3. (本当に)始めましょう!¶
Erlangは比較的小さくてシンプルな言語です(CがC++よりもシンプルだという意味で) 言語内にいくつかの基本的なビルトイン型が定義されているだけで、この章でそのほとんどはカバーされます。 今後出てくるすべてのErlangプログラムの構成要素について説明しているので、この章を読むことを強くおすすめします。
3.1. 数字¶
Erlangシェルでは 式はピリオドで終わって、その後に空白を入れなければいけません 。(改行や空白など) そうしないとコードは動きません。式はカンマで区切ることが出来ますが、最後の式の結果だけが返されます。 (それ以外の式は実行はされます)このシンタックスはたぶんほとんどの人にとって馴染みのないものでしょう。 このシンタックスはErlangが論理言語のPrologで直接実装されていた時代の名残です。
前の章で設営したようにErlangシェルを開いて、次のコードを打ってみましょう!
1> 2 + 15.
17
2> 49 * 100.
4900
3> 1892 - 1472.
420
4> 5 / 2.
2.5
5> 5 div 2.
2
6> 5 rem 2.
1
Erlangでは浮動小数と整数の区別をしていないことに気がつくでしょう:両方の型ともに算術を行うときはサポートされています。整数と浮動小数はErlangの算術演算子が唯一透過的に処理する型です。 しかし、整数と整数の割り算をしたい場合は div を使います。そしてモジュロ演算をしたいときは rem (remainder、余り)を使います。

1つの命令でいくつかの演算子を使えることに注意してください。算術演算子は通常の優先ルールに従います。
7> (50 * 100) - 4999.
1
8> -(50 * 100 - 4999).
-1
9> -50 * (100 - 4999).
244950
整数を10進数以外で表現したい場合は、数字を Base#Value の形で書けばいいだけです。(Base,基数は2から36の間です):
10> 2#101010.
42
11> 8#0677.
447
12> 16#AE.
174
すごい!Erlangには、あなたの机の隅っこに置いてある電卓に奇妙なシンタックスがくっついたようなものなのです!完全にすばらしい!
3.2. 変化できない変数¶
計算に関してはこれで大丈夫ですね。でも結果をどこかに保存できないと先へ進めません。そのために、変数を使います。 この本のイントロダクションを読んでいたら、関数型プログラミングでは変数は変化できないと知っているはずです。 変数の基本的な動作は次の7つの操作でわかります。(変数は大文字から始まることに気をつけてください)
1> One.
* 1: variable 'One' is unbound
2> One = 1.
1
3> Un = Uno = One = 1.
1
4> Two = One + One.
2
5> Two = 2.
2
6> Two = Two + 1.
** exception error: no match of right hand side value 3
7> two = 2.
** exception error: no match of right hand side value 2
まず、これらのコマンドは値を変数に与えることは1回しかできないということを教えてくれます。それから変数に同じ値がすでに入っている場合は変数を与える「ふり」ができます。違う値だったら、Erlangは警告します。 それは正しい観察ですが、説明はもうちょっと複雑で、 = 演算子に依存したものになります。 = 演算子(変数ではありません)は比較の役割も果たしていて、値が違っていたらエラーを出します。値が同じだったら、 = 演算子は値を返します:
8> 47 = 45 + 2.
47
9> 47 = 45 + 3.
** exception error: no match of right hand side value 48
変数とごちゃまぜになったときにこの演算子がすることは、左手側の項が変数で束縛されていなかった場合(まだ値が与えられていなかった場合)、Erlangは自動的に右手側の値を左手側の変数に束縛します。比較は結果として成功となり、変数はメモリに値を保存します。
= 演算子の動作は”パターンマッチング”と呼ばれるものの基礎になっています。 パターンマッチングは多くの関数型プログラミング言語に備わっている機能ですが、Erlangでは他の言語に比べてより柔軟で完全なものとされています。 パターンマッチングについてはこの章のタプル型とリスト型の部分でより詳細に触れますし、関数内で使う場合については後続の章で触れます。
上の1から7のコマンドで他にわかることは、変数名は大文字で始めなければいけないということです。 7番目のコマンドは”two”という単語は小文字から始まっているのでエラーになっています。 技術的には、変数はアンダースコア (‘_’) から始めてもかまいません。しかし規約としては、アンダースコアを使うのは使わないけれど、何を持っているかドキュメントに記載しておかなければいけないような変数に限られています。
アンダースコアだけの変数も使うことができます:
10> _ = 14+3.
17
11> _.
* 1: variable '_' is unbound
他のどんな変数とも違って、アンダースコアだけの変数はどんな値も保存しません。 いまは全く使う必要がないけれど、必要になったときは使うことが出来ます。
Note
シェルでテストをしていて、変数に間違った値を保存してしまった場合は、関数 f(Variable) を使って変数を「消す」ことができます。 すべての変数名を消したい場合は f() を実行してください。
これらの関数はテストをするときだけ、しかもシェル内だけで使えます。 実際のプログラムで書いている場合はこういう形で値を消すことは出来ません。 シェルでしかこれができないというのは、Erlangが工業的なシナリオで使えるとわかれば、理にかなっています:シェルを何年も起動しっぱなしにすることも可能です...起動している間に変数Xが一度以上使われているか賭けてみましょう!
3.3. アトム¶
変数名が小文字から始められないのには理由があります。アトムです。 アトムはリテラルで、自分自身の名前を値として保持しています。見たままを値として得て、それ以外何もありません。 アトムcatは”cat”ということで、それだけです。遊