28. Bears, ETS, Beets¶

ここまで何度も何度も行なってきたことは、なんらかのストレージデバイスをプロセスの形で実装するということでした。 物を保存するために冷蔵庫を実装したり、プロセスを登録するために regis を作ったり、キーバリューストアなどを見てきました。 もし私たちがオブジェクト指向で設計をするプログラマだったら、大量のSingletonがあちこちにあり、特別なストレージクラスなどがあるような状況になってしまうでしょう。 事実、 dicts や gb_trees のようなデータ構造をプロセス内でラップするのは、このような状況に似ています。
プロセス内でデータ構造を保持することは実際は多くの状況でいいことです。プロセス内でタスクを実行する上でそのデータが、内部的な状態として利用するなど、実際に必要なときはいつでも、そのような利用方法は良いことです。 そのような妥当な利用事例はたくさんありますし、それを変更すべきではありません。 しかしながら、このような利用方法が最善でない事例が1つあります。それはプロセスが他のプロセスと共有する以上目的でデータ構造を保持している場合です。
私たちが書いたアプリケーションの内1つは、その最善でない事例の1つに当てはまります。 どれかわかりますか。 もちろんわかりますよね。そうです、私が前の章の最後で触れましたよね。regisは書き換える必要があります。 書き換える必要がある理由は、動作しないとか、きちんと処理できないとかそういったことではなくて、もしかすると大量の他のプロセスとデータを共有するゲートウェイとして動作してしまうからです。ここには構造的に問題があります。
regisはProcess Quest内でメッセージをやりとりする上で中心的なアプリケーションで(他のすべてのアプリケーションが使い)、名前付きプロセスに行くすべてのメッセージはそこを通過していきます。 つまり、私たちのアプリケーションを独立したアクターで並列にして、監視構造をスケールアップできるように腐心しても、すべての操作は、メッセージに1つ1つ応える必要があるような、中心となるregisプロセスに依存してしまうのです:
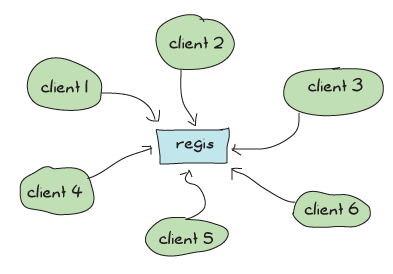
もし大量のメッセージが通過したら、regisはどんどん使用率があがって、要求が多くなり過ぎたら、システム全体が直列処理となって遅くなります。 これはかなり悪い状況です。
Note
regisがProcess Questにおいてボトルネックになるという直接の証拠はなにもありません。―事実、Process Questは他の多くのアプリケーションと比較すると野良の状態で非常に少ないメッセージしかやり取りしません。 もし、私たちが大量のメッセージや参照が必要となるような場所でregisを使ったら、問題がより顕在化するでしょう。
ほんのいくつか対応できる方法があるとすれば、regisをサブプロセスに分割して、データを共有することで参照を速くするか、データを何らかのデータベースに保存する方法を見つけて、データへの並行で並列なアクセスを可能にするかのどちらかでしょう。 前者は挑戦してみるには非常に面白いですが、私たちはより簡単な後者で実装していきましょう。
ErlangにはETS(Erlang Term Storage)テーブルと呼ばれるものがあります。 ETSテーブルはErlang VMに含まれる効率的なインメモリデータベースです。 仮想マシンの一部として存在していて、破壊的な更新ができ、そこではあえてガベージコレクションは行われません。 ETSテーブルはほとんどの場合速く、Erlangプログラマがコードがすごく遅くなってしまっている部分を最適化する際に非常に容易に使うことができます。
ETSテーブルは同時に並列して読み書きできる数を制限することができ(プロセスのメールボックスでまったく制限がない状況よりはずっと良いでしょう)、最適化する上で多くの苦労を取り除くことができます。
Don’t Drink Too Much Kool-Aid:
ETSテーブルは最適化において良い方法である一方で、まだまだいくらか注意を払って使う必要があります。 デフォルトでは、VMはETSテーブルを1400個に制限しています。 その数字を変更することは可能です( erl -env ERL_MAX_ETS_TABLES Number )が、デフォルトで低く設定していることは、1プロセスにつき1テーブルを持つような状況を避けるようにするための良い指標となっています。
しかしETSを使ってregisを書きなおす前に、事前にETSの原理について少し理解しておいたほうがいいでしょう。
28.1. ETSのコンセプト¶
ETSテーブルは ets モジュールのBIFとして実装されています。 ETSにある主な設計目標は、Erlang内の大量のデータを保存して一定時間でアクセス出来るようにする方法を提供し(関数型データ構造は通常アクセス時間は最初ログで増加していく傾向があります)、そのようなストレージを、単純で慣れた使い方で扱えるように、プロセスとして実装されたかのように見せることにあります。
Note
プロセスのようなテーブルを持つということは、そのテーブルを生成したり、それにリンクできるということではありませんが、何も共有されず、関数のインターフェースの後ろに呼び出しをラップして、テーブルにあらゆるErlangのネイティブデータ型を扱えるようにさせ、テーブルに(異なるレジストリ内に)名前を登録することができる、ということです。
すべてのETSテーブルは始めから、なんでも好きなErlangタプルを保存することができます。そのタプルの1要素は、ソートなどを行うときに主キーとして扱われます。 つまり、人を表すタプルを {Name, Age, PhoneNumber, Email} の形式としたときに、テーブルは次のようになります:
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
...
