23. アプリケーション伯爵¶
23.1. OTPアプリケーションから本当のアプリケーションへ¶
私たちのppoolアプリケーションは正当なOTPアプリケーションになり、これがどういうことか理解できるようになりました。 しかし、私たちのプロセスプールをつかってなにか便利なものを作りたいですね。 アプリケーションに関する理解をもう少し深めるために、2つ目のアプリケーションを書いてみましょう。 このアプリケーションは ppool に依存していますが、 ‘nagger’ アプリケーションよりも自動化されたことによる利点を享受できるでしょう。
erlcount と名付けたこのアプリケーションにはいくばくか簡単な目的があります。再帰的にディレクトリを走査して、すべてのErlangファイル( .erl で終わるファイル)を見つけ、正規表現を走らせて、モジュール内に与えられた文字列がどれだけあるか数えます。 個々の結果はまとめられ、スクリーンに最終結果として表示されます。
この特定の用途おnアプリケーションは比較的単純ですが、私たちのプロセスプールに強く依存するでしょう。 構造は次のようになるでしょう:
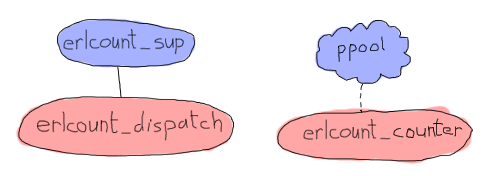
上のダイアグラムでは、 ppool はアプリケーション全体を表していて、一方で erlcount_counter はプロセスプールのワーカにしかならないことを表しています。 ワーカはファイルを開いて、正規表現を実行して、数を返します。 プロセスでありモジュールの erlcount_sup はスーパバイザとなり、 erlcount_dispatch はディレクトリを走査し、 ppool にワーカのスケジュールをするように命令し、結果をまとめる責任を持つ単一サーバになります。 またディレクトリの読み込みやデータ等の編集などを行うすべての関数を管理し、他のモジュールにこれらの関数呼び出しの連携に関する責任を持たせたままにする erlcount_lib モジュールも追加します。 最後は、 erlcount モジュールで、これはアプリケーションコールバックモジュールにするためだけに存在しています。
まずはじめに、先に作ったアプリケーションと同様、OTP標準のディレクトリ構造が必要です。 次のようになりますね。いくつかスタブファイルを追加してもいいでしょう:
ebin/
- erlcount.app
include/
priv/
src/
- erlcount.erl
- erlcount_counter.erl
- erlcount_dispatch.erl
- erlcount_lib.erl
- erlcount_sup.erl
test/
Emakefile
先ほど見たものと大きな違いはありません。先のアプリケーションからEmakefileをコピーしてもいいでしょう。
アプリケーションのほとんどの部分は非常に早く書き始めることができるでしょう。 .app ファイル、カウンター、ライブラリ、スーパバイザは比較的単純になるでしょう。 一方で、もしいまから作るアプリケーションを使う価値のあるものにしたいと思うのであれば、ディスパッチモジュールはやや複雑なタスクも達成できなければならないでしょう。 まずはappファイルから始めましょう:
{application, erlcount,
[{vsn, "1.0.0"},
{modules, [erlcount, erlcount_sup, erlcount_lib,
erlcount_dispatch, erlcount_counter]},
{applications, [ppool]},
{registered, [erlcount]},
{mod, {erlcount, []}},
{env,
[{directory, "."},
{regex, ["if\\s.+->", "case\\s.+\\sof"]},
{max_files, 10}]}
]}.
このappファイルは ppool のものよりはやや複雑です。 いくつかのフィールドはまだ ppool のものと同様だと分かります。このアプリケーションもまたバージョン1.0.0で、挙げられているモジュールは先に書いたとおりです。 この次の要素であるアプリケーションの依存性は ppool にはありませんでした。 先に説明したように、 applications タプルは erlcount より先に起動されるべきすべてアプリケーションのリストとなっています。 もしこのリストなしで起動しりょうとすると、エラーメッセージが表示されます。 それから {registered, [erlcount]} で登録済みプロセスを数えなければいけません。 技術的には、 erlcount アプリケーションの一部として来動作れたモジュールは、いずれも名前を必要としません。 すべてを匿名で行うことができます。 しかしながら、私たちは ppool が ppool_serv を私たちが与えた名前で登録することを知っていて、プロセスプールを使うことを知っているので、このアプリケーションを erlcount と命名し、それをそこに記録しておきます。 ppool を使うすべてのアプリケーションが同じ事をすれば、将来名前の衝突を検知することができるでしょう。 mod タプルは ppool と同様です。つまり、そこでアプリケーションビヘイビアのコールバックモジュールを定義します。

ここで新しいのは env タプルです。 さきほど見たように、このタプルはアプリケーション固有の設定変数のためのキーと値の保存場所を提供します。 これらの変数はアプリケーション内で稼働しているすべてのプロセスからアクセス可能で、便利のためにメモリ上に保存されています。 このタプルは基本的には、アプリケーションの設定ファイルの代わりとして使われます。
この場合、3つの変数を定義しています。 directory はアプリケーションにどこから .erl ファイルを探しに行くべきかを伝えます。(ここではアプリケーションを erlcount-1.0 ディレクトリから、つまり learn-you-some-erlang のルートディレクトリから起動するということです。)また max_files は一度にいくつのファイルディスクリプタが開かれるかを伝えます。ファイルの数が非常に多い場合に10000ファイルも同時に開きたくないので、この変数は ppool 内のワーカの最大数に対応します。 そして最も複雑な変数は regex です。これは結果を数えるために、個々のファイル上で検索に用いられるすべての正規表現を含んでいます。
