。
しかし、一般的には、ときにはエラーを起こすとわかっている多くのコードに関してDialyzerは警告しないままでいるでしょう。 次のようなコードを例に考えてみましょう:
main() ->
X = case fetch() of
1 -> some_atom;
2 -> 3.14
end,
convert(X).
convert(X) when is_atom(X) -> {atom, X}.
このコードは fetch/0 関数という 1 または 2 を返す関数の存在を想定しています。 この事実に基づいて、アトムまたは浮動小数点数を返します。
そう考えると、そのうちいつか convert/1 を呼び出すと失敗すると分かるでしょう。 fetch() が 2 を返すときはいつでも、浮動小数点数を convert/1 に渡すため、型エラーが起きると予測できます。 Dialyzerは楽観的だ、ということを覚えておいて下さい。 Dialyzerはあなたのコードを具象的に信用していて、 convert/1 を呼び出しても成功する可能性があるのであれば、Dialyzerは沈黙したままでいるでしょう。 この場合型エラーは1つも報告されません。
33.3. 型推論と矛盾¶
先に触れた原則の実践的な例のために、いくつかのモジュールでDialyzerを試してみましょう。 モジュールは discrep1.erl 、 discrep2.erl 、 discrep3.erl の3つです。 これらのファイルは徐々に進化しています。 まず最初の1つです:
-module(discrep1).
-export([run/0]).
run() -> some_op(5, you).
some_op(A, B) -> A + B.
ここで起きるエラーは明らかなものです。 5 を you というアトムと加算出来ません。 すでにPLTは生成済みという前提で、このコードにDialyzerをかけてみましょう:
$ dialyzer discrep1.erl
Checking whether the PLT /home/ferd/.dialyzer_plt is up-to-date... yes
Proceeding with analysis...
discrep1.erl:4: Function run/0 has no local return
discrep1.erl:4: The call discrep1:some_op(5,'you') will never return since it differs in the 2nd argument from the success typing arguments: (number(),number())
discrep1.erl:6: Function some_op/2 has no local return
discrep1.erl:6: The call erlang:'+'(A::5,B::'you') will never return since it differs in the 2nd argument from the success typing arguments: (number(),number())
done in 0m0.62s
done (warnings were emitted)
おお、すごい、Dialyzerはエラーの場所を見つけました。 これは一体何を意味してるんでしょうか。 1つ目は、Dialyzerを使っていると何度も見るエラーです。 ‘Function Name/Arity has no local return’ は、その関数が呼んでいる関数の内1つがDialyzerの型エラー検知器によって捕捉されたり、あるいは例外をなげたために、返り値を何も返さないときに出力される、Dialyzerの一般的な警告です。 このようなことが起きた場合に、関数が返しうる値は空です。実際に値を返しません。 このエラーは、この関数を呼び出した関数まで伝搬し、 ‘no local return’ というエラーを返します。
2つ目のエラーはもう少しわかりやすいものです。 some_op(5, 'you') を呼び出すと、Dialyzerが関数が動作する上で必要だと判断した型と食い違うと言っていて、Dialyzerが期待した型は (number() and number()) だと言っています。 この型記法はいまはまだ見慣れないものですが、すぐ後で詳しく説明します。
3つ目のエラーは、ふたたび no local return です。 最初のエラーでは some_op/2 が失敗しそうだから起きたもので、こちらの場合は、 + を呼び出すとが失敗しそうなので起きました。 そしてこれが4つ目と最後のエラーが説明しているものです。 加算演算子(実際には erlang:'+'/2 )は数字 5 をアトム you に加えることはできません。
では discrep2.erl はどうでしょうか。ソースコードはこうなっています:
-module(discrep2).
-export([run/0]).
run() ->
Tup = money(5, you),
some_op(count(Tup), account(Tup)).
money(Num, Name) -> {give, Num, Name}.
count({give, Num, _}) -> Num.
account({give, _, X}) -> X.
some_op(A, B) -> A + B.
このファイルにDialyzerをかけると、先ほどと似たエラーが表示されます:
$ dialyzer discrep2.erl
Checking whether the PLT /home/ferd/.dialyzer_plt is up-to-date... yes
Proceeding with analysis...
discrep2.erl:4: Function run/0 has no local return
discrep2.erl:6: The call discrep2:some_op(5,'you') will never return since it differs in the 2nd argument from the success typing arguments: (number(),number())
discrep2.erl:12: Function some_op/2 has no local return
discrep2.erl:12: The call erlang:'+'(A::5,B::'you') will never return since it differs in the 2nd argument from the success typing arguments: (number(),number())
done in 0m0.69s
done (warnings were emitted)
この解析の間に、 count/1 と account/1 の各関数の型を理解することができます。 タプルの各要素の型を推測して、それらが渡している渡す値を把握しています。 そして再び問題なくエラーを探すことができます。
discrep3.erl で、もう少し深く見てみましょう:
-module(discrep3).
-export([run/0]).
run() ->
Tup = money(5, you),
some_op(item(count, Tup), item(account, Tup)).
money(Num, Name) -> {give, Num, Name}.
item(count, {give, X, _}) -> X;
item(account, {give, _, X}) -> X.
some_op(A, B) -> A + B.
このバージョンでは、さらに間接的な部分を増やしています。 countとaccountという値に明示的に定義された関数を定義する代わりに、アトムを使って異なる関数節を切り替えることで動作しています。 これでDializerを走らせると、次のような出力が得られます:
$ dialyzer discrep3.erl
Checking whether the PLT /home/ferd/.dialyzer_plt is up-to-date... yes
Proceeding with analysis... done in 0m0.70s
done (passed successfully)

あらら。 この変更は複雑すぎて、Dialyzerは型定義を判断できなかったようです。 しかし、エラーは依然として残ったままです。 後ほど、なぜDialyzerがこのファイル内のエラーを見つけられなかったのかを理解し、その修正の仕方について見ていきますが、いまはもう少しDialyzerのかけ方について見てみましょう。
たとえば、Process Questのリリースに対してDialyzerをかけたい時は、次のように実行すればよいでしょう:
$ cd processquest/apps
$ ls
processquest-1.0.0 processquest-1.1.0 regis-1.0.0 regis-1.1.0 sockserv-1.0.0 sockserv-1.0.1
大量のライブラリがありました。 Dialyzerは同名のモジュールが大量にある状態を好みませんので、手動でディレクトリを指定する必要があります:
$ dialyzer -r processquest-1.1.0/src regis-1.1.0/src sockserv-1.0.1/src
Checking whether the PLT /home/ferd/.dialyzer_plt is up-to-date... yes
Proceeding with analysis...
dialyzer: Analysis failed with error:
No .beam files to analyze (no --src specified?)