したがって、テーブルのインデックスをE-mailアドレスにしたい場合、ETSにキーの位置を4と伝えることでそれを行うことができます。(実際にETS関数呼び出しの説明をする部分になったら、そのやり方について少し見てみましょう) キーを決めたら、データをテーブルに保存する方法を選ぶことができます:
| set: | setテーブルは各キーのインスタンスは一意でなければならないと教えてくれます。 上記の例で言えば、重複するE-mailは一つもありません。 セット(set)テーブルは標準のキーバリューストアを一定時間のアクセスで使う必要があるときに非常に役に立ちます。 |
|---|---|
| ordered_set: | ordered_set では、テーブルにつき1つのキーインスタンスしかもてませんが、いくつか他に面白い機能を付与してくれます。 最も触れるべき機能は、 ordered_set テーブル内の要素は整列してあるということです。(思いも寄りませんでしたね!) テーブルの最初の要素が最小で、一番最後の要素が最大になります。 テーブルを繰り返し走査する(次の要素へと次から次へとアクセスしていく)場合、値は増加していきます。これは set テーブルでは当てはまりません。 順序付きセット(ordered set)テーブルは範囲を指定する操作(12から50の要素がほしい!)を頻繁に行う必要がある場合に優れています。 しかしながら、アクセス時間が遅くなるという欠点もあります。(アクセス時間は O(log N) となります。ここで N は要素数です。) |
| bag: | bagテーブルは同じキーの複数の要素を持っています。このときタプル自体は各々異なっています。 つまり、このテーブルは {key, some, values} と {key, other, values} を問題なく持つことができるということです。これはセットテーブルでは不可能でした。(この2つの例では同じキーである key を持っています。) しかし、 {key, some, values} をテーブル内で2つ持つことはできず、要素全体では一意である必要があります。 |
| duplicate_bag: | バッグ(bag)テーブルのように扱えますが、要素全体が同一のタプルを同じテーブルの中に複数保持することができる点が異なります。 |
Note
順序付きセットテーブルは、1と1.0をすべての操作において同一のものとみなします。 他のテーブルでは別のものとして扱います。
一般的なコンセプトとして最後に知るべきことは、ETSテーブルは、ソケットがそうしていたのと同様に、制御プロセスというコンセプトがあります。 あるプロセスが新しいETSテーブルを起動する関数を呼び出したときに、そのプロセスはそのテーブルを所有することになります。
デフォルトでは、テーブルの所有者だけがテーブルに書き込むことができますが、読み取りはだれもができます。 これはパーミッションの protected レベルとして知られています。 パーミッションを public または private のどちらかにすることもできます。前者では誰もが読み書きでき、後者では所有者だけが読み書きできます。

テーブル所有権の概念をもう少し掘り下げます。 ETSテーブルは最初、プロセスにリンクされています。 プロセスが死ぬと、テーブルは消滅します(そしてその中にあった中身もすべて消えます)。 しかし、テーブルを他の誰かに譲ることができます。ちょうどソケットやその制御プロセスで行なっていたことと同じです。 あるいは、後任プロセスを定義して、所有者プロセスが死んでも、そのテーブルが自動的に後任プロセスに渡されるようにすることもできます。
28.2. ETS Phone Home¶
ETSテーブルを起動するには、 ets:new/2 という関数を呼び出す必要があります。 この関数は Name という引数とオプションのリストを取ります。 戻り値として、テーブルを扱うときに必要となる一意な識別子が渡されます。ちょうどプロセスのPidのようなものです。 オプションは次のいずれかとなります:
| Type = set | ordered_set | bag | duplicate_bag: | |
|---|---|
| 前の節で説明したいように、作りたいテーブルの種類を設定します。 デフォルト値は set です。 | |
| Access = private | protected | public: | |
| 先に説明したようにテーブルのパーミッションを設定します。 デフォルト値は protected です。 | |
| named_table: | 面白いことですが、もし ets:new(some_name, []) と呼び出せば、protectedなセットテーブルを名前がない状態で起動することができます。 テーブル名はテーブルにアクセスするために使われ(一意である必要があります)るので、 named_table というオプションは関数に渡すべきです。 テーブル名を与えれば、純粋に資料化目的に使うこともできますし、 ets:i() のような関数を使った時にも表示されます。この関数はシステム内のすべてのETSテーブルの情報を表示します。 |
| {keypos, Position}: | |
| 覚えていらっしゃるとは思いますが、ETSテーブルはタプルを保存することでできています。 Position 変数は1から N までの整数のいずれかを持っていて、各タプルの何番目の要素をデータベーステーブルの主キーにするかを伝えます。 デフォルトのキーの位置は1に設定されています。 ということは、もしレコードを使っている場合は、各レコードの最初の要素は常にレコードの名前なので(レコードをタプルの形式にした場合を思い出して下さい)注意しなければいけないということです。 もし、好きなフィールドをキーにしたい場合は、 {keypos, #RecordName.FieldName} という形式をつかうと、レコードのタプル形式における FieldName の位置を返してくれるので、これを使いましょう。 | |
| {heir, Pid, Data} | {heir, none}: | |
| 前の節でお話したように、ETSテーブルはそれらの親として動くプロセスを持っています。 もしそのプロセスが死ねば、タプルは消えます。 もしタプルに付与されたデータを生かしておきたいなら、後任を定義するのが便利です。 タプルが付与されたプロセスが死んだときに、後任は {'ETS-TRANSFER', TableId, FromPid, Data} というメッセージを受け取ります。ここで Data は、オプションが最初に定義されたときに渡された要素です。 テーブルは自動的に後任プロセスに継承されます。 デフォルトでは、後任プロセスは定義されません。 ets:setopts(Table, {heir, Pid, Data}) や ets:setopts(Table, {heir, none}) を呼ぶことで、あとで後任プロセスを定義したり、変更することも可能です。 単純にテーブルを譲りたい時は ets:give_away/3 を呼出します。 | |
| {read_concurrency, true | false}: | |