Perl Compatible Regular Expressions (PCRE)の構文に関して長々と説明する気はありませんが(興味がある方は、 re モジュールにいくらか説明があります)、ここで何をしているかは説明しましょう。 ここでは、最初の正規表現は「’if’の後に空白文字1文字( \s 2つ目のバックスラッシュはエスケープ用です)を含み、 -> で終わる文字列を探せ。さらに ‘if’ と -> の間に何かがある( .+ )ものを探せ」ということを言っています。 2つ目の正規表現は「’case’の後に空白文字1文字( \s )がある文字列で、空白文字1文字が直前にある’of’で終わって、 ‘case ‘と’ of’の間には何かがある( .+ )というものを探せ」ということを言っています。 簡単に言うと、 case ... of と if ... end をライブラリ内でそれぞれ何回ずつ使っているかを数えようというのです。
Don’t Drink Too Much Kool-Aid:
正規表現を使うことはErlangコードを解析する上で最適な方法ではありません。 結果が正確でないことが多いのが問題で、たとえば文章中の文字列やコメントに探しているパターンがあっても、それは技術的にはソースコードではありません。
より正確な結果を取得するには、モジュールを直接Erlangにパースされ展開されたものを検索する必要があるでしょう。 これは(本書の範疇を超えていて)より複雑な方法ですが、マクロのようなものを扱ったり、コメントを排除したり、たいてい正しく検索されるようになります。
この珍しいファイルとで、アプリケーションコールバックモジュールを書き始めてみましょう。 複雑ではなく、基本的に単にスーパバイザを起動させるものになります:
-module(erlcount).
-behaviour(application).
-export([start/2, stop/1]).
start(normal, _Args) ->
erlcount_sup:start_link().
stop(_State) ->
ok.
そしてスーパバイザがこれです:
-module(erlcount_sup).
-behaviour(supervisor).
-export([start_link/0, init/1]).
start_link() ->
supervisor:start_link(?MODULE, []).
init([]) ->
MaxRestart = 5,
MaxTime = 100,
{ok, {{one_for_one, MaxRestart, MaxTime},
[{dispatch,
{erlcount_dispatch, start_link, []},
transient,
60000,
worker,
[erlcount_dispatch]}]}}.
これは標準的なスーパバイザで、先の簡単な図解で示した通り erlcount_dispatch のみを監視します。 停止に関しては MaxRestart 、 MaxTime および60秒という値はかなり適当に選びましたが、実際はあなたの要求に適したものを調べたくなることでしょう。 これはデモアプリケーションなので、今回はこれらの値はそれほど重要ではありません。 筆者は常に怠惰であることを忘れません。
次のプロセスと、鎖構造のモジュールと、ディスパッチャについて触れていきましょう。 ディスパッチャは便利なものにするためにはいささか複雑な要求があります:
- .erl で終わるファイルを見つけるためにディレクトリを走査するときに、たとえ複数の正規表現を適用する場合でも、すべてのディレクトリを1度ずつだけ辿るべきです。
- 条件に合うものが1つでも見つかった場合には、すぐにそのファイルを正規表現検索に掛けられるに、キューに追加できるようにすべきです。条件に合うすべてのファイルが揃うのを待たないと、キューに入れられないようにするべきではありません。
- 最後に結果を比較できるよう、1つの正規表現ごとにカウンターを保持する必要があります。
- .erl ファイルをすべて探し終わる前に erlcount_counter ワーカから結果を取得し始めることができます。
- たくさんの erlcount_counter を同時に走らせることができます。
- ディレクトリの中からソースファイルをすべて見つけ終わった後にも結果を取得し続けらることが好ましいです。(特に、多くのファイルがある場合や、複雑な正規表現の場合)
ここで今すぐ考慮しなければいけないことが大きく2点あります。どうやってディレクトリを再帰的に辿り、その最中にキューに追加できるように条件に該当するファイルを取得できるようにするか。そして、どうやってディレクトリの走査が行われている間に、混乱することなく結果を受け取れるか、の2点です。
初見では、再帰の最中に結果を取得できるようにするための最も単純に見える方法は、そのためのプロセスを作るというものです。 しかしながら、監視ツリーに他のプロセスを追加する事ができるようにしてから、それらが一緒に動作できるようにするためだけに、先の構造を変更するのは少々うっとうしいものです。 実際は、もっと簡単な方法があります。
これは 継続渡し形式 と呼ばれるプログラミング形式です。 この背景にある基本的な考え方は、通常深く再帰し、すべての手順を分解していく関数を1つ取るということにあります。 各手順を返し(通常アキュムレータになります)たあと、それに続く処理をする関数を返します。 私たちの場合ですと、私たちの関数は基本的には2つの戻り値が考えられます:
{continue, Name, NextFun}
done
前者を受け取った場合はいつでも、 FileName を ppool に追加して、それから NextFun を呼び出してさらにファイルを探し続けます。 erlcount_lib 内にこの関数を次のように実装できます:
-module(erlcount_lib).
