13. マルチプロセスについてもっと¶
13.1. 状態を教えたらどうだい(State Your State)¶

前の章で紹介された例はデモをするにはいいんですが、それだけではなにかツールを作るときには不便です。 例が悪いというわけではなく、関数とメッセージだけではプロセスとアクターを使いこなせないということです。 その状態を改善するために、プロセスの状態を保持出来るようにならなければいけません。
まず最初に新しい kitchen.erl モジュールで関数を作ってみます。その関数はプロセスに冷蔵庫のような動作をさせます。プロセスは2つの操作ができます: 食べ物を冷蔵庫に保存して、冷蔵庫から食べ物を取り出します。 食べ物を取り出す前には事前に保存されてなければなりません。 次の関数はこのプロセスの基礎として動作します:
-module(kitchen).
-compile(export_all).
fridge1() ->
receive
{From, {store, _Food}} ->
From ! {self(), ok},
fridge1();
{From, {take, _Food}} ->
%% uh....
From ! {self(), not_found},
fridge1();
terminate ->
ok
end.
何かがおかしいです。食べ物を保存するように聞くと、プロセスはokを返すべきです。 しかし実際に食べ物を保存する部分が全くありません。 fridge1() が呼び出されて、関数は何もない状態、つまり状態がない状態で起動します。 また、冷蔵庫から食べ物を取り出そうとプロセスを起動したときに、取り出す状態が全くないので、返せる物が not_found しかないこともわかります。 食べ物を保存したり取り出したりするためには、関数に状態を追加する必要があります。
再帰のおかげで、プロセスの状態は関数のパラメータの中にすべて保持出来ます。 冷蔵庫プロセスの場合は、リストの形ですべての食物を保存しておき、誰かが何か食べたいと思った時にそのリストを見る、というような方法が考えられます:
fridge2(FoodList) ->
receive
{From, {store, Food}} ->
From ! {self(), ok},
fridge2([Food|FoodList]);
{From, {take, Food}} ->
case lists:member(Food, FoodList) of
true ->
From ! {self(), {ok, Food}},
fridge2(lists:delete(Food, FoodList));
false ->
From ! {self(), not_found},
fridge2(FoodList)
end;
terminate ->
ok
end.
最初に気づくことは fridge2/1 は FoodList という引数を一つ取るということです。 {From, {store, Food}} というメッセージを送ると、関数は次の呼び出しに行く前に Food を FoodList に追加します。 再帰呼び出しが行われると、同じ食べ物を取り出すことが出来るようになります。事実、そこに実装しました。 関数は Food が FoodList の中にあるかどうかを lists:member/2 を使って調べています。 結果に応じて、食べ物が呼び出し元に返される(そして FoodList から削除される)か、 not_found が返されます:
1> c(kitchen).
{ok,kitchen}
2> Pid = spawn(kitchen, fridge2, [[baking_soda]]).
<0.51.0>
3> Pid ! {self(), {store, milk}}.
{<0.33.0>,{store,milk}}
4> flush().
Shell got {<0.51.0>,ok}
ok
食べ物を冷蔵庫に保存する部分は動作しているように見えます。 もうちょっと試してみて、冷蔵庫から物を取り出してみましょう。
5> Pid ! {self(), {store, bacon}}.
{<0.33.0>,{store,bacon}}
6> Pid ! {self(), {take, bacon}}.
{<0.33.0>,{take,bacon}}
7> Pid ! {self(), {take, turkey}}.
{<0.33.0>,{take,turkey}}
8> flush().
Shell got {<0.51.0>,ok}
Shell got {<0.51.0>,{ok,bacon}}
Shell got {<0.51.0>,not_found}
ok
期待通り、ベーコンは最初に(ミルクとベーキングソーダと一緒に)入れておいたのでを冷蔵庫から取り出すことが出来ます。 しかし冷蔵庫プロセスには七面鳥がないので返せません。 これが {<0.51.0>,not_found} というメッセージを得る理由です。
13.2. メッセージ大好きだけど秘密にしておいて¶
前述の例でイライラするところは、冷蔵庫を使うプログラマがそのプロセスのために作られたプロトコルを知っていなければならないということです。 これは意味のない負担です。これを解消するのに良い方法は、メッセージの受信と送信を扱う関数を使ってメッセージを抽象化することです:
store(Pid, Food) ->
Pid ! {self(), {store, Food}},
receive
{Pid, Msg} -> Msg
end.
take(Pid, Food) ->
Pid ! {self(), {take, Food}},
receive
{Pid, Msg} -> Msg
end.