いいですね。 デフォルトでは、Dialyzerは .beam ファイルを探します。 解析に .erl ファイルを使う必要がある場合は、Dialyzerに --src フラグでその旨を伝える必要があります:
$ dialyzer -r processquest-1.1.0/src regis-1.1.0/src sockserv-1.0.1/src --src
Checking whether the PLT /home/ferd/.dialyzer_plt is up-to-date... yes
Proceeding with analysis... done in 0m2.32s
done (passed successfully)
リクエストすべてに対して src ディレクトリを指定したのにお気づきでしょうか。 src ディレクトリを指定しなくてもDialyzerは実行できますが、その場合はEUnitテストに関する大量のエラーを吐くことになります。これはコード解析におけるアサーションマクロの動作に関係しています。その動作に関しては特に気にする必要はありません。 加えて、障害に関するテストをするために意図的にクラッシュをさせているときには、Dialyzerはそれを拾ってしまいます。このような動作は邪魔なので、先ほどのように src ディレクトリを指定するのです。
33.4. 型の種類についてタイプする¶
discrep3.erl で見たように、Dialyzerは時々、私たちが意図するように、すべての型を推測することはできません。 その理由はDialyzerが私たちの心を読むことが出来ないからです。 我らがDialyzerの処理を助けるために(そして私たち自身を助けるために)型を宣言して関数の型ヒント(アノテーション)を加えることで、ドキュメントの追加と私たちが暗黙的に期待する型を形式化ができます。
Erlangの型は、例えば数字の42であれば、 42 と書けばそれが型となり(通常と何も変わりません)、アトムであれば cat や molecule というアトムそれ自身が型となります。 これらは値自身を参照しているため、シングルトン型と呼ばれます。 次のようなシングルトン型が存在します:
| ‘some atom’ | あらゆるアトムは固有のシングルトン型になります |
| 42 | 整数 |
| [] | 空リスト |
| {} | 空タプル |
| <<>> | 空バイナリ |
これらの型だけでErlangのプログラムを書くのは非常に面倒でしょう。 たとえば年齢、あるいは「すべての整数」というようなものを表現するのに、シングルトン型を使って表現する方法はありません。 そして、一度にたくさんの型を指定できたとしても、「あらゆる整数」のようなものを手ですべて書くのはひどく鬱陶しい、もしくはもはや不可能ですらあります。
このような状況から、Erlangには 直和型 があり、これによって、2つのアトムとビルトイン型を持つ型を表現する事ができます。ビルトイン型は事前定義で、必ずしも自分で定義することが出来るものではなく、また一般的に便利なものです。 直和型とビルトイン型は一般的に似た構文を持っていて、 TypeName() という形式で記述されます。 たとえば、あらゆる整数を表す型は、 integer() と記述できます。 括弧が使われている理由は、たとえばすべてのアトムを表す atom() 型と、特定のアトム atom を区別するためです。 さらに、コードをより綺麗にするために、多くのErlangプログラマは型宣言の中にあるすべてのアトムに引用符を付けるでしょう。たとえば atom ではなく 'atom' といった具合です。 これによって、 'atom' がシングルトン型を意図し、括弧を忘れてしまうビルトイン型ではないことを明示的に示すことができます。
次の表は、Erlangによって提供されているビルトイン型が一覧です。 すべてが直和型と同じ構文ではないということに留意して下さい。 たとえば、バイナリやタプルは、より使いやすくするような特別な構文を持っています。
| any() | すべてのErlang項です |
| none() | これは、すべての項や型が妥当でないことを意味する特別な方です。 通常、関数の返り値が none() だとしてDialyzerが詰まってしまう場合は、関数はおそらくクラッシュするということ意味します。 この型は「これは動作しません」という意味の同義語です。 |
| pid() | プロセス識別子です |
| port() | ポートはファイルディスクリプタ(Erlangライブラリの内部の奥深くまで見に行かないと滅多に見ることはないもの)、ソケット、あるいは一般的に erlang:open_port/2 関数のようにErlangに外部とのやりとりを許可するものの下層にあるものです。 Erlangシェルでは、 #Port<0.638> のように表示されます。 |
| reference() | make_ref() や erlang:monitor/2 で返される一意な値です |
| atom() | アトムの総称です |
| binary() | バイナリデータ全般です |
| <<_:Integer>> | 特定のサイズのバイナリで、 Integer はサイズを表します。 |
| <<_:_*Integer>> | 特定のユニットサイズで、長さは指定されていないバイナリです |
| <<_:Integer, _:_*OtherInteger>> | 上記2つの組み合わせで、バイナリの最小の長さを指定する形式です |
| integer() | すべての整数です |
| N..M | 整数の範囲です。たとえば、月を表したい場合は、 1..12 という範囲で指定できます。 Dialyzerにはこの範囲を広げる権利を持っています。 |
| non_neg_integer() | 非負整数です |
| pos_integer() | 自然数です |
| neg_integer() | 負の整数です |
| float() | 浮動小数点数です |
| fun() | 関数です |
| fun((...) -> Type) | 引数のアリティが決まっていない、特定の型を返す、無名関数です。 リストを返す関数は fun((...) -> list()) と記述できます。 |
| fun(() -> Type) | 引数がなく、特定の型を返す無名関数です。 |
| fun((Type1, Type2, ..., TypeN) -> Type) | 特定の型で特定の数の引数を取り、特定の型を返す、無名関数です。 例として、整数と浮動小数点数を引数にとる関数は、次のように宣言できます。 fun((integer(), float()) -> any()) |
| [] | 空リストです |
| [Type()] | 特定の型の要素を持つリストです。 整数のリストは [integer()] で定義されます。 他にも list(Type()) と書くこともできます。 リストはときどき非真正な形(たとえば [1, 2 | a] )になります。 そのような場合は、Dialyzerでは非真正リストを表す improper_list(TypeList, TypeEnd) という型宣言ができます。 非真正リスト [1, 2 | a] は improper_list(integer(), atom()) と型を指定できます。 複雑な表現をしようと思った場合には、リストが真正かどうかわからないことがあります。 そのような場合には、 maybe_improper_list(TypeList, TypeEnd) を使うことができます。 |
| [Type(), ...] | [Type(), ...] という特別な形式で、リストが空でないことを表現できます |
| tuple() | タプルです |
| {Type1, Type2, ..., TypeN} | 各要素の型がわかっているタプルです。 たとえば、二分木のノードで {'node', LeftTree, RightTree, Key, Value} に対応するものは {'node', any(), any(), any(), any()} と定義できます。 |
上記のようなビルトイン型を元に、自分のErlangプログラム用に型を定義することが簡単になります。 それでもいくつかの機能は足りていませんが。 私たちの要求に対して曖昧すぎたり、不適切であったりするかもしれません。 discrepN モジュールのエラーで number() 型について触れているものを覚えているでしょうか。 あの型はシングルトン型でなければ、ビルトイン型でもありませんでした。 したがって共用型となり、これは自分で定義できます。