| これは、テーブルへの読み取りの並列性を最適化するオプションです。 このオプションをtrueに設定することで、読み取りのコストは下がりますが、書き込みのコストはものすごく上がります。 基本的に、このオプションは大量の読み取りがあり、書き込みはほとんどなく、よりパフォーマンスが必要な場合に有効にするべきです。 読み取りと書き込みが同様に行われる場合、このオプションを使うとパフォーマンスを損なうことさえあるでしょう。 | |
| {write_concurrency, true | false}: | |
| 通常、テーブルへ書き込むということはすべてをロックし、他の誰も読み取りや書き込みのどちらかいっぽうが、アクセス出来ないようにするということです。 このオプションを’true’にすると、読み取りと書き込みの両方が、ETSのACID特性に影響を与えることなく、並列的に行われます。 しかしながら、このオプションを使うことで、1つのプロセスによる逐次書き込みのパフォーマンスは下がり、また並列読み込みの上限も下がります。 読み取りと書き込みの両方が大量に行われるときに、このオプションと ‘read_concurrency’ のオプションを組み合わせて使うこともできます。 | |
| compressed: | このオプションを使うことで、主キー以外のたいていのフィールドでテーブル内のデータを圧縮させることができます。 このオプションは、次の関数で見るように、テーブル全体の要素を検査することになったときに、パフォーマンスを犠牲にします。 |
さて、テーブルの作成の逆の操作といえばテーブルの破壊です。 テーブルの破壊においては ets:delete(Table) を呼び出す必要があります。ここで Table はテーブルIDか名前付きテーブルの名前です。 テーブル内の1エントリを削除したい場合は、非常によく似た関数呼出しである ets:delete(Table, Key) を呼び出す必要があります。
非常に基本的なテーブルの操作においてはあといくつかの関数を覚える必要があります。 insert(Table, ObjectOrObjects) と lookup(Table, Key) の2つです。 insert/2 の場合は、 ObjectOrObjects は挿入したいタプル1つか、あるいは挿入したいタプルのリストのどちらかになります:
1> ets:new(ingredients, [set, named_table]).
ingredients
2> ets:insert(ingredients, {bacon, great}).
true
3> ets:lookup(ingredients, bacon).
[{bacon,great}]
4> ets:insert(ingredients, [{bacon, awesome}, {cabbage, alright}]).
true
5> ets:lookup(ingredients, bacon).
[{bacon,awesome}]
6> ets:lookup(ingredients, cabbage).
[{cabbage,alright}]
7> ets:delete(ingredients, cabbage).
true
8> ets:lookup(ingredients, cabbage).
[]
lookup 関数がリストを返したことにお気づきでしょうか。 これはテーブルの種類にかかわらず同様で、セットテーブルが常に1要素しか返さないとしても、リストを返します。 これは単純に、あなたがバッグや重複バッグ(1つのキーに対して多くの値を返しうるテーブル)を使っていても、 lookup 関数を汎用的な方法で使えるべきであるということです。
上のスニペットで起きている他の事象としては、同じキーを2回挿入すると、上書きが行われるということです。 これはセットや順序付きセットでは常に起こりますが、バッグや重複バッグでは起きません。 後者2つの状況を割けるためには、 ets:insert_new/2 が便利でしょう。この関数はテーブルにまだ存在していない要素だけを挿入します。
Note
ETSテーブル内のすべてのタプルを同じサイズにすることは、グッドプラクティスとされていますが、必ずしもそうする必要はありません。 しかし、すべてのタプルのサイズは、最低でも主キーの位置と同じ(あるいはそれより大きい)サイズである必要があります。
タプルの一部だけが必要な場合は他のlookup関数を使うこともできます。 その関数は lookup_element(TableID, Key, PositionToReturn) で、これはマッチした要素を返します。(バッグや重複バッグの場合で1つ以上の結果があるばあいはリストを返します。) もし要素がなければ、関数は badarg のエラーを返します。
バッグの場合でやってみましょう:
9> TabId = ets:new(ingredients, [bag]).
16401
10> ets:insert(TabId, {bacon, delicious}).
true
11> ets:insert(TabId, {bacon, fat}).
true
12> ets:insert(TabId, {bacon, fat}).
true
13> ets:lookup(TabId, bacon).
[{bacon,delicious},{bacon,fat}]
これはバッグなので、 {bacon, fat} は2度挿入しても1つしか存在しませんが、それでも’bacon’がキーとなっている要素は複数あることが確認出来ると思います。 ここで他に注目することといえば、テーブルを使うには named_table オプションを渡さない場合は、 TableId を使わなければいけない、ということです。
Note
これらの例を写経している最中に、あなたの手元のErlangシェルがクラッシュしたら、テーブルの親プロセス(Erlangシェル)が消えたことになるので、テーブルは消滅します。
基本操作として最後に触れるのは、テーブルを1つ1つ走査することです。 もしあなたが注意して読んでいたら、 ordered_set テーブルはこれに最適だとわかるでしょう:
14> ets:new(ingredients, [ordered_set, named_table]).
ingredients
15> ets:insert(ingredients, [{ketchup, "not much"}, {mustard, "a lot"}, {cheese, "yes", "goat"}, {patty, "moose"}, {onions, "a lot", "caramelized"}]).
true
16> Res1 = ets:first(ingredients).
cheese
17> Res2 = ets:next(ingredients, Res1).
ketchup
18> Res3 = ets:next(ingredients, Res2).
mustard
19> ets:last(ingredients).
patty
20> ets:prev(ingredients, ets:last(ingredients)).
onions
ご覧のとおり、要素はソート済みで、1つ1つ昇順にも降順にもアクセスできます。 ああ、そうです、境界条件で何が起きるか見る必要がありますね:
21> ets:next(ingredients, ets:last(ingredients)).