これでプロセスとのやりとりはずっとすっきりしました:
9> c(kitchen).
{ok,kitchen}
10> f().
ok
11> Pid = spawn(kitchen, fridge2, [[baking_soda]]).
<0.73.0>
12> kitchen:store(Pid, water).
ok
13> kitchen:take(Pid, water).
{ok,water}
14> kitchen:take(Pid, juice).
not_found
self() や、 take や store のようなアトムが必要な場合に、もうメッセージがどのように動作するかは気にしなくてよくなりました。 必要なのはpidとどの関数を呼び出せば良いかだけです。 これによって、泥臭い仕事はしなくて住むようになりますし、冷蔵庫プロセスを作るのも簡単になります。
1つだけやり残したことと言えば、プロセスをspawnする必要がある部分全体です。 メッセージを扱う部分は隠しましたが、まだユーザにプロセスの起動を期待しています。 次の start/1 関数を追加しましょう:
start(FoodList) ->
spawn(?MODULE, fridge2, [FoodList]).
ここで ?MODULE は現在のモジュール名を返すマクロです。 このような関数を書く意味はないように思えますが、実際はいくらか意味があります。 ここで本質的なのは、 take/2 と store/2 の一貫性です。 いまや冷蔵庫プロセスに関する全てはキッチンモジュールで処理されます。 いつfridgeプロセスが起動したかをログを取ったり、2つ目のプロセス(たとえばfreezer)を追加したりする場合、 start/1 関数に追加するだけで簡単に出来るようになります。 しかしながら、もしspawnする部分がユーザに sapwn/3 を使って行わせるまま残ったとしたら、 fridge を立ち上げる場所では必ず呼び出しが必要になります。 これがくだらないいくつものエラーを引き起こしやすくするのです。
では start 関数を使ってみるましょう:
15> f().
ok
16> c(kitchen).
{ok,kitchen}
17> Pid = kitchen:start([rhubarb, dog, hotdog]).
<0.84.0>
18> kitchen:take(Pid, dog).
{ok,dog}
19> kitchen:take(Pid, dog).
not_found
すごい!犬が冷蔵庫から出てきました!抽象化は完璧です!
13.3. タイムアウト¶
pid(A,B,C) というコマンドを使ってちょっとしたことをしてみましょう。 このコマンドを使うと、3つの整数A,B,Cをpidに出来ます。 ここでは用心しながら kitchen:take/2 を実行してみましょう。
20> kitchen:take(pid(0,250,0), dog).
おっと、シェルが固まってしまいました。これは take/2 の実装方法が原因で起きました。 何が起きているか理解するために、通常の場合に何が起きているか復習してみましょう:
- 食べ物を保存するメッセージがあなた(シェル)から冷蔵庫プロセスに送られる。
- あなたのプロセスは受信モードに切り替わって、新しいメッセージを待ちます
- 冷蔵庫は食べ物を保存して、’ok’をあなたのプロセスに送ります
- あなたのプロセスは返ってきたメッセージを受け取って、プロセスの生存時間を長らえます

で、これがシェルが固まるときに起きることです:
- 食べ物を保存するためのメッセージがあなた(シェル)から不明なプロセスに送られます
- あなたのプロセスは受信モードに切り替わって、新しいメッセージを待ちます
- 不明なプロセスは存在するのか、はたまたそのようなメッセージを受け付けるのか分からず、送られてきたメッセージに対して何もしません
- あなたのシェルプロセスは受信モードのまま固まってしまいます
これは腹立たしいですね。特に、エラー処理がここではまったく出来ないのがイライラします。 何も間違ったことは起きていないので、プログラムはただ待っているだけなのです。 一般的に、非同期処理を行うときは(Erlangではメッセージパッシングで行われます)一定時間を過ぎてもデータを取得できる気配がなければ、諦めるようにする方法が必要です。 Webブラウザはページや画像の取得に時間がかかりすぎる場合はそういったことを行っています。ほかにも電話しているときに相手が全然答えなかったり、ミーティングを遅くにやろうとした場合は、あなたもこういったことをすると思います。 Erlangはこういった状況に対して適切な機構を持っていて、受信機構に組み込まれています:
receive
Match -> Expression1
after Delay ->
Expression2
end.
receive と after の間にある部分がまさにそれです。 Match パターンを満たすメッセージを受けとることなく Delay (ミリ秒を表す整数)だけ経過したら、after節が動作します。 その場合は Expression2 が実行されます。
store2/2 と take2/2 という2つの新しいインターフェース関数を書きましょう。 これは store/2 や take/2 とほぼ同じように動作しますが、3秒経過後にメッセージを待つのを辞めるというところだけ違います:
store2(Pid, Food) ->
Pid ! {self(), {store, Food}},
receive
{Pid, Msg} -> Msg
after 3000 ->
timeout
end.
take2(Pid, Food) ->
Pid ! {self(), {take, Food}},
receive
{Pid, Msg} -> Msg
after 3000 ->
timeout
end.