直和型の表現はパイプ( | )を使って記述できます。 基本的に TypeName という名前の型を直和型として Type1 | Type2 | ... | TypeN で表わせます。 このようなことから、整数と浮動小数点数を含む number() 型は、 integer() | float() と表現できます。 真偽値は、 'true' | 'false' と定義できます。 他の型が1つだけ使われている型を定義することもできます。 見た目は直和型ですが、実質はエイリアスです。
事実、このようなエイリアスや直和型が事前定義されています。 いくつか紹介します:
| term() | これは any() と同等です。他のツールでかつて term() を使っていために追加されました。 他にも _ 変数が term() と any() のエイリアスとして使えます。 |
| boolean() | 'true' | 'false' |
| byte() | 0..255 として定義されています。これは存在する妥当なバイトの定義です。 |
| char() | 0..16#10ffff として定義されていますが、この型が特定の文字標準を参照しているかは不明です。 これは衝突を避けるための広く汎用的な手法です。 |
| number() | integer() | float() |
| maybe_improper_list() | これは一般的な非真正リストである maybe_improper_list(any(), any()) のエイリアスです。 |
| maybe_improper_list(T) | T は型です。これは maybe_improper_list(T, any()) のエイリアスです。 |
| string() | 文字列は [char()] と、文字のリストとして定義されています。 nonempty_string() もあり、これは [char(), ...] と定義されています。 悲しいことに、バイナリ文字列のみを表す文字列型はありませんが、それは好きな型に解釈できるblobデータ型があるからです。 |
| iolist() | 古き良きioリストです。 これは maybe_improper_list(char() | binary() | iolist(), binary() | []) と定義されています。 ioリスト自身がioリストの項内で定義されていますね。 DialyzerはR13B04から再帰型をサポートしています。 それ以前は再帰型は使えなかったので、ioリストのような型は辛い試練の末にのみ定義できました。 |
| module() | これはモジュール名を表す型で、現状は atom() のエイリアスです。 |
| timeout() | non_neg_integer() | 'infinity' |
| node() | Erlangのノード名、つまりアトムです。 |
| no_return() | これは none() のエイリアスで、関数の返り値の型として使うよう意図されたものです。 特に(可能な限り)無限ループをするような場合には、決して値が返ることがないので、この型を使います。 |
すでにいくつか型を作って来ました。 先ほど、二分木の型を {'node', any(), any(), any(), any()} と表現しました。 さて、これで型について少し分かってきたので、モジュール内で宣言してみましょう。
モジュール内での型宣言は次のような構文です:
-type TypeName() :: TypeDefinition.
したがって、二分木の型は次のように定義されます:
-type tree() :: {'node', tree(), tree(), any(), any()}.
あるいは、特別な構文として型コメントのために変数名を使うこともできます:
-type tree() :: {'node', Left::tree(), Right::tree(), Key::any(), Value::any()}.
しかし、この定義ではうまくいきません。理由は、空の二分木が作れないからです。 再帰的に考えることによって、 再帰 の章で tree.erl の中で行ったように、より良い二分木の定義を行うことができます。 そこでは、空の二分木は {node, 'nil'} と定義されていました。 再帰関数の中でこのようなノードに当たったときは、再帰を止めます。 通常の空でないノードは {node, Key, Val, Left, Right} と記述されます。 これを型に直すと、次のような形式で二分木のノードの型を定義できます:
-type tree() :: {'node', 'nil'}
| {'node', Key::any(), Val::any(), Left::tree(), Right::tree()}.
これで、空ノードと空でないノードのどちらも持てる二分木の型を定義できました。 このコードを書く上で、まだ触れて来なかった内容がありました。 {'node', 'nil'} の代わりに 'nil' を使うことも出来たはずで、Dialyzerもそれをきちんと処理できたはずです。 これは単に、先に書いた二分木のモジュールでの書き方に倣っただけです。
ではレコードはどう型定義したらいいでしょうか。 レコードでは型宣言をするのに便利な構文があります。 早速 #user{} レコードを考えながら、その構文を見てみましょう。 ユーザ名と、メモ書き(ここで tree() 型を使います)、年齢、友達のリスト、略歴を保存したいとします。
-record(user, {name="" :: string(),
notes :: tree(),
age :: non_neg_integer(),
friends=[] :: [#user{}],
bio :: string() | binary()}).
一般的なレコードの型宣言は Field :: Type で行い、デフォルト値がある場合には Field = Default :: Type と書きます。 いま書いたレコードでは、ユーザ名は文字列で、メモ書きが二分木、年齢は0以上無制限の整数(だれが年齢に上限を設けられるでしょうか!)です。 面白いフィールドは friends です。 [#user{}] 型は、userレコードが他のuserレコードを要素として持つレコードを保持できるということです。 またレコードはその型を #RecordName{} と書けるということも分かりました。 略歴は文字列またはバイナリです。
さらに、型宣言や型定義を統一した形式にするために、 -type Type() :: #Record{}. というエイリアスを追加することがしばしばあります。 friends の定義は user() 型を使って変更でき、最終的にレコードは次のように変更できます:
-record(user, {name = "" :: string(),
notes :: tree(),
age :: non_neg_integer(),
friends=[] :: [user()],
bio :: string() | binary()}).
-type user() :: #user{}.
ここで、レコードのすべてのフィールドに型を定義したけれど、そのうちいくつかにはデフォルト値がないことがお分かりでしょう。 #user{age=5} のようなuserレコードインスタンスを作っても、型エラーにはなりません。 レコードのフィールドの型定義では、デフォルト値が提供されなかった場合には、暗黙的に 'undefined' が直和されています。 昔のバージョンでは、このような宣言でも型エラーが起きていました。
33.5. 関数を型付けする¶
四六時中型を定義して、ファイルを片っ端から型宣言を追加して、ファイルを表示して、達成感に浸ることはできますが、これらの型情報はDialyzerの型推論エンジンに自動的に読み込まれません。 Dialyzerは実行可能性を判断するために、あなたが宣言した型から判断するわけではありません。
では一体全体なぜこのような型宣言をするのでしょうか。 ドキュメントのためでしょうか。ある部分はそうです。 Dialyzerにあなたが宣言した型を理解させるには、さらに手順があります。 型シグネチャ宣言をすべての関数に対して書き、モジュール内の関数の型宣言に橋渡しをしてあげる必要があります。
これまで、この章では「ここに、こういう構文があります」というような話に終始していました。しかし、もうそろそろ実践的な話をする段階に来ました。 型付けが必要なものの単純な例としてはトランプがあります。 トランプには4つのスートがあり、それぞれスペード、クラブ、ハート、ダイヤとなっています。 カードは1から10まで(エースは1)番号が振られ、さらにジャック、クイーン、キングがあります。
通常は、おそらくカードを {Suit, CardValue} と表現して、スペードのエースを {spades, 1} と表すでしょう。 いまは、とりあえずで決めてしまうのではなく、まず型を定義しましょう:
-type suit() :: spades | clubs | hearts | diamonds.