'$end_of_table'
22> ets:prev(ingredients, ets:first(ingredients)).
'$end_of_table'
$ で始まるアトムをみたら、それらはOTPチームが何かを伝えようとしている(命名規則によって作られた)特別な値だと意識しましょう。 テーブルの外に反復しようとしたときにはいつでも、 $end_of_table アトムを見ることになります。
さて、これでETSの基本的なキーバリューストアとしての使い方を見てきました。 キーをマッチさせる以上のことが必要になったときに、より応用的な利用方法があります。
28.3. マッチを擦る¶

より特別な機構でレコードを見つけようと思った場合に、ETSには大量の関数があります。
この方法を考えたときに、データの選択をする最適な方法といえばパターンマッチングですよね。 理想的なシナリオは、変数(あるいはデータ構造)の中に適用させるパターンをどうにかして保存しておき、それをなんらかのETS関数に渡して、関数に適切な仕事をしてもらう、といったところでしょう。
これは高階パターンマッチングと呼ばれ、悲しいことにErlangでは利用できません。 事実、高階パターンマッチングが使える言語は非常に少ないです。 代わりに、ErlangにはErlangプログラマが使うことに納得した特殊言語があって、パターンマッチングを大量の標準データ構造として表現するために使われています。
この記法はタプルを基本としていて、ETSにうまく適用するように出来ています。 この記法では変数を指定することができ(通常の変数と、”don’t care”変数)、パターンマッチングををするタプルと一緒になっています。 通常の変数は '$0' 、 '$1' 、 '$2' のように書けます。(数字は結果の受け取り方以外には特に重要な意味はありません) “don’t care”変数は '_' と書けます。 これらのアトムはタプルとして次のように書けます:
{items, '$3', '$1', '_', '$3'}
これは雑に言えば、通常のパターンマッチで {items, C, A, _, C} とするのと等価です。 こう書くことで、最初の要素はアトムで、2番目と4番目は同一のタプルである必要がある、などの情報が分かります。
この記法より実践的な状況で利用するために、2つの関数が利用できます。 match/2 と match_object/2 ( match/3 と match_object/3 もありますが、これらはこの章の範囲外ですし、読者の皆様には詳細は公式ドキュメントを参照してもらいたいと思います)があります。 前者は、パターンの変数を返し、後者はパターンに適用したエントリをすべて返します。
1> ets:new(table, [named_table, bag]).
table
2> ets:insert(table, [{items, a, b, c, d}, {items, a, b, c, a}, {cat, brown, soft, loveable, selfish}, {friends, [jenn,jeff,etc]}, {items, 1, 2, 3, 1}]).
true
3> ets:match(table, {items, '$1', '$2', '_', '$1'}).
[[a,b],[1,2]]
4> ets:match(table, {items, '$114', '$212', '_', '$6'}).
[[d,a,b],[a,a,b],[1,1,2]]
5> ets:match_object(table, {items, '$1', '$2', '_', '$1'}).
[{items,a,b,c,a},{items,1,2,3,1}]
6> ets:delete(table).
true
match/2-3 が関数として良いのは、厳密に返される必要がある結果しか返さない、という点です。 これは先にも述べたように、ETSテーブルは共有しないという理想を追求しているため、役に立ちます。 非常に大きなレコードを持っている場合、必要なフィールドだけをコピーするのは良いことでしょう。 いずれにせよ、変数内の数字はまったく明確な意味がなく、その順番が大事であることにも気づくでしょう。 値の最後のリストが返された場合、 $114 に束縛された値は、パターンによって $6 に束縛された値よりも後に来ます。 もし何もマッチしなければ、空のリストが返されます。
このようなパターンマッチを使って項目を削除することも可能です。 この場合、 ets:match_delete(Table, Pattern) が役に立ちます。

ここまでは順調なので、あらゆる値をおかしな方法でパターンマッチにかけてみましょう。 もし比較や範囲、出力の書式を明示する方法(おそらくリストよりか良い方法)がなどあれば素晴らしいと思いませんか。 いや、待ってください、ありますよ!
28.4. あなたは選ばれました¶
非常に単純なガードを含む、真となる関数の頭で行われるようなパターンマッチに相当するものを知りました。 もしこれまでにSQLデータベースを使ったことがあれば、クエリ内である要素が他の要素と比較して、より大きい、等しい、より小さいなどを調べる方法を見たことがあるかもしれません。 このような機能が欲しいですね。
Erlangの開発者はパターンマッチで見たような構文を使い、十分強力になるように構文をまともじゃない方法で強化しました。 悲しいことに、可読性が下がりました。 次のような見た目になります:
[{{'$1','$2',<<1>>,'$3','$4'},
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}],
['$1']},
{{'$1','$2',<<1>>,'$3','$4'},
[{'<','$3',4.0},{is_float,'$3'}],
['$1']}]
これはかなり醜く、あなたの子供たちに見せたくなるようなデータ構造ではないですね。 信じようと信じまいと、これからこの マッチスペック と呼ばれるものの書き方を学んでいきます。 この形式では書きません。そうですこの形式では書きません。この形式は無条件にちょっと難しすぎます。 まだ読み方さえわかっていませんしね! 次に、もう少し抽象化した場合にどうなるかを示します:
[{InitialPattern1, Guards1, ReturnedValue1},
{InitialPattern2, Guards2, ReturnedValue2}].