さて、 ^G と打ってシェルを元に戻して、新しいインターフェース関数を試してみましょう:
User switch command
--> k
--> s
--> c
Eshell V5.7.5 (abort with ^G)
1> c(kitchen).
{ok,kitchen}
2> kitchen:take2(pid(0,250,0), dog).
timeout
今度は動きました。
Note
after 節は値としてミリ秒しか受け付けないと言いましたが、 infinity というアトムも受け付けます。 これは多くの場合では役に立たない( after 節を取り除くことになるでしょう)一方で、プログラマが結果を受け取ることが予想される関数に待ち時間を送信することができるのです。 つまりプログラマが本当に永遠に待機したければできるわけです。
長く待ちすぎたときに諦めるのではなく、こういったタイマーを使うところがあるわけです。 とても単純な例としては、さきほど使った timer:sleep/1 がどのように動作するかを見ればわかります。 ここにその関数がどうやって実装されているかお見せします(これを新しい multiproc.erl に書きましょう):
sleep(T) ->
receive
after T -> ok
end.
この特殊な例では、パターンが1つもないため receive 節ではどんなメッセージもマッチしません。 代わりに after 節は T だけ経過したら呼ばれます。
他の特殊な例としては、タイムアウトが0のときです:
flush() ->
receive
_ -> flush()
after 0 ->
ok
end.
こうなった場合、Erlang VMは存在するパターンに適用するメッセージを探そうとします。 上の例の場合、なんでもマッチします。メッセージがある限り、 flush/0 関数はメールボックスがカラになるまで自分自身を再帰呼び出しします。 それが終わると、 after 0 -> ok の部分が実行されて、関数は返り値を戻します。
13.4. 選択的receive¶
この「フラッシュする」概念によって、 選択的receive を実装することが出来ます。 それは入れ子の呼び出しによって、受け取るメッセージに優先順位をつけることができる方法です:
important() ->
receive
{Priority, Message} when Priority > 10 ->
[Message | important()]
after 0 ->
normal()
end.
normal() ->
receive
{_, Message} ->
[Message | normal()]
after 0 ->
[]
end.
この関数はすべてのメッセージを優先度が10より大きいメッセージが最初にくるようなリストを作ります:
1> c(multiproc).
{ok,multiproc}
2> self() ! {15, high}, self() ! {7, low}, self() ! {1, low}, self() ! {17, high}.
{17,high}
3> multiproc:important().
[high,high,low,low]
after 0 を使ったので、すべてのメッセージが取得されました。 しかしプロセスは normal/0 の中で集められるような他のメッセージを考慮する前に、優先度が10より大きいメッセージを取得しようとします。
もしこの例が面白いと思ったら、Erlangでの選択的receiveのやり方のせいでいくばくか安全でないことに注意してください。
メッセージがプロセスに送られたとき、メッセージはプロセスが読み込むまでメールボックスに保存されます。 そして読み込まれたときにパターンマッチが行われます。前の章で述べたように、メッセージは受け取った樹にに保存されます。 これはつまりメッセージをマッチさせるとき、扱っているメッセージは最も古い物であるということです。
最も古いメッセージは receive のすべてのパターンの中からマッチするがあるまでチェックされます。 それが行われた後、メッセージはメールボックスから削除されて、プロセスのコードは次の receive まで普通に実行されます。 この次のメッセージが評価されたら、VMはその時点でメールボックス内で一番古いメッセージを探し(次から次に削除していきます)、動作を続けます。
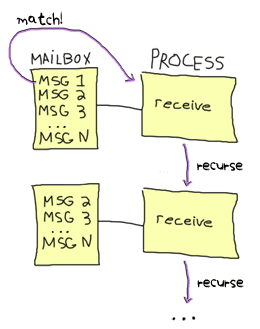
与えられたメッセージがどうにもマッチしない場合、 保存キュー に入れられて、次のメッセージのパターンマッチが始まります。 もし2番目のメッセージがマッチした場合、最初のメッセージはメールボックスの最初に置かれて、あとで再度パターンマッチされます。
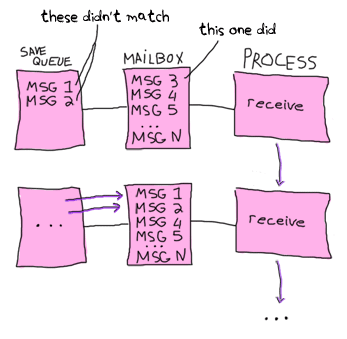