-type value() :: 1..10 | j | q | k.
-type card() :: {suit(), value()}.
suit() 型は単純にスートを表す4つのアトムの直和です。 値は1から10まで( 1..10 )または絵札の j 、 q 、 k となります。 card() 型はスートと値をまとめるタプルです。
これら3つの型が通常の関数内でカードの表現に使われて、ある一定の保証をしてくれます。 例として次の cards.erl モジュールを見てみましょう:
-module(cards).
-export([kind/1, main/0]).
-type suit() :: spades | clubs | hearts | diamonds.
-type value() :: 1..10 | j | q | k.
-type card() :: {suit(), value()}.
kind({_, A}) when A >= 1, A =< 10 -> number;
kind(_) -> face.
main() ->
number = kind({spades, 7}),
face = kind({hearts, k}),
number = kind({rubies, 4}),
face = kind({clubs, q}).
kind/1 関数はカードが絵札か数字のカードか返します。 スートはまったくチェックされていないことに気がつくでしょう。 main/0 関数では、3つ目の関数呼び出しでルビーというスートを使っていることが分かります。これは明らかに私たちの型宣言では意図していないもので、おそらく kind/1 関数でも予期していないものです:
$ erl
...
1> c(cards).
{ok,cards}
2> cards:main().
face
すべてうまく動いてしまいました。 そしてそうあってはいけないものです。 Dialyzerを走らせても何もしてくれていません。 しかし、次のような型シグネチャを kind/1 関数に追加するとどうでしょう:
-spec kind(card()) -> face | number.
kind({_, A}) when A >= 1, A =< 10 -> number;
kind(_) -> face.
するとなにか面白いことが起きます。 しかしDialyzerを走らせる前に、まずこれがどう処理されるかをお伝えしましょう。 型シグネチャは -spec FunctionName(ArgumentTypes) -> ReturnTypes. という形式を採ります。 上の仕様では、 kind/1 関数は上で定義した card() 型を引数に取ると言っています。 また関数はアトム face または number を返すとも言っています。
このモジュールにDialyzerを走らせると、次のような出力が得られます:
$ dialyzer cards.erl
Checking whether the PLT /home/ferd/.dialyzer_plt is up-to-date... yes
Proceeding with analysis...
cards.erl:12: Function main/0 has no local return
cards.erl:15: The call cards:kind({'rubies',4}) breaks the contract (card()) -> 'face' | 'number'
done in 0m0.80s
done (warnings were emitted)
楽しいですね。 kind/1 をルビーというスートを持つ「カード」で呼び出すことが仕様に沿っていないため不適切だそうです。
この場合、Dialyzerは私たちが与えた型シグネチャを配慮しています。そして、 main/0 関数を解析するときは、そこに kind/1 を誤って使っているところがあると判断します。 これは15行目( number = kind({rubies, 4}), )であると警告を表示しています。 それからDialyzerは型シグネチャは信頼できるものとして、またコードはそれに準拠して書かれていると想定して、このコードが不適切だと判断します。 この規約違反は main/0 関数まで伝搬しますが、なぜ失敗したかに関しては触れられません。 ただ失敗することだけが伝わるだけです。
Note
Dialyzerは、型仕様が定義されないと、仕様に関するこを警告をできません。 型シグネチャが追加される前は、Dializerは kind/1 が card() 型の引数のみを受け付けるということを想定できませんでした。 シグネチャがあることで、型定義を利用することが出来るのです。
さらに型付けが面白い関数が、次の convert.erl にあります:
-module(convert).
-export([main/0]).
main() ->
[_,_] = convert({a,b}),
{_,_} = convert([a,b]),
[_,_] = convert([a,b]),
{_,_} = convert({a,b}).
convert(Tup) when is_tuple(Tup) -> tuple_to_list(Tup);
convert(L = [_|_]) -> list_to_tuple(L).
コードを読むと、最後の2つの convert/1 の呼び出しが失敗することは明白です。 この関数はリストを受け取ってタプルを返す、あるいはタプルを受け取ってリストを返します。 しかしDialyzerを走らせても、エラーを見つけてくれません。
これはDialyzerが次のような型シグネチャを推論しているからです:
-spec convert(list() | tuple()) -> list() | tuple().
あるいは言葉で表すと、この関数はリストかタプルを受け取って、リストかタプルを返すということです。 言っていることは正しいのですが、悲しいことに少々幅が広すぎます。 この関数は型シグネチャが示すほど寛容ではありません。 このような例が、Dialyzerが傍観し口出ししすぎず、問題を100%言及しないようにしている部分です。
Dialyzerをもう少し助けるために、もうちょっと分かりやすい型宣言を定義できます:
-spec convert(tuple()) -> list();
(list()) -> tuple().
convert(Tup) when is_tuple(Tup) -> tuple_to_list(Tup);
convert(L = [_|_]) -> list_to_tuple(L).
1つの直和内に tuple() 型と list() 型を一緒に入れるのではなく、この構文で選択的な節を持つ型シグネチャを定義できます。 convert/1 をタプルを取って呼び出すと、リストが返ってくることが期待し、またその逆も期待します。
このより細かな情報によって、Dialyzerはより面白い結果を返すことができます:
$ dialyzer convert.erl
Checking whether the PLT /home/ferd/.dialyzer_plt is up-to-date... yes
Proceeding with analysis...
convert.erl:4: Function main/0 has no local return
convert.erl:7: The pattern [_, _] can never match the type tuple()
done in 0m0.90s
done (warnings were emitted)
やりました、エラーを見つけました。 成功です! これでDialyzerに私たちが知っている情報を言わせるところまでできるようになりました。 もちろん、そう言ってしまうと役立たずに聞こえますが、関数を正しく型付けすれば、ちょっとした間違いをして確認を怠っていたとしても、Dialyzerがそれを教えてくれます。このほうが、あなた(あるいはあなたの車に鍵をかけた運用担当者)に徹夜させるエラーログシステムよりもずっといいでしょう。
Note
複数の節がある型シグネチャを使うときに次のような構文のより好む人もいます:
-spec convert(tuple()) -> list()
; (list()) -> tuple().