さらに抽象化するとこうなります:
[Clause1,
Clause2]
そうです、大まかにいえば、このような形で表現されていて、パターンは関数の頭で、そのあとガードが続いて、最後に関数の本体が続きます。 書式はまだ最初のパターンは '$N' 変数に限られています。この形式はマッチ関数で使ったものとまったく同様です。 新しい節はガードパターンで、これで通常のガードとほぼ同様のことができるようになっています。 [{'<','$3',4.0},{is_float,'$3'}] というようなガードパターンは、 ... when Var < 4.0, is_float(Var) -> ... というガードとほぼ同様です。
次のガードは、より複雑です:
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}]
このガードを読み替えてみると ... when Var4 > 150 andalso Var4 < 500, Var2 == meat orelse Var2 == dairy -> .... となります。お分かりですか。
各演算子やガード関数は前置構文とともに動作して、これは {FunctionOrOperator, Arg1, ..., ArgN} という順番で使っていることを意味します。 したがって、 is_list(X) は {is_list, '$1'} となり、 X andalso Y は {'andalso', X, Y} となる、という具合です。 andalso 、 orelse のような予約語や == のような演算子は、Erlangパーサーが理解できず詰まってしまわないように、アトムの形式にする必要があります。
パターンの最後の節は、何を返したいかです。 必要な変数を書くだけです。 マッチスペックの入力をすべて返したい場合は、 '$_' という変数を使いましょう。 マッチスペックの仕様 はすべてErlangのドキュメントに記載してあります。
前に触れたように、このような形式でのパターンの書き方については学んでいきません。 もっと良い方法があります。 ETSには パース変換 と呼ばれるものが付いてきます。 パース変換は、コンパイルの途中でErlangのパースツリーにアクセスするための、ドキュメント化されていない(したがってOTPチームにサポートされていない)方法です。 この方法によって、勇敢なるErlangプログラマは、ソースコードをモジュール内で代替的な方法で変換できます。 パース変換は、言語構文やトークンを変更しない限り、既存のErlangコードを別のものに変換できます。
ETSに付いてくるパース変換は、それを必要とするモジュールにたいして手で有効化する必要があります。 次のような方法で有効化します;
-module(SomeModule).
-include_lib("stdlib/include/ms_transform.hrl").
...
some_function() ->
ets:fun2ms(fun(X) when X > 4 -> X end).
-include_lib("stdlib/include/ms_transform.hrl"). という行は、モジュール内で ets:fun2ms(SomeLiteralFun) が使われたときはいつでも、その意味を上書きする特別なコードを含んでいます。 高階関数として書くのではなく、パース変換は無名関数内に何があるか(パターン、ガード、戻り値)を解析して、 ets:fun2ms/1 への関数呼び出しを取り除いて、実際のマッチスペックに置き換えます。 変ですか? この方法の最も良い点は、コンパイル時に起こるので、この方法を使うことによるオーバーヘッドが無いことです。
今回は、ファイルでインクルードせずに、シェルで試してみましょう:
1> ets:fun2ms(fun(X) -> X end).
[{'$1',[],['$1']}]
2> ets:fun2ms(fun({X,Y}) -> X+Y end).
[{{'$1','$2'},[],[{'+','$1','$2'}]}]
3> ets:fun2ms(fun({X,Y}) when X < Y -> X+Y end).
[{{'$1','$2'},[{'<','$1','$2'}],[{'+','$1','$2'}]}]
4> ets:fun2ms(fun({X,Y}) when X < Y, X rem 2 == 0 -> X+Y end).
[{{'$1','$2'},
[{'<','$1','$2'},{'==',{'rem','$1',2},0}],
[{'+','$1','$2'}]}]
5> ets:fun2ms(fun({X,Y}) when X < Y, X rem 2 == 0; Y == 0 -> X end).
[{{'$1','$2'},
[{'<','$1','$2'},{'==',{'rem','$1',2},0}],
['$1']},
{{'$1','$2'},[{'==','$2',0}],['$1']}]
すべてうまくいきました! とても簡単に書けるようになりましたね! そしてもちろん、関数はとても読みやすくなりました。 節のはじめで触れた複雑な例もうまくいくでしょうか。 関数にした場合の例を見てみましょう:
6> ets:fun2ms(fun({Food, Type, <<1>>, Price, Calories}) when Calories > 150 andalso Calories < 500, Type == meat orelse Type == dairy; Price < 4.00, is_float(Price) -> Food end).
[{{'$1','$2',<<1>>,'$3','$4'},
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}],
['$1']},
{{'$1','$2',<<1>>,'$3','$4'},
[{'<','$3',4.0},{is_float,'$3'}],
['$1']}]
一見したところ理解しづらいですが、少なくとも変数が数字ではなく名前を持てるようになったことで、これが何を意味しているのかはぐっとわかりやすくなりました。 気をつけなければいけないのは、すべての関数が適切なマッチスペックになるわけではないということです:
7> ets:fun2ms(fun(X) -> my_own_function(X) end).
Error: fun containing the local function call 'my_own_function/1' (called in body) cannot be translated into match_spec
{error,transform_error}
8> ets:fun2ms(fun(X,Y) -> ok end).
Error: ets:fun2ms requires fun with single variable or tuple parameter
{error,transform_error}
9> ets:fun2ms(fun([X,Y]) -> ok end).
Error: ets:fun2ms requires fun with single variable or tuple parameter
{error,transform_error}
10> ets:fun2ms(fun({<<X/binary>>}) -> ok end).