-export([find_erl/1]).
-include_lib("kernel/include/file.hrl").
%% Finds all files ending in .erl
find_erl(Directory) ->
find_erl(Directory, queue:new()).
おや、なにか新しい物が出てきました! なんということでしょう、私の心臓の鼓動は高鳴り、体中の血が巡っています。 上にあるインクルードファイルは file モジュールによって与えられています。 このファイルはたくさんのフィールドを持ったレコード( #file_info{} )を含んでいて、そこにはファイルタイプ、ファイルサイズ、パーミッションなどのファイルの詳細が記載されています。
ここでの私たちの設計にはキューが含まれています。 なぜでしょうか。 ディレクトリが2つ以上のファイルを含んでいることは容易に有り得ます。 ですから、ディレクトリを見て、たとえば15個ファイルがあったときに、まず最初の1つを処理して(もしそれがディレクトリなら開いて、中を見て、と続きます)、そのあと他の14個のファイルを処理します。 そうするためには、処理するまでファイルの名前をメモリ上に保存しておきます。 そのためにキューを使いますが、ファイルを読み込む順番を気にしないのであれば、スタックといった他のデータ構造でも問題ないでしょう。 とにかく、要点は、私たちのアルゴリズムではキューはファイルのTODOリストのような働きをするということです。
さて、では最初の呼び出しで渡された最初のファイルを読むところから始めましょう:
%%% Private
%% Dispatches based on file type
find_erl(Name, Queue) ->
{ok, F = #file_info{}} = file:read_file_info(Name),
case F#file_info.type of
directory -> handle_directory(Name, Queue);
regular -> handle_regular_file(Name, Queue);
_Other -> dequeue_and_run(Queue)
end.
この関数はいくつかの事を教えてくれます。 私たちは通常のファイルとディレクトリだけ扱いたいこと。 それぞれの場合についてそれぞれの事象を扱う関数を書くこと。( handle_directory/2 と handle_regular_file/2 ) 他のファイルに関しては、 dequeue_and_run/2 を実行して準備したキューからすべて取り出すこと。(これが何かについてはすぐに確認します。)以上の事が分かります。 いまのところは、まずはディレクトリの扱いについて見ていきましょう:
%% Opens directories and enqueues files in there
handle_directory(Dir, Queue) ->
case file:list_dir(Dir) of
{ok, []} ->
dequeue_and_run(Queue);
{ok, Files} ->
dequeue_and_run(enqueue_many(Dir, Files, Queue))
end.
もしファイルが1つも無ければ、 dequeue_and_run/1 を実行して探索を続け、もしたくさんのファイルがあれば、 dequeue_and_run/1 を実行する前にそれらをキューに貯めます。 もう少し詳しく説明しましょう。 dequeue_and_run 関数はファイル名のキューを取り、1要素を取り出します。 この関数が取り出すファイル名は find_erl(Name, Queue) で使われ、そしていままさにファイルの探索を始めたかのように、探索を続けます。
%% Pops an item from the queue and runs it.
dequeue_and_run(Queue) ->
case queue:out(Queue) of
{empty, _} -> done;
{{value, File}, NewQueue} -> find_erl(File, NewQueue)
end.
もしキューが空なら( {empty, _} )、関数は終了した( done 、継続渡し形式関数のために選ばれたキーワード)と判断し、そうでなければまた探索を続ける、ということに留意してください。
他に考慮しなければならない関数は enqueue_many/3 です。 これは、与えられたディレクトリ内で見つかったすべてのファイルをキューに貯めるように設計されていて、次のような動作をします:
%% Adds a bunch of items to the queue.
enqueue_many(Path, Files, Queue) ->
F = fun(File, Q) -> queue:in(filename:join(Path,File), Q) end,
lists:foldl(F, Queue, Files).
基本的に、 filename:join/2 関数はディレクトリのパスと個々のファイル名を連結するために使われます。(つまり、絶対パスを取得するため) それから、そのファイルの絶対パスをキューに追加します。 あるディレクトリ内のすべてのファイルに同様の処理を繰り返し行うためにfoldを使っています。 その後、ファイルを取り出すその新しいキューは find_erl/2 を実行するときに再び使われますが、しかし今回は、見つけたすべての新しいファイルと一緒に、TODOリストに追加されます。
あらら、ちょっと脱線してしまいました。 いまどこまで話を進めてましたっけ。 ああ、そうだ、ディレクトリの処理をしていて、それが終わったところでした。 次は、通常のファイルかどうかを確認して、さらにファイル名が .erl で終わっているかどうかを確認する必要があります。
%% Checks if the file finishes in .erl
handle_regular_file(Name, Queue) ->
case filename:extension(Name) of
".erl" ->
{continue, Name, fun() -> dequeue_and_run(Queue) end};
_NonErl ->
dequeue_and_run(Queue)
end.