意味は全く一緒ですが、セミコロンを次の行に書くことでより可読性が上がります。 この文章を書いている今現在は、広く普及した標準の書き方は特に定まっていません。
型定義と型仕様を使うことに酔って、実際にDialyzerに先ほど書いた discrep モジュールのエラーを見つけさせることができました。 discrep4.erl でどうやっているか、見てみましょう。
33.6. 型付けの慣習¶
私は、First In, First Out (FIFO)の操作のために、キューモジュールを書き続けています。 Erlangのメールボックスはキューであるということを知った上で、キューとは何か知っておくべきです。 最初に追加された要素は(選択的に受信をしない限り)最初に取り出されます。 すでに何度か観たように、このモジュールは次の図で説明されるような動作をします:
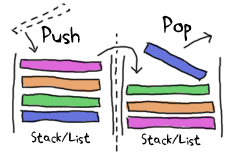
キューをシミュレートするために、スタックとして2つのリストを使います。 1つは新しい要素を保存して、もう1つはキューから要素を削除するために使います。 常に同じリストに要素を追加し、常にもう一方のリストから削除します。 削除するためのリストが空になった場合は、要素を追加する方のリストを逆順にして、そちらが削除する側のリストとなります。 一般的に、1つのリストだけで追加と削除を行うよりも、こちらの方が平均のパフォーマンスが良くなります。
私のモジュールはこうなっています。Dialyzerで確認するために型シグネチャもいくつか追加しています:
-module(fifo_types).
-export([new/0, push/2, pop/1, empty/1]).
-export([test/0]).
-spec new() -> {fifo, [], []}.
new() -> {fifo, [], []}.
-spec push({fifo, In::list(), Out::list()}, term()) -> {fifo, list(), list()}.
push({fifo, In, Out}, X) -> {fifo, [X|In], Out}.
-spec pop({fifo, In::list(), Out::list()}) -> {term(), {fifo, list(), list()}}.
pop({fifo, [], []}) -> erlang:error('empty fifo');
pop({fifo, In, []}) -> pop({fifo, [], lists:reverse(In)});
pop({fifo, In, [H|T]}) -> {H, {fifo, In, T}}.
-spec empty({fifo, [], []}) -> true;
({fifo, list(), list()}) -> false.
empty({fifo, [], []}) -> true;
empty({fifo, _, _}) -> false.
test() ->
N = new(),
{2, N2} = pop(push(push(new(), 2), 5)),
{5, N3} = pop(N2),
N = N3,
true = empty(N3),
false = empty(N2),
pop({fifo, [a|b], [e]}).
キューを {fifo, list(), list()} という形式のタプルで定義しました。 ここで、 fifo() 型を定義しなかったことにお気づきでしょうか。その理由は主に、空のキューと要素があるキューに対する異なる節を簡単に作成できるようにしたかっただけです。
Note
pop/1 関数内で、関数節で1つ erlang:error/1 を呼び出しているにも関わらず、関数シグネチャで none() 型を指定していなかった事に気がつくでしょう。
none() 型は、先に触れたように、関数の返り値がない状態を指します。 もし関数が失敗するか返り値を返す場合は、ある値と none() の両方を返すように定義しても意味がありません。 none() 型は常に想定されていて、したがって直和の Type() | none() は Type() だけを書いた場合と同様に扱われます。
none() が保証される状況とは、呼び出した時に常に失敗する関数を書いているときで、たとえば erlang:error/1 を自分で実装している場合などです。
いま、上のコードですべての型仕様がつじつまが合っています。 コードレビュー中に、確認のために、Dialyzerを実行して、結果を見てみます:
$ dialyzer fifo_types.erl
Checking whether the PLT /home/ferd/.dialyzer_plt is up-to-date... yes
Proceeding with analysis...
fifo_types.erl:16: Overloaded contract has overlapping domains; such contracts are currently unsupported and are simply ignored
fifo_types.erl:21: Function test/0 has no local return
fifo_types.erl:28: The call fifo_types:pop({'fifo',nonempty_improper_list('a','b'),['e',...]}) breaks the contract ({'fifo',In::[any()],Out::[any()]}) -> {term(),{'fifo',[any()],[any()]}}
done in 0m0.96s
done (warnings were emitted)
私ってばかですねえ。 たくさんのエラーが出てきました。 ちくしょう、これは簡単に意味がわかるものじゃないぞ。 2つめのエラー ‘Function test/0 has no local return’ は少なくとも先ほど見たので対処法はわかっています。–とりあえずこれはすぐ消えるので、飛ばしてしまいましょう。
さて、まず1つ目のエラーに注目してみましょう。これはオーバーラップドメインの規約に関する部分です。 fifo_types の16行目をみると、次のように書かれています:
-spec empty({fifo, [], []}) -> true;
({fifo, list(), list()}) -> false.
empty({fifo, [], []}) -> true;
empty({fifo, _, _}) -> false.
それで、どの部分がオーバーラップドメインと言われているのでしょうか。 数学の定義域(domain)と像(image)の概念を参照しなければなりません。 簡単に言うと、定義域というのは関数の入力値が取りうるすべての値で、像というのは関数の出力値の取りうるすべての値です。 したがって、オーバーラップドメインは2つの入力値の集合が重なっている部分を指します。

この問題の原因を探すためには、 list() を見なければいけません。 少し前にあった大きな表を覚えていれば、 list() は [any()] とほぼ同様でした。 そして、これら2つとも空のリストを含んでいたことも覚えているでしょう。 そしてここにオーバーラップドメインが存在します。 型として list() が定義された時、これは [] と重なります。 これを直すために、型シグネチャを次のように置き換える必要があります:
-spec empty({fifo, [], []}) -> true;
({fifo, nonempty_list(), nonempty_list()}) -> false.
あるいは、代わりに次のように書きます:
-spec empty({fifo, [], []}) -> true;
({fifo, [any(), ...], [any(), ...]}) -> false.
それから再びDialyzerを実行すると、先ほどの警告が消えます。
次のエラーに進みましょう(長いので複数行に改行しました):
fifo_types.erl:28:
The call fifo_types:pop({'fifo',nonempty_improper_list('a','b'),['e',...]})
breaks the contract
({'fifo',In::[any()],Out::[any()]}) -> {term(),{'fifo',[any()],[any()]}}
人間が読めるように翻訳すると、これは28行目で、 pop/1 を呼び出す部分があり、これがファイル内で明記した型と、推論した型が一致しないということになります:
pop({fifo, [a|b], [e]}).
これがその呼び出しです。 いま、エラーメッセージでは不真正リスト(時に空になる)と認識したと言っています。そしてこれはまったくもって正しい認識です。 [a|e] は不真正リストです。 また、これが規約を破るとも言っています。 エラーメッセージから来ている型と一致していないという型定義を適合させる必要があります:
{'fifo',nonempty_improper_list('a','b'),['e',...]}
{'fifo',In::[any()],Out::[any()]}
{term(),{'fifo',[any()],[any()]}}
この問題は次の3つのうちのどれかで説明がつきます:
- 型シグネチャは正しく、呼び出しも正しく、問題は予測される返り値である
- 型シグネチャは正しく、呼び出しが間違っていて、問題は入力値である
- 呼び出しは正しいが、型シグネチャが間違っている
1つ目はすぐに排除できます。 返り値に関しては何もしていません。 すると2つ目と3つ目の選択肢が残ります。 決め手は不真正リストをキューに使ってもいいかどうかという点に行き着きます。 これはライブラリの書き手に委ねられますが、私は間違いなくこのコードでは不真正リストを使おうとは思わないと言えます。 実際、不真正リストは滅多に必要ありません。 したがって今回は2つ目の問題である、呼び出しが間違っているということになります。 この問題を解決するために、関数呼び出しを削除するか、直します:
test() ->
N = new(),
{2, N2} = pop(push(push(new(), 2), 5)),
...
pop({fifo, [a, b], [e]}).
再びDialyzerを実行します:
$ dialyzer fifo_types.erl
Checking whether the PLT /home/ferd/.dialyzer_plt is up-to-date... yes
Proceeding with analysis... done in 0m0.90s
done (passed successfully)
これでつじつまが合いました。
33.7. 型をエクスポートする¶
これまで万事良好でやってきました。 型を作って、シグネチャを書いて、追加の安全性と検証を行いました。 では、私たちのキューを他のモジュールで使いたい場合にはどうしたらいいのでしょうか。 よく使う、 dict 、 gb_trees あるいはETSテーブルではどうでしょうか。 Dialyzerでこれらに関する型エラーを見つけるにはどうしたらいいのでしょうか。
実は他のモジュール以来の型を使うことができます。 通常はドキュメントをくまなく探す必要がありました。 たとえば、 ets モジュールのドキュメントには次のようなエントリがあります:
---
DATA TYPES
continuation()
Opaque continuation used by select/1 and select/3.
match_spec() = [{match_pattern(), [term()], [term()]}]
A match specification, see above.
match_pattern() = atom() | tuple()
tab() = atom() | tid()
tid()
A table identifier, as returned by new/2.
---
これらは ets によりエクスポートされたデータ型です。 ETSテーブル、キーを受け取り、該当するエントリを返す型仕様を持っている場合、次のように定義します:
-spec match(ets:tab(), Key::any()) -> Entry::any().
これでおしまいです。
自分で書いた型をエクスポートする方法は、関数で行った方法とほとんど一緒です。 -export_type([TypeName/Arity]). というモジュール属性を追加するだけで可能となります。 たとえば、次のように cards モジュールから card() 型をエクスポートすることができます:
-module(cards).
-export([kind/1, main/0]).
-type suit() :: spades | clubs | hearts | diamonds.
-type value() :: 1..10 | j | q | k.
-type card() :: {suit(), value()}.
-export_type([card/0]).
...
それから、モジュールがDialyzerから見える(PLTに追加するか、他のモジュールと一緒に解析する)ようにすれば、型仕様の中で cards:card() のように参照することができます。

しかし、このように型をエクスポートすることには1つ欠点があります。 このように型を使うと、cardモジュールから型をはぎ取って、遊ぶことができなくなってしまいます。 カードをパターンマッチさせる {Suit, _} = ... というコードを書くことができました。 これは常に得策というわけではありません。これは将来 cards モジュールの実装を変更することを妨げてしまいます。 これは、(もし型がエクスポートされるなら) dict や fifo_types といったデータ構造を表すモジュール内で強化したい機能です。
Dialyzerでは、ユーザに「いいでしょう、私の型を使ってもいいですが、そのかわりその中身は見てはいけません!」と伝えるような方法で型をエクスポートすることを許可しています。 これは宣言を変更する問題です:
-type fifo() :: {fifo, list(), list()}.
これを次のように変更します:
-opaque fifo() :: {fifo, list(), list()}.
それからこの型を -export_type([fifo/0]) とエクスポートできます。
型を opaque(不透明) にするということは、型を定義したモジュールだけが、型の実装や修正を行うことが出来るという意味です。 こうすることで、他のモジュールが全体でなく値をパターンマッチすることを禁じて、(彼らがDialyzerを使っているなら)実装の急な変更によって影響を受けないように保証しています。
Don’t Drink Too Much Kool-Aid:
ときどき、opaqueデータ型の実装が、期待されるほど型付けが強くなかったり、問題がある(つまりバグがある)場合があります。 Dialyzerはその関数が初めて成功型付けを推論するまでは、関数の仕様を考慮に入れません。
つまり、型が -type 情報がまったく考慮に入れられず汎用的に見える場合、Dialyzerはopaque型によって混乱してしまうでしょう。 たとえば、Dialyzerがopaqueになっている card() データ型を解析しているときには、推論の際には {atom(), any()} として見ています。 card() を正しく使っているモジュールは、きちんと型を守っているのに、Dialyzerに型違反をしていると警告されるかもしれません。 これは card() データ型自身がDialyzerが型情報をつなげ、何が行われているか判断するのに必要な情報を十分に含んでいないためです。
通常、このようなエラーに遭遇した場合は、タプルにタグを打つと便利です。 -opaque card() :: {suit(), value()}. という表記から -opaque card() :: {card, suit(), value()}. という表記に変更することで、Dializerがopaque型でも上手く処理ができるようになります。
Dialyzerの開発者はいまopaqueデータ型が型推論において、より良く推論がされ、より型付けが強くなるように実装しようとしています。 また、ユーザが提供する型仕様をより重要だと判断するようにし、Dialyzerの解析においてより信頼するようにしようとしています。 しかし、これはまだ作業中です。
33.8. 型付けされたビヘイビア¶
クライアントとサーバ を振り返ると、 behaviour_info/1 関数でビヘイビアを宣言することができました。 この関数をエクスポートしているモジュールは、モジュール名をビヘイビアに与え、2つ目のモジュールでモジュール属性に -behaviour(ModName). を追加することでコールバックを実装することができました。
たとえば、 gen_server モジュールでのビヘイビアの定義は次のとおりです:
behaviour_info(callbacks) ->
[{init, 1}, {handle_call, 3}, {handle_cast, 2}, {handle_info, 2},
{terminate, 2}, {code_change, 3}];
behaviour_info(_Other) ->
undefined.
問題は、Dialyzerで型定義を確認する方法がないということです。 実際、ビヘイビアモジュールがコールバックモジュールで実装が期待される型を明記することはできないため、Dialyzerがそのような型情報を知る方法はありません。
R15Bから、Erlang/OTPコンパイラはアップグレードされ、 -callback という新しいモジュール属性を扱えるようになりました。 -callback モジュール属性は spec に似た構文をしています。 関数の型をこの構文で明記した場合には、 behaviour_info/1 関数は自動的に宣言されて、Dialyzerが扱えるような形で型仕様がモジュールのメタデータに追加されます。 たとえば、R15B以降の gen_server の定義は次のようになっています:
-callback init(Args :: term()) ->
{ok, State :: term()} | {ok, State :: term(), timeout() | hibernate} |
{stop, Reason :: term()} | ignore.
-callback handle_call(Request :: term(), From :: {pid(), Tag :: term()},
State :: term()) ->
{reply, Reply :: term(), NewState :: term()} |
{reply, Reply :: term(), NewState :: term(), timeout() | hibernate} |
{noreply, NewState :: term()} |
{noreply, NewState :: term(), timeout() | hibernate} |
{stop, Reason :: term(), Reply :: term(), NewState :: term()} |
{stop, Reason :: term(), NewState :: term()}.
-callback handle_cast(Request :: term(), State :: term()) ->
{noreply, NewState :: term()} |
{noreply, NewState :: term(), timeout() | hibernate} |
{stop, Reason :: term(), NewState :: term()}.
-callback handle_info(Info :: timeout() | term(), State :: term()) ->
{noreply, NewState :: term()} |
{noreply, NewState :: term(), timeout() | hibernate} |
{stop, Reason :: term(), NewState :: term()}.
-callback terminate(Reason :: (normal | shutdown | {shutdown, term()} |
term()),
State :: term()) ->
term().
-callback code_change(OldVsn :: (term() | {down, term()}), State :: term(),
Extra :: term()) ->
{ok, NewState :: term()} | {error, Reason :: term()}.
そして、ビヘイビアが変更されたことによってあなたのコードが壊れることはありません。 しかしながら、モジュールは -callback の形式と behaviour_info/1 関数は同時には使えないということを認識しておいてください。 どちらか一方だけです。 つまり、もしカスタムビヘイビアを作りたい場合には、そのやり方がR15B以前と以後で異なります。
新しいモジュールの利点は、Dialyzerがいくらか型エラーを解析をして、型チェックができるところです。
33.9. 多相型¶
ああ、なんという節タイトルでしょう。 多相型(あるいはパラメータ化された型)という言葉を聞いたことがなければ、このタイトルは少し恐ろしいものに聞こえるでしょう。 幸いにも、聞こえほどには複雑なものではありません。

多相型は、異なるデータ構造を型付けする際に、ときに保存するものを限定したいと事がある、という要求から生まれたものです。 先の節でのキューでは、ときになんでも受け入れ、ときにトランプだけ、あるいは整数だけを扱います。 後者2つの場合では、Dialyzerが浮動小数点数を整数のキューに入れようとした場合、あるいはタロットカードをトランプのキューに入れようとした場合に警告してもたいたい、というところが問題になってきます。
これまで学んできた方法では厳密にこれらを設定することが不可能でした。 多相型を使いましょう。 多相型は他の型によって「設定することができる」型のことです。 幸いにも、私たちは既にその構文は知っています。 整数のリストを定義するときに、 [integer()] または list(integer()) と定義すると言いました。これらは多相型です。 これらは型を引数に取る型です。
私たちのキューが整数またはトランプだけを受け付けるように、型をこのように定義することができます:
-type queue(Type) :: {fifo, list(Type), list(Type)}.
-export_type([queue/1]).
他のモジュールで file/1 型を使いたいときは、これをパラメータ化する必要があります。 cards モジュールでトランプの新しいデッキは次のようなシグネチャで定義します:
-spec new() -> fifo:queue(card()).
可能であれば、Dialyzerはモジュールを解析して、そのモジュールが扱うキューにカードだけを入れ、カードだけが出てくるように確認します。
実例を見せるため、Learn You Some Erlangをほぼやり終えたお祝いに動物園を買うことにしましょう。 私たちの動物園には、2匹の動物がいます。赤いパンダとイカです。 入園料はめちゃくちゃ高いですが、かなり質素な動物園です。
私たちはプログラマで、プログラマは怠惰なので自動化が好きということで、動物への餌やりを自動化することにしました。 多少調査した結果、赤いパンダは竹と鳥と卵とベリーを食べることが分かりました。 またイカはマッコウクジラと闘うことができることもわかったので、 zoo.erl モジュールではマッコウクジラだけを与えることに決めました:
-module(zoo).
-export([main/0]).
feeder(red_panda) ->
fun() ->
element(random:uniform(4), {bamboo, birds, eggs, berries})
end;
feeder(squid) ->
fun() -> sperm_whale end.
feed_red_panda(Generator) ->
Food = Generator(),
io:format("feeding ~p to the red panda~n", [Food]),
Food.
feed_squid(Generator) ->
Food = Generator(),
io:format("throwing ~p in the squid's aquarium~n", [Food]),
Food.
main() ->
%% Random seeding
<<A:32, B:32, C:32>> = crypto:rand_bytes(12),
random:seed(A, B, C),
%% The zoo buys a feeder for both the red panda and squid
FeederRP = feeder(red_panda),
FeederSquid = feeder(squid),
%% Time to feed them!
%% This should not be right!
feed_squid(FeederRP),
feed_red_panda(FeederSquid).
このコードでは feeder/1 を使っていて、これは動物の名前を受け取って、飼育係(餌を返す関数)を返します。 赤いパンダへの餌やりは赤いパンダの飼育員が行い、イカへの餌やりはイカの飼育員が行います。 feed_red_panda/1 や feed_squid/1 の関数定義によれば、飼育員を間違えてしまっても警告は出す方法はありません。 ランタイムの確認でもそれは不可能です。 餌を与えてしまったあとでは、時すでに遅しです:
1> zoo:main().
throwing bamboo in the squid's aquarium
feeding sperm_whale to the red panda
sperm_whale
なんということでしょう、この小動物はそんなもの食べられません! 型があればなんとかなりそうです。 次の型仕様はこの問題を解決するために、多相型の力を借りて、改訂されました。
-type red_panda() :: bamboo | birds | eggs | berries.
-type squid() :: sperm_whale.
-type food(A) :: fun(() -> A).
-spec feeder(red_panda) -> food(red_panda());
(squid) -> food(squid()).
-spec feed_red_panda(food(red_panda())) -> red_panda().
-spec feed_squid(food(squid())) -> squid().
food(A) 型がここで面白いところです。 A は、あとで決定される自由な型です。 それから feeder/1 の型仕様にあるfood型が、 food(red_panda()) や food(squid()) によって限定されます。 そしてfood型はよくわからないものを返す抽象関数ではなく、 fun(() -> red_panda()) や fun(() -> squid()) として扱われます。 これらの型定義をファイルに追加してからDialyzerを実行すると、次のように出力されます:
$ dialyzer zoo.erl
Checking whether the PLT /Users/ferd/.dialyzer_plt is up-to-date... yes
Proceeding with analysis...
zoo.erl:18: Function feed_red_panda/1 will never be called
zoo.erl:23: The contract zoo:feed_squid(food(squid())) -> squid() cannot be right because the inferred return for feed_squid(FeederRP::fun(() -> 'bamboo' | 'berries' | 'birds' | 'eggs')) on line 44 is 'bamboo' | 'berries' | 'birds' | 'eggs'
zoo.erl:29: Function main/0 has no local return
done in 0m0.68s
done (warnings were emitted)
このエラーは期待したものですね。 多相型バンザイ!
上のような機能はかなり便利ですが、コードにちょっとした変更を加えるだけで、Dialyzerが思わぬ結果を表示してしまう可能性があります。 たとえば、 main/0 関数が次のようなコードだったときに:
main() ->
%% Random seeding
<<A:32, B:32, C:32>> = crypto:rand_bytes(12),
random:seed(A, B, C),
%% The zoo buys a feeder for both the red panda and squid
FeederRP = feeder(red_panda),
FeederSquid = feeder(squid),
%% Time to feed them!
feed_squid(FeederSquid),
feed_red_panda(FeederRP),
%% This should not be right!
feed_squid(FeederRP),
feed_red_panda(FeederSquid).
先ほどと同じようには行きません。 間違った飼育員で関数が呼び出される前に、正しい飼育員で呼び出されています。 R15B01では、Dialyzerはこのコードのエラーを発見しません。 これはDialyzerが、複雑なモジュール内部の微調整を行った時に、餌やり関数のなかで無名関数が呼ばれているかの情報を必ずしも持っていないからです。
静的型付けのファンにとってこのことが少々悲しいことだとしても、これで十分に警告はされています。 次の文はDialyzerの成功型付けの実装を説明した論文から引用したものです:
成功型付けは、関数が評価して値にできる型の集合をかなり近似した型シグネチャのことです。 シグネチャの定義域には関数が引数として受け取ることが可能なすべての値を含んでいて、その値域はこの定義域から返るすべての返り値を含んでいます。
静的型付けの愛好家にとってはこれがどれほど弱い型付けに思えても、成功型付けは、関数がその成功型付けには許可されない方法で使われた場合(たとえば、関数に p ε/α を適用させる)にアプリケーションが確実に失敗する、という事実を捕らえる性質があります。 これはまさに、決して「オオカミ少年」にならない不具合検知ツールに必要な性質です。 また、成功型付けは自動プログラムドキュメンテーションにも利用が可能です。なぜなら、成功型付けは関数の可能な利用方法を、それが意図していなくても、必ず見つけるからです。
再度になりますが、Dialyzerがその手法において楽観的であることを心に留めておくことは、Dialyzerを効率的に利用する上で不可欠です。
もしがっかりしすぎてしまったのであれば、Dialyzerで -Woverspecs オプション付けてみましょう:
$ dialyzer zoo.erl -Woverspecs
Checking whether the PLT /home/ferd/.dialyzer_plt is up-to-date... yes
Proceeding with analysis...
zoo.erl:17: Type specification zoo:feed_red_panda(food(red_panda())) -> red_panda() is a subtype of the success typing: zoo:feed_red_panda(fun(() -> 'bamboo' | 'berries' | 'birds' | 'eggs' | 'sperm_whale')) -> 'bamboo' | 'berries' | 'birds' | 'eggs' | 'sperm_whale'zoo.erl:23: Type specification zoo:feed_squid(food(squid())) -> squid() is a subtype of the success typing: zoo:feed_squid(fun(() -> 'bamboo' | 'berries' | 'birds' | 'eggs' | 'sperm_whale')) -> 'bamboo' | 'berries' | 'birds' | 'eggs' | 'sperm_whale'
done in 0m0.94s
done (warnings were emitted)
これは、実際にあなたの仕様が、コードが受け付けるであろう物に対して厳密すぎるという警告をしていて、(間接的にではありますが)あなたに型仕様を緩くするか、型仕様を反映させるために入力値を違反して、出力をより良くするか、のどちらかにしましょうと言っています。

33.10. あなたは私のタイプです¶
Dialyzerは、とても口うるさいので、あなたもプログラムを辞めたくなるかもしれませんが、しばしばErlangでプログラムする上での真の友だとわかります。 1つ覚えておきたいのは、Dialyzerは事実上決して間違えは起こさず、その場合はおそらくあなたが間違っているのでしょう。 あるエラーは意味が無いと思うかもしれませんが、多くの型システムとは逆に、Dialyzerは正しいとわかっているときにだけ警告し、Dialyzerのコードベースのバグであることはほぼありません。 Dialyzerはあなたを苛つかせるかもしれませんし、あなたに謙虚であることを強制するかもしれません。しかし、そのことで悪いことが起きたり、汚いコードになるということはほとんど無いのです。
Note
この章を書いている間、私はstreamモジュールのより完全なバージョンを書いているときに、Dialyzerの扱いにくいエラーメッセージに悩まされました。 とてもイライラして、Dialyzerは複雑な型を扱うときに以下に機能不足か、ということをIRCで文句をいいました。
ばかですよね。結局(おどろくべきことでもなく)私が間違っていて、最初からDialyzerが正しかったのです。 Dialyzerはずーっと -spec が間違っていると言っていて、私は間違っていないと信じていたのです。 喧嘩は私の負けで、Dialyzerと私のコードが勝ちでした。 でも、これはこれでよかったのです。
さて、これでLearn You Some Erlang for great good!はおしまいです。 ここまで読んでくださってありがとうございました。 これ以上特にいうことはありませんが、なにかもっと知りたいことがあったり、私に何か伝えたいことがあるのであれば、「おわりに」を読んで下さい。 成功を祈ります! 並列の帝王よ!