Error: fun head contains bit syntax matching of variable 'X', which cannot be translated into match_spec
{error,transform_error}
関数の頭は単一の変数または単一のタプルである必要があり、戻り値の一部としてガード関数を呼ぶことや、バイナリ内で値を割り当てたりすることなどは許可されていません。 シェルで色々試して、何が出来るのか確認してみてください。
Don’t Drink Too Much Kool-Aid:
ets:fun2ms のような関数は素晴らしいですよね! しかし気をつけなければいけません。 ets:fun2ms はシェル内では動的な関数は扱えます(関数を渡しせば処理してくれます)が、コンパイル済みのモジュール内ではこれはできないということが問題です。
これは、Erlangには関数の種類には、シェル関数とモジュール関数の2つがあることが原因です。 モジュール関数は仮想マシンが理解できる圧縮された形式にコンパイルされます。 これは人間が理解するには難しく、どのように実装されているか検査することはできません。
一方で、シェル関数はまだ評価されていない抽象的な項です。 シェルが評価機を呼べるような方法で作られています。 したがって fun2ms 関数には2つのバージョンがあります。1つはコンパイル済みのコードを受け取った場合のもの、もう一つはシェル内で呼ばれた場合のものです。
これは、異なる種類の関数において置き換え可能ではという点以外は、問題ありません。 つまり、コンパイル済みの関数に対してシェル内で ets:fun2ms を呼ぶことはできませんし、 fun2ms を呼んでいるコンパイル済みのコードに対して、動的な関数を渡すことも出来ないということです。 残念!
マッチスペックを便利にするために、これらを使うのが意味が分かります。 これは、結果の取得には ets:select/2 関数を、 ordered_set テーブルの場合に結果を逆順に取得(他の種類のテーブルでは select/2 と同様です)するには ets:select_reverse/2 を、スペックにマッチした結果の数を知るには ets:select_count/2 を、マッチスペックに適合したレコードを削除するには ets:select_delete(Table, MatchSpec) を使うことで、行うことができます。
早速これを試してみましょう。まずテーブルに入れるレコードを定義して、それからテーブルに色々なものを投入してみましょう:
11> rd(food, {name, calories, price, group}).
food
12> ets:new(food, [ordered_set, {keypos,#food.name}, named_table]).
food
13> ets:insert(food, [#food{name=salmon, calories=88, price=4.00, group=meat},
13> #food{name=cereals, calories=178, price=2.79, group=bread},
13> #food{name=milk, calories=150, price=3.23, group=dairy},
13> #food{name=cake, calories=650, price=7.21, group=delicious},
13> #food{name=bacon, calories=800, price=6.32, group=meat},
13> #food{name=sandwich, calories=550, price=5.78, group=whatever}]).
true
決められたカロリー以下の食べ物を選んでみます:
14> ets:select(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = cereals,calories = 178,price = 2.79,group = bread},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = sandwich,calories = 550,price = 5.78,group = whatever}]
15> ets:select_reverse(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = sandwich,calories = 550,price = 5.78,group = whatever},
#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = cereals,calories = 178,price = 2.79,group = bread}]
あるいは、美味しい食べ物だけを選んでみます:
16> ets:select(food, ets:fun2ms(fun(N = #food{group=delicious}) -> N end)).
[#food{name = cake,calories = 650,price = 7.21,group = delicious}]
削除に関してはちょっと特別なひねりがあります。 パターンの中で必ず return を返さなければいけません:
17> ets:select_delete(food, ets:fun2ms(fun(#food{price=P}) when P > 5 -> true end)).
3
18> ets:select_reverse(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = cereals,calories = 178,price = 2.79,group = bread}]
最後の検索でわかるように、5ドル以上の項目はテーブルから削除されました。
ETS内には、テーブルをリストやファイルに変換したり、( ets:table2list/1 、 ets:tab2file/1 、 ets:file2tab/1 )、テーブルの情報を取得する( ets:i/0 、 ets:info(Table) )などもっと多くの関数があります。 これらを知りたい場合は公式ドキュメントを読まれることをおすすめします。
tv (テーブルビューア)と呼ばれるモジュールもあります。これは特定のErlang VM上のETSテーブルを視覚的に管理ときに使えます。 tv:start() を呼ぶだけで、ウィンドウが開き、テーブルを見せてくれます。
28.5. DETS¶
DETSはETSのディスクベース版で、若干重要な違いがあります。
ordered_set テーブルがないこと、DETSファイルのディスクサイズは2GBに制限されちえること、 prev/1 や next/1 といった操作がほとんで安全ではなく、速くもありません。
テーブルの起動や停止も少し変更されています。 新しいデータベーステーブルは dets:open_file/2 を呼び出すことにより作成されます。 テーブルは dets:open_file/1 を呼び出すことで再度開くことができます。
一方で、APIはほぼ一緒で、したがってファイル内のデータに書き込みを行ったり検索を行ったりするのは極めて簡潔な方法で行うことができます。
Don’t Drink Too Much Kool-Aid:
DETSが遅くなる危険性があるというのはディスクのみのデータベースだからです。 ETSとDETSのテーブルを組み合わせて、RAMとディスクの両方に保存する効率的なデータベースを作ることも可能です。
このようなことをしたくなった場合には、データベースとして Mnesia を調べてみるのが良いでしょう。 これはほぼ同様のことをしますが、シャーディングやトランザクション、分散もサポートしています。
28.6. もうちょっと会話を減らして、もうちょっと働いて下さい¶

かなり長い節タイトル(と長い前節までの解説)に続いて、そもそもここに至った実用的な問題について考えていきます。つまり、regisサーバをETSを使うように更新して、いくつかの潜在的なボトルネックを取り除きます。
話を始める前に、どのように操作を扱って、何が安全で何が安全でないかを考えなければいけません。 安全であるとされるものは、何も変更せず、1回の呼び出し(1度に3回も4回呼び出さない)操作です。 これらは誰でも、何度でも呼び出すことができます。 これ以外の操作というのは、テーブルへの書き込みや、レコードの更新や削除、あるいは多くのリクエストに渡って一貫性を必要とする読み込みは、安全でないと言えます。
ETSにはトランザクションやそれに類するものがないため、安全でない操作はすべてテーブルを所有するプロセスによって行われます。 安全な操作は、公開され、所有プロセスの外からでも呼び出すことができます。 regisサーバを更新するときにはこれらの点を意識しておきましょう。
まずはじめに、 regis-1.0.0 をコピーして regis-1.1.0 とします。 ここで、バージョン番号は3番目の数字ではなく、2番目の数字を変更しました。その理由は、この変更では既存インターフェースを壊すことなく、技術的にはバグフィックスではないので、この変更は機能更新だけであると考えられるからです。
コピー先の新しいディレクトリでは、まずは regis_server.erl だけ変更する必要があります。構造の点で、インターフェースを変更することなく、残りをあまり変更しないで済むようにします:
%%% The core of the app: the server in charge of tracking processes.
-module(regis_server).
-behaviour(gen_server).
-include_lib("stdlib/include/ms_transform.hrl").
-export([start_link/0, stop/0, register/2, unregister/1, whereis/1,
get_names/0]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
code_change/3, terminate/2]).
%%%%%%%%%%%%%%%%%
%%% INTERFACE %%%
%%%%%%%%%%%%%%%%%
start_link() ->
gen_server:start_link({local, ?MODULE}, ?MODULE, [], []).
stop() ->
gen_server:call(?MODULE, stop).
%% Give a name to a process
register(Name, Pid) when is_pid(Pid) ->
gen_server:call(?MODULE, {register, Name, Pid}).
%% Remove the name from a process
unregister(Name) ->
gen_server:call(?MODULE, {unregister, Name}).
%% Find the pid associated with a process
whereis(Name) -> ok.
%% Find all the names currently registered.
get_names() -> ok.
公開されたインターフェースに関しては、 whereis/1 と get_names/0 だけが再実装されます。 それは、先にもお伝えしたように、これらが単一読み込みで安全な操作だからです。 他の操作は、テーブルを所有するプロセス内で、直列化される必要があります。 APIに関しては以上です。 次にモジュールの内部について見てみましょう。
ETSテーブルは、データを格納する目的で使いますので、テーブルを init 関数の中に書くことは理にかなっているでしょう。 さらに、 whereis/1 と get_names/0 の2つの関数は、テーブルに対して公開されたアクセスを与えます。(アクセスの速さのためです)したがって、外からアクセス出来るようにテーブルに名前を付けることが必要になります。 プロセスに名前を付けたときと同様に、テーブルに名前を付けることで、関数に直接テーブル名を渡すことができ、テーブルのidを渡して回らずに済みます。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%% GEN_SERVER CALLBACKS %%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
init([]) ->
?MODULE = ets:new(regis, [set, named_table, protected]),
{ok, ?MODULE}.
次の関数は handle_call/3 です。この関数は、 register/2 で定義された {register, Name, Pid} というメッセージを扱います。
handle_call({register, Name, Pid}, _From, Tid) ->
%% Neither the name or the pid can already be in the table
%% so we match for both of them in a table-long scan using this.
MatchSpec = ets:fun2ms(fun({N,P,_Ref}) when N==Name; P==Pid -> {N,P} end),
case ets:select(Tid, MatchSpec) of
[] -> % free to insert
Ref = erlang:monitor(process, Pid),
ets:insert(Tid, {Name, Pid, Ref}),
{reply, ok, Tid};
[{Name,_}|_] -> % maybe more than one result, but name matches
{reply, {error, name_taken}, Tid};
[{_,Pid}|_] -> % maybe more than one result, but Pid matches
{reply, {error, already_named}, Tid}
end;
この関数は、モジュールの中でで最も複雑な関数です。 準拠すべき3つの規則があります:
- あるプロセスは2回登録できない
- ある名前は2回登録できない
- 規則1と2を破らない限り、プロセスは登録できる
これが上のコードが行なっていることです。 fun({N,P,_Ref} when N==Name; P==Pid -> {N,P} end 由来のマッチスペックはすべてのテーブルを走査して、登録しようとしている名前かプロセスIDに一致するエントリを探します。 もし一致するものがあれば、見つかったものの名前とPidを返します。 両方を返すのは変かもしれませんが、後に続く case ... of にあるパターンを見ると両方が必要になることが分かります。
最初のパターンは何も見つからなかった場合なので、登録しても大丈夫です。 登録したプロセスを(失敗した場合に登録削除するために)監視して、テーブルにエントリを追加します。 登録しようとしている名前がすでにテーブルに存在している場合、 [{Name,_}|_] というパターンがその処理を行います。 もし登録しようとしているPidがテーブルに存在している場合、 [{_,Pid}|_] というパターンがその面倒を見ます。 これが名前とPidの両方を返した理由です。こうすると後に出てくるタプルすべてにマッチするのが単純になり、マッチスペックの中で名前とPidのどちらが一致したかを気にしなくて済みます。 なぜ [Tuple] という形式ではなく [Tuple|_] という形式を使うのでしょうか。 その理由は簡単に説明できます。 テーブルを走査してPidや名前を探している場合に、似たPidや名前があれば、 [{NameYouWant, SomePid},{SomeName,PidYouWant}] というリストが返ってくる可能性があります。 もしこのようなリストが返ってきたら、 [Tuple] という形式のパターンは、テーブルを管理しているプロセスをクラッシュさせ、あなたの一日を無駄にしてしまいます。
ああ、そうでした、モジュールに -include_lib("stdlib/include/ms_transform.hrl"). を追加するのを忘れないようにしてください。そうしないと、 fun2ms はおかしなエラーメッセージを吐いて死にます:
** {badarg,{ets,fun2ms,
[function,called,with,real,'fun',should,be,transformed,with,
parse_transform,'or',called,with,a,'fun',generated,in,the,
shell]}}
インクルードファイルを忘れると、このようなエラーメッセージが表示されます。 警告しましたよ。 道を渡る前には左右を確認する、激流を横切ってはいけません、そしてインクルードファイルを忘れてはいけません。
次は、プロセスの登録削除を手動で行う部分です:
handle_call({unregister, Name}, _From, Tid) ->
case ets:lookup(Tid, Name) of
[{Name,_Pid,Ref}] ->
erlang:demonitor(Ref, [flush]),
ets:delete(Tid, Name),
{reply, ok, Tid};
[] ->
{reply, ok, Tid}
end;
古いバージョンのコードを見ると、まだ似ていることが分かります。 考えは単純です。(プロセス名を使って)モニターの参照先を見つけ、モニターを解除し、エントリを削除します。 エントリがない場合は、とにかくそれを削除したふりをしておけば、みんなが幸せになります。 ああ、なんて嘘つきなんでしょう。
次はサーバの停止に関してです:
handle_call(stop, _From, Tid) ->
%% For the sake of being synchronous and because emptying ETS
%% tables might take a bit longer than dropping data structures
%% held in memory, dropping the table here will be safer for
%% tricky race conditions, especially in tests where we start/stop
%% servers a lot. In regular code, this doesn't matter.
ets:delete(Tid),
{stop, normal, ok, Tid};
handle_call(_Event, _From, State) ->
{noreply, State}.
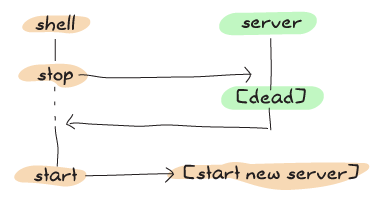
コード中のコメントにあるように、ただテーブルを無視してガベージコレクションの対象にすればいいです。 しかし、前章で書いたテストスイートは常にサーバの起動や停止をするので、遅延は若干危険です。 次の図は、古いサーバでのプロセスのタイムラインです:
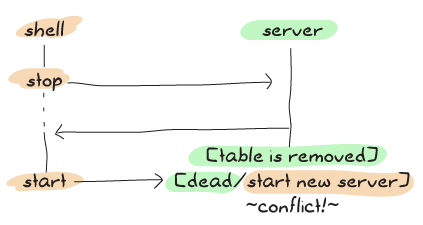
そして、新しいサーバでのタイムラインはこうなります:
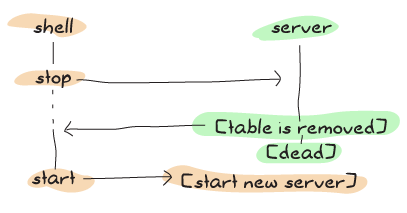
上記のスキームを使うと、コードの同期の部分を増やすことによって、ぐっとエラーが起きにくくしています:
テストスイートをそんなに頻繁に走らせるつもりがないのであれば、すべてただ無視していいでしょう。 テストでないシステムにおいては、このような稀な例は滅多に起きませんが、このような扱いにくいエラーがあるということをお見せしたかったのです。
残りのOTPコールバックは次のようにします:
handle_cast(_Event, State) ->
{noreply, State}.
handle_info({'DOWN', Ref, process, _Pid, _Reason}, Tid) ->
ets:match_delete(Tid, {'_', '_', Ref}),
{noreply, Tid};
handle_info(_Event, State) ->
{noreply, State}.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) ->
ok.
DOWN というメッセージを受け取ること以外には、特に気にしていません。 DOWN というメッセージは、監視しているプロセスの中の1つが死んだことを意味します。 これが発生したときには、メッセージ中にある参照先に基いてエントリを削除して、通常の動作に戻ります。
code_change/3 は、実際には古い regis_server から新しい regis_server への移行行なっています。 この関数の実装は読者の演習としましょう。 私もよく読者に解答を教えないままにする演習がある技術書を手にしますが、私はそのような本を書く間抜けな著者ではではないので、少なくともちょっとだけヒントをあげます。 新しいバージョンに移行するまえに、古いバージョンにある2つの gb_trees のどちらかをとって、 gb_trees:map/2 か gb_trees イテレータを使って新しいテーブルを投入しなければいけません。 ダウングレード関数は逆のことをすることで書けます。
残されているのは、まだ実装しないままになっている2つの公開されている関数を修正することです。 もちろん、 %% TODO というコメントを書いて、仕事を切り上げて、飲みに行って自分がプログラマであることを忘れるほど飲む、という選択もできますが、それはちょっと無責任です。 修正しましょう:
%% Find the pid associated with a process
whereis(Name) ->
case ets:lookup(?MODULE, Name) of
[{Name, Pid, _Ref}] -> Pid;
[] -> undefined
end.
これは名前を探して、エントリが見つかったかどうかに応じて Pid または undefined を返します。 ここで regis ( ?MODULE )をテーブル名として使っていることをに注意してください。 これが、最初この関数をprotedtedにして、名前をつけていた理由です。 もう1つはこのように実装します:
%% Find all the names currently registered.
get_names() ->
MatchSpec = ets:fun2ms(fun({Name, _, _}) -> Name end),
ets:select(?MODULE, MatchSpec).
再び fun2ms を使って、 Name をマッチさせ、そのままにしておきます。 テーブルからの検索はリストを返し、私たちに必要な処理をします。
これで終わりです! テストスイートを test/ で実行して、動作させてみましょう:
$ erl -make
...
Recompile: src/regis_server
$ erl -pa ebin
...
1> eunit:test(regis_server).
All 13 tests passed.
ok
やりました。これで、ETSに関してはかなり理解したと思っていいでしょう。
次に何をしたらいいと思いますか。 Erlangの分散に関する側面を色々と見てみるのがいいでしょう。 Erlangという野獣を倒すまでに、あといくつかあるややこしい部分に専念しましょう。 それでは見てみましょう。