( filename:extension/1 を使って)ファイル名が条件に一致したら、継続を返していることが分かるでしょう。 継続は Name を呼び出し元に与え、これからまだ処理が残っているファイルのキューに対する dequeue_and_run/1 の操作を fun() にラップしています。 このようにして、ユーザはそのラップされた fun() を呼び出すことができ、さもまだ再帰呼び出しの途中であるかのように処理を続けることができ、一方でその間にも結果を受け取る事ができます。 ファイル名が .erl で終わらない場合には、ユーザは結果を返さず、更にファイルをキューから取り出し続けます。 これだけです。
やりました!継続渡し形式に関する部分はこれでおしまいです。 今度は別の問題に取り掛かれます。 ディスパッチと受け取りを同時に行えるようなディスパッチャをどのように設計しましょうか。 私の提案は、といっても私がこの本を書いてるので読者のあなたは受け入れる他ないのですが、有限ステートマシンを使うことです。 この場合の有限ステートマシンには2つの状態があります。 1つ目は ‘dispatching’ 状態です。 これは、 find_erl 継続渡し形式関数を待っていて検索が終わったときにいつでも使われる状態です。 その状態のときは、数を数え終わろうとしていることは決して考えません。 数を数えることに関しては2つ目にして最後の状態の ‘listening’ で行います。しかし ppool からは常に通知を受け取ります:
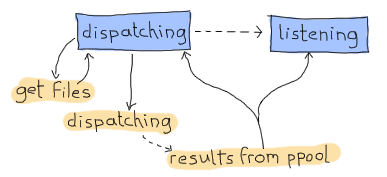
この仕様から次のような要件が出てきます:
- 新しいファイルをディスパッチするときのための非同期イベントでのdispatching状態
- 新しいファイルを取得し終わるときのための非同期イベントでのdispatching状態
- 新しいファイルを取得し終わるときのための非同期イベントでのlistening状態
- 正規表現の検索をし終えるときに ppool ワーカから送られるグローバルイベント
これらの仕様で私たちの gen_fsm をゆっくり作りはじめましょう:
-module(erlcount_dispatch).
-behaviour(gen_fsm).
-export([start_link/0, complete/4]).
-export([init/1, dispatching/2, listening/2, handle_event/3,
handle_sync_event/4, handle_info/3, terminate/3, code_change/4]).
-define(POOL, erlcount).
これによって、私たちのAPIは2つの関数を持つことになります。1つはスーパバイザ用( start_link/0 )でもう1つは ppool の呼出し元( complete/4 これについて説明するときが来たら引数の解説をします)です。 他の関数は listening/2 や dispatching/2 などの非同期状態ハンドラを含む、標準の gen_fsm コールバックです。 また ?POOL マクロも定義しました。これは ppool サーバに ‘erlcount’ という名前を与えます。
では gen_fsmのデータはどのようになるべきなのでしょうか。 私たちは非同期で処理を行い、何に差し置いても常に ppool:run_async/2 を呼び出したいので、ファイルをキューにため終わったかどうかを知る方法が本当にないのです。 基本的にはこのような時系列になります:
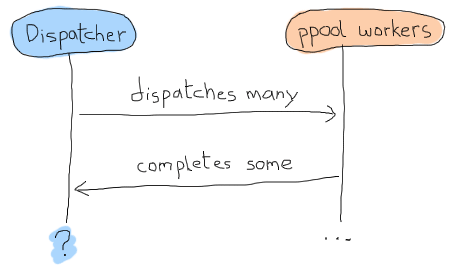
この問題を取り除く方法の1つとしてはタイムアウトを使うというのがありますが、これは常に面倒です。タイムアウトは長すぎやしないか、短すぎやしないか。何かクラッシュしたのか。などと色々と考慮することがあります。 この不確実性はおそらくレモンで出来た歯ブラシぐらい面白いものです。 代わりに、個々のワーカが、追跡できて返信と紐付けられる、秘密結社「成功した労働者(workers who succeeded)」に入る秘密のパスワードのような、何かしらの識別子を与えられるような概念を使うことができます。 この概念によって、どのようなメッセージに対しても一つ一つ適用し、いつ完全に終了したを知ることができるようになります。 これで、私たちの状態データがどのようになるかわかりました:
-record(data, {regex=[], refs=[]}).
最初のリストは {RegularExpression, NumberOfOccurrences} という形式のタプルで、2つ目はメッセージに対する何らかの参照のリストです。 一意なものであればなんでも入れることができます。 それから次のような2つのAPI関数を追加することができます:
%%% PUBLIC API
start_link() ->
gen_fsm:start_link(?MODULE, [], []).
complete(Pid, Regex, Ref, Count) ->
gen_fsm:send_all_state_event(Pid, {complete, Regex, Ref, Count}).
そして、ここで秘密の complete/4 関数が登場しました。 驚くことではないですが、ワーカは3つのデータだけを返せば良いのです。その3つは、いま検索している正規表現、ワーカに関連したスコア、上で触れた参照、です。 すばらしい、ここで本当に面白い部分にたどり着きました!
init([]) ->
%% Move the get_env stuff to the supervisor's init.
{ok, Re} = application:get_env(regex),
{ok, Dir} = application:get_env(directory),
{ok, MaxFiles} = application:get_env(max_files),
ppool:start_pool(?POOL, MaxFiles, {erlcount_counter, start_link, []}),
case lists:all(fun valid_regex/1, Re) of
true ->
%% creates a regex entry of the form [{Re, Count}]
self() ! {start, Dir},
{ok, dispatching, #data{regex=[{R,0} || R <- Re]}};
false ->
{stop, invalid_regex}
end.
init 関数は、最初にアプリケーションファイルから実行に必要な情報をすべて読み込みます。 それが終わったら、 erlcount_counter をコールバックモジュールを用意して、プロセスプールの起動を計画します。 起動前の最後のステップで登録されようとしている正規表現すべてが有効なものかを確認します。 その理由は単純です。 ここで確認を行わないと、代わりにどこかでエラー処理を追加しなければならなくなるからです。 これが erlcount_counter ワーカで行われることです。 ここまでのことが無事完了したら、今度はワーカがクラッシュした時の処理などを定義しなえればいけません。 アプリケーションを起動するのは簡単ですね。 次に、 valid_regex/1 関数です:
valid_regex(Re) ->
try re:run("", Re) of
_ -> true
catch
error:badarg -> false
end.
正規表現を空文字列に対して検索を掛けてみるだけです。 これはまったく時間がかかりませんし、 re モジュールは正規表現を実行しようとします。 正規表現が有効であれば、 [{R,0} || R <- Re] で定義された状態で {start, Directory} を送りことでアプリケーションを起動します。 これは基本的には [a,b,c] という形式のリストを [{a,0},{b,0},{c,0}] という形式に変換します。これは、各正規表現にカウンターを追加したものです。
最初に扱うメッセージは handle_info/2 の {start, Dir} です。 Erlangのビヘイビアはすべてメッセージに基づいているので、関数呼び出しや自分のやりたいことを始めたいときも愚直に順序良くメッセージを送らなければなかったことを思い出して下さい。 じれったいですが、これで扱いやすくなるのです:
handle_info({start, Dir}, State, Data) ->
gen_fsm:send_event(self(), erlcount_lib:find_erl(Dir)),
{next_state, State, Data}.
erlcount_lib:find_erl(Dir) の結果を自分に送ります。 それが State の値であれば、 FSMの init 関数によって設定されたように、その結果は dispatching の中で受け取られます。 このスニペットは私たちの問題を解決しますが、同時にFSM全体で持つ一般的なパターンも表現しています。 find_erl/1 関数は継続渡し形式で書かれているため、自分に非同期イベントを送り、それを正しい各コールバック状態の中で処理することができます。 最初の継続の結果は {continue, File, Fun} になるでしょう。 また、私たちは init 関数の初期状態として ‘dispatching’ 状態を設定するため、その状態でいるでしょう:
dispatching({continue, File, Continuation}, Data = #data{regex=Re, refs=Refs}) ->
F = fun({Regex, _Count}, NewRefs) ->
Ref = make_ref(),
ppool:async_queue(?POOL, [self(), Ref, File, Regex]),
[Ref|NewRefs]
end,
NewRefs = lists:foldl(F, Refs, Re),
gen_fsm:send_event(self(), Continuation()),
{next_state, dispatching, Data#data{refs = NewRefs}};
このコードはちょっと醜いですね。 各正規表現で、一意な参照を作成し、この参照を知っている ppool ワーカを待機させ、それからこの参照を保存します。(これによって、ワーカが終了したかどうかを知ります) 私はこの方法を実装するのに、すべての新しい参照を楽に集めるために foldl 内で行いました。 この ‘dispatching’`が終わったら、継続を再度呼び出して、さらに結果を取得し、私たちがいる状態としての新しい参照と一緒にくる次のメッセージを待ちます。
次にどのようなメッセージを受け取るのでしょうか。 ここで2つの選択肢があります。 どのワーカも(たとえまだ実装されていなかったとしても)まったく結果を返さないか、またはすべてのファイルが見終えられて done メッセージを取得するかのいずれかです。 dispatching/2 関数の実装を終えるために、2つ目の状態について見てみましょう:
dispatching(done, Data) ->
%% This is a special case. We can not assume that all messages have NOT
%% been received by the time we hit 'done'. As such, we directly move to
%% listening/2 without waiting for an external event.
listening(done, Data).
コメントは、かなり明示的に何が行われているか説明していますが、ここでも説明してみましょう。 ジョブのスケジューリングをするときに、 dispatching/2 や listening/2 の中で結果を受け取ります。 これは次のような形式を取ります:
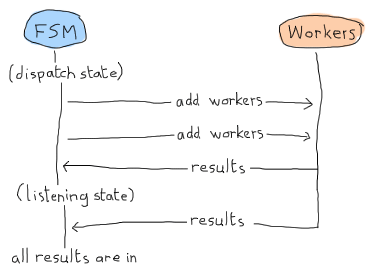
この場合、 ‘listening’ 状態は結果を待つだけとなり、すべてをそこで宣言します。 しかし、ここはErlangの世界(Erland)であり、並列で非同期に処理を行えるということを思い出して下さい! 次のような流れもありえます:
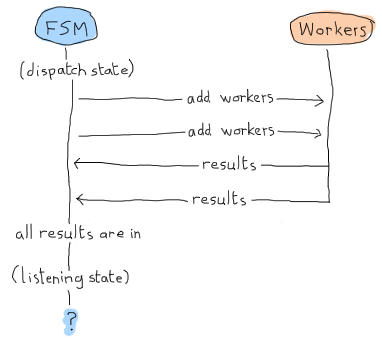
あちゃー。 私たちのアプリケーションはメッセージを待ち続け、そこで永遠に止まってしまいます。 これが手動で listening/2 を呼び出す必要がある理由です。 すでにすべての結果を受け取っていた場合に備えて、すべての結果が受け取られたかを確認するためのなにかしらの結果検知を行うためにこのようなことを強制しています。 このような実装になります:
listening(done, #data{regex=Re, refs=[]}) -> % all received!
[io:format("Regex ~s has ~p results~n", [R,C]) || {R, C} <- Re],
{stop, normal, done};
listening(done, Data) -> % entries still missing
{next_state, listening, Data}.
もし、参照が1つも残っていなかったら、すべてが受け取られたということで、結果を出力できます。 そうでなければ、メッセージを待ち続けられます。 complete/4 についてもう一度見てみると、このようなダイアグラムになります:
‘dispatching’ か ‘listening’ のいずれかの中で受信されるうるので、結果のメッセージはグローバルです。 実装は次のようになります:
handle_event({complete, Regex, Ref, Count}, State, Data = #data{regex=Re, refs=Refs}) ->
{Regex, OldCount} = lists:keyfind(Regex, 1, Re),
NewRe = lists:keyreplace(Regex, 1, Re, {Regex, OldCount+Count}),
NewData = Data#data{regex=NewRe, refs=Refs--[Ref]},
case State of
dispatching ->
{next_state, dispatching, NewData};
listening ->
listening(done, NewData)
end.
これが行うことは、 Re リスト内で処理が終わった正規表現を探すことです。このリスト内には各正規表現ごとのカウンターもあります。 そして値( OldCount )を取り出し、それを lists:keyreplace/4 を使って新しいカウント( OldCount+Count )で更新します。 ワーカの参照( Ref )を取り除いている間に Data レコードを新しいスコアで更新し、自分に次の状態を送ります。
通常のFSMでは、 {next_state, State, NewData} を終えたところとなりますが、ここでは、先ほど述べた完了したかどうかを知ることに関連した問題のため、手動で listening/2 を再度呼ばなければいけません。 残念で、悲しいことですが、必要な手続きなのです:
ディスパッチャについては以上です。 残りのビヘイビア関数をさっと追加します:
handle_sync_event(Event, _From, State, Data) ->
io:format("Unexpected event: ~p~n", [Event]),
{next_state, State, Data}.
terminate(_Reason, _State, _Data) ->
ok.
code_change(_OldVsn, State, Data, _Extra) ->
{ok, State, Data}.
これでカウンターの話に移ることができます。 その前にちょっと休憩したいことでしょう。 マッチョな読者なら、リラックスしにベンチプレスを2、3回やってきてから、次の節に進むのもいいでしょう。
23.1.1. カウンター¶
カウンターはディスパッチャよりも単純です。 依然として処理を行うためにビヘイビア(この場合はgen_server)は必要としますが、必要最小限になります。 たった3つだけする必要があります:
- ファイルを開く
- そのファイル内で正規表現を検索して、該当箇所を数える
- 結果を返す
まずはじめに、 file モジュールにこれらの処理を行う上で便利な関数がたくさんあります。 手順3のために、 erlcount_dispatch:complete/4 を定義しましたね。 手順2では、 re モジュールの run/2-3 を使うことが出来ますが、必要としているものは行なってくれません:
1> re:run(<<"brutally kill your children (in Erlang)">>, "a").
{match,[{4,1}]}
2> re:run(<<"brutally kill your children (in Erlang)">>, "a", [global]).
{match,[[{4,1}],[{35,1}]]}
3> re:run(<<"brutally kill your children (in Erlang)">>, "a", [global, {capture, all, list}]).
{match,[["a"],["a"]]}
4> re:run(<<"brutally kill your children (in Erlang)">>, "child", [global, {capture, all, list}]).
{match,[["child"]]}
この関数は必要な引数を取りますが( re:run(String, Pattern, Options) )、正しい数を返してくれません。 カウンターを書きはじめられるように、次のような関数を erlcount_lib に追加しましょう:
regex_count(Re, Str) ->
case re:run(Str, Re, [global]) of
nomatch -> 0;
{match, List} -> length(List)
end.
これは基本的にはただ結果を数えて、その数を返すだけです。 レポート用紙に記入することを忘れないで下さい。
では、ワーカで次のように書きましょう:
-module(erlcount_counter).
-behaviour(gen_server).
-export([start_link/4]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
terminate/2, code_change/3]).
-record(state, {dispatcher, ref, file, re}).
start_link(DispatcherPid, Ref, FileName, Regex) ->
gen_server:start_link(?MODULE, [DispatcherPid, Ref, FileName, Regex], []).
init([DispatcherPid, Ref, FileName, Regex]) ->
self() ! start,
{ok, #state{dispatcher=DispatcherPid,
ref = Ref,
file = FileName,
re = Regex}}.
handle_call(_Msg, _From, State) ->
{noreply, State}.
handle_cast(_Msg, State) ->
{noreply, State}.
handle_info(start, S = #state{re=Re, ref=Ref}) ->
{ok, Bin} = file:read_file(S#state.file),
Count = erlcount_lib:regex_count(Re, Bin),
erlcount_dispatch:complete(S#state.dispatcher, Re, Ref, Count),
{stop, normal, S}.
terminate(_Reason, _State) ->
ok.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
ここで2ヶ所面白い部分は、自分自身に起動するように命令する init/1 コールバックの部分と、ファイルを開いて( file:read_file(Name) )、 regex_count/2 関数に渡すバイナリを取得して、 complete/4 にそれを戻す単独の handle_info/2 節の部分です。 それからワーカを止めます。 残りは標準のOTPコールバックに関する部分です。
コンパイルして、全部動かしてみましょう!
$ erl -make
Recompile: src/erlcount_sup
Recompile: src/erlcount_lib
Recompile: src/erlcount_dispatch
Recompile: src/erlcount_counter
Recompile: src/erlcount
Recompile: test/erlcount_tests
やりました。 1つも問題が無いですし、シャンパンを開けましょう!
23.2. アプリケーションよ、走れ¶
私たちのアプリケーションを稼働させる方法はたくさんあります。 あなたが実行時にいるディレクトリでは次の2つのディレクトリが同列に並んでいることを確認してください:
erlcount-1.0
ppool-1.0
Erlangを次のように起動してみます:
$ erl -env ERL_LIBS "."
ERL_LIBS 変数は環境の中で定義された特別な変数で、ErlagnがどこでOTPアプリケーションを探すかを指定できるものです。 その後VMは自動的にそこを見に行って ebin/ ディレクトリを見つけます。 erl は -env NameOFVar Value という形式の引数を取ることもでき、これによって設定を素早く上書きすることが出来ます。まさに私がここで行ったことです。 ERL_LIBS 変数はかなり便利です。特にライブラリをインストールするときには役に立ちます。ぜひ覚えておいてください!
先程起動したVMで、モジュールがきちんとロードされているかテストすることができます:
1> application:load(ppool).
ok
この関数は見つかる限りのアプリケーションモジュールをメモリ上にロードしようとします。 もし、この関数を呼ばなければ、これはアプリケーションを起動するときに自動で行われますが、自分で呼んだほうが簡単にテストができます。 アプリケーションを起動してみましょう:
2> application:start(ppool), application:start(erlcount).
ok
Regex if\s.+-> has 20 results
Regex case\s.+\sof has 26 results
ディレクトリに何があるかによって結果は変化します。 ファイルの数によって、処理時間が長くなることに留意して下さい。

しかし、アプリケーションに対してことなる変数を設定したい場合はどうしたらいいのでしょうか。 アプリケーションファイルをいつも変更する必要があるのでしょうか。 いいえ、必要ありません! Erlangはこれもサポートしています。 たとえば私が、Erlangプログラマがこれまで何度ソースファイル内で怒りを顕わにしたか知りたくなったとしましょう。
erl 実行バイナリは -AppName Key1 Val1 Key2 Val2 ... KeyN ValN という形式で特別な引数群を受け取る事ができます。 この場合、次のような2つの正規表現をR14B02のコードベースに対して検索をかけることができます:
$ erl -env ERL_LIBS "." -erlcount directory '"/home/ferd/otp_src_R14B02/lib/"' regex '["shit","damn"]'
...
1> application:start(ppool), application:start(erlcount).
ok
Regex shit has 3 results
Regex damn has 1 results
2> q().
ok
このとき、引数に与えたすべての正規表現はシングルクォーテーション( ' )で囲まれていることに留意してください。 この理由は私のUnixシェルに表現したとおりに解釈させたかったからです。 異なるシェルでは異なる記述方法になるでしょう。
もっと一般的な表現(大文字から始まる値、のような)や、同時に開くファイルの数をもっと増やして検索を試してみることもできます:
$ erl -env ERL_LIBS "." -erlcount directory '"/home/ferd/otp_src_R14B02/lib/"' regex '["[Ss]hit","[Dd]amn"]' max_files 50
...
1> application:start(ppool), application:start(erlcount).
ok
Regex [Ss]hit has 13 results
Regex [Dd]amn has 6 results
2> q().
ok
あら、OTPプログラマのみなさん。 なぜそんなに起こってるんですか。(「Erlangで仕事してるから」というのは回答としては受け入れ難いですね)
こちらの条件で実行した場合は、何百ものファイルに対してより複雑な確認が必要となるので、実行時間はずっと長くなるでしょう。 これはかなりいい具合に動きましたが、少しイライラすることがあります。 なぜ、両方のアプリケーションをいちいち手で起動させているのでしょうか。 もっといい方法はないのでしょうか。
23.3. 同梱アプリケーション¶
同梱アプリケーションは先の問題を上手く対処する方法の1つです。 同梱アプリケーションの基本的な考え方としては、アプリケーション(この例では ppool )を他のアプリケーション(ここでは erlcount )の一部として定義する、ということです。 これを行うためには、両アプリケーションともに多くの変更が必要となります。
変更の要点は、アプリケーションファイルを少々変更すること、スタートフレーズと呼ばれるものをいくつか追加する、などの必要があります。

そして同梱アプリケーションをよりおすすめ しない 単純な理由が1つあります。コードの再利用性を著しく制限することです。 このように考えてみて下さい。 私たちは ppool のアーキテクチャを誰もが使え、独自のプロセスプールを作り、それに対して好きなことが出来るようなものにしようと、多くの時間を使ってきました。 もしppoolを同梱アプリケーションにしようと思うなら、それはもはやこのVM上の他のどのようなアプリケーションにも含まれなくなり、もしerlcountが死ねば、ppoolは一緒になくなり、ppoolを使いたがっていた他の外部アプリケーションを破壊することになります。
このような理由から、同梱アプリケーションは通常は多くのErlangプログラマの選択肢からは外されます。 次の章でご紹介するように、リリースが同様のこと(そしてそれ以上の事)をより汎用的な記述で書くときに役に立ちます。
そのまえに、アプリケーションについてもう1つお話することがあります。
23.4. 複雑な終了¶
アプリケーションを終了させる前に手順を踏む必要がある場合があります。 アプリケーションコールバックモジュール内の stop/1 関数では、特にアプリケーションが既に終了していた後に呼ばれた場合に不十分です。 アプリケーションが実際に落ちてしまう前に、後片付けをする必要がある場合にはどうしたら良いでしょうか。
方法は簡単です。 prep_stop(State) 関数をアプリケーションコールバックモジュールに追加するだけです。 State は start/2 関数から返される状態で、 prep_stop/1 が返したものはなんでも stop/1 に渡されます。 したがって prep_stop/1 は技術的には start/2 と stop/1 の間に入り、アプリケーションがまだ生きているけれど、終了する直前に実行されます。
これは、使う必要があるタイミングがわかっているけれど、私たちのアプリケーションにいますぐには必要がないコールバックの一種です。
Don’t drink too much Kool-Aid:
私が実世界で prep_stop/1 コールバックを使った例は、 Yurii Rashkosvkii (yrashk) が agner というErlangのパッケージマネージャの問題をデバッグするのを手伝ったときに行ったことが挙げられます。 そこで起きていた問題はやや複雑で、 simple_one_for_one スーパバイザとアプリケーションマスターの間でのおかしなやり取りに関するものでした。このコラムは興味がなければ飛ばしてもらっても構いません。
agnerは基本的にはアプリケーションが立ち上がる途中で形成され、トップレベルのスーパバイザを起動し、それがサーバと他のスーパバイザを起動し、次々と動的な子プロセスを生成します。
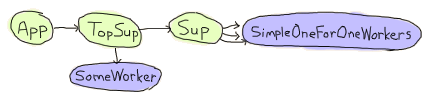
ここで、ドキュメントでは次のように言っています:
simple-one-for-one スーパバイザに関しての重要な注意:動的に生成された simple-one-for-one スーパバイザの子プロセスは、終了戦略によらず、明示的には殺されませんが、スーパバイザが殺されたとき(つまり、親プロセスからの終了シグナルを受け取ったとき)には終了することが期待されます。
そして、実際に明示的には殺されませんでした。 スーパバイザは通常の子プロセスだけ殺して終了し、終了メッセージをキャッシュするためにsimple-one-for-oneの子プロセスのビヘイビアにそれを渡し、そして消えます。 これは問題ありません。
先に見たように、個々のアプリケーションに対して、アプリケーションマスターがいます。 このアプリケーションマスターはグループリーダーとして機能します。 覚書として、アプリケーションマスターはその親(アプリケーションコントローラ)とその直接の子供(アプリケーションの最上位のスーパバイザ)とリンクしていて、その両方を監視しています。 どれかが失敗したら、マスターは処理を中止し、グループリーダーとしての立場を使って残りのすべての子供を終了させます。 再びになりますが、これも問題ありません。
しかし、この両方の起動を合わせて、アプリケーションを application:stop(agner) で終了させようとすると、非常に困った状況に陥ります:
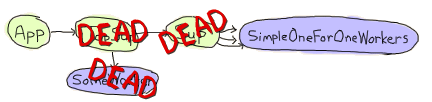
アプリケーション内の通常のワーカとスーパバイザが両方共死んだまさにそのときです。 simple-one-for-oneワーカはいま死のうとしていて、各々直接の祖先からから送られてくる EXIT シグナルを捕まえようとしています。
しかし同時に、アプリケーションマスターは直接の子供が死のうとしていて、まだ死んでいないsimple-one-for-oneワーカーをすべて殺そうとしている気配を察知します。
その結果、多くのワーカが死んだあとに片付けられ、また多くの残りのワーカはそのまま残されます。 これは非常にタイミングに依存していて、デバッグが難しく、直すのは簡単です。
Yuriiと私は基本的にこの問題を ApplicationCallback:prep_stop(State) 関数を使って、すべての動的なsimple-one-for-oneの子供のリストを取得し、それらを監視し、それらすべてが stop(State) コールバック関数内で死ぬまで待つようにしたことで、直しました。 これは、アプリケーションコントローラを動的な子プロセスがすべて死ぬまで、強制的に待たせています。 実際のファイルはangerのGitHubレポジトリで確認することができます。
なんと醜いことでしょう! 願わくば、人々がこのような問題に滅多に遭遇しなければ良いと思います。そしてあなたも遭遇しないことを願っています。 prep_stop/1 を使って問題解決をするなどという酷い図を忘れ去るために目薬でも注したほうがいいでしょう。たとえこの方法がたまに道理が通っていて望まれたとしてもです。 目薬を注し終えたら、アプリケーションをパッケージングしてリリースする話に移りますよ。
update
R15Bから、この問題は解決されました。 スーパバイザが終了する場合は、動的な子プロセスを終了は同期で行われているように思われます。