これによって、使えるメッセージだけ気にすれば良くなります。 上で述べたような、あとで処理するためにいくつかのメッセージは無視するというやり方は、選択的receiveの本質です。 このやり方は役に立つ一方で、問題はもしプロセスに大量の無視したメッセージがあった場合、使えるメッセージを読み込むのにものすごく長い時間がかかってしまうということです。(プロセスのサイズも大きくなります)
上の絵で、367番目のメッセージが欲しいけれど、その前の366個のメッセージが使い物にならず、上のコードで無視された、という状況を想定してください。 367番目のメッセージを取得するには、プロセスはそれより前の366個のメッセージをまずパターンマッチする必要があります。 それが終わったら、それらすべてがキューに入れられて、367番目のメッセージが取り出されて、最初の366個がメールボックスの先頭から戻されていきます。 次の役に立つメッセージはもっと深くに詰め込まれて、探すのにもっと長い時間がかかる可能性があります。
このようなreceiveはErlangでのパフォーマンス問題のよくある原因となります。 もしアプリケーションの動作が遅く、多くのメッセージが飛び交ってるところがあると分かっていたら、そこが原因になり得ます。
もしそのような選択的receiveが、書いたコードを強烈に遅くしている原因ならば、まず最初にすべきことは何故必要のないメッセージを受け取っているのかと自問することです。 メッセージは正しいプロセスに送られていますか?パターンは正しいですか?メッセージが間違った形式になってませんか?たくさん存在すべきプロセスが1プロセスになっていませんか? 今挙げた質問の中の1つ、あるいは多くに答えることで問題が解決する可能性があります。
不必要なメッセージでプロセスのメールボックスを汚染するリスクがあるので、Erlangプログラマーは時々そのようなイベントに対して決定的な手段を取ります。 標準的なやり方は次のようになるでしょう:
receive
Pattern1 -> Expression1;
Pattern2 -> Expression2;
Pattern3 -> Expression3;
...
PatternN -> ExpressionN;
Unexpected ->
io:format("unexpected message ~p~n", [Unexpected])
end.
ここでやっていることはどんなメッセージでも少なくとも一つの節にはマッチするようにしているということです。 Unexpected 変数はどんなものにもマッチし、メールボックスから予期しないメッセージを取り出して、警告を表示します。 アプリケーションに依存して、あとで情報を探せるようにメッセージをなんらかのロギング機構に保存したいと思うでしょう。 もしメッセージが間違ったプロセスに入ってしまったら、永遠にそのメッセージを失うという残念なことになり、なぜ他のプロセスがreceiveすべきメッセージをreceiveできなかったのか苦悩する日々を味わうことになります。
メッセージで優先度を扱う必要があって、catch-all節のようなものを使えない場合、 min_heap を実装するか、 gb_trees モジュールを使ってすべての受信したメッセージをその中にダンプするのがもっとも賢い方法でしょう。(優先度番号をキーとして、メッセージをソート出来るようにしておく必要があります) そうすると必要なデータ構造に応じて最小値や最大値の要素を検索するすることが出来ます。
たいていの場合、このテクニックによって選択的receiveよりもずっと効率的に優先度付きメッセージを受信出来ます。 しかし、ほとんどのメッセージが最高の優先度となっていた場合、実行速度が落ちるでしょう。 いつもどおり、コツはプロファイルを取って、最適化の前に計測を行うことが必要です。
Note
R14Aから、Erlangコンパイラに新しい最適化が追加されました。 それによって、プロセス間であちこちにやり取りされる非常に限定的な状況での選択的receiveが単純化されます。 そのような関数の例は multiproc.erl 内の optimized/1 関数です。
動作させるためには、リファレンス(make_ref())が関数内に作られていて、それからメッセージが送られる必要があります。 それから同一関数内で選択的receiveが作られます。 もしメッセージが同じリファレンスを持っていなくてマッチしない場合、コンパイラは自動的にVMがそのリファレンスが作成される前に受信されたメッセージを読み飛ばすようにします。
コードを無理矢理この最適化に適応させるように変更すべきではないことに注意してください。 Erlangの開発者は頻繁に使われるパターンを探して、それを速くすべきです。 もし自然な表現のコードを書いたら、最適化はそこで行われています。 逆はありえません。
この概念が分かった上で、次はマルチプロセス下でのエラー処理についてです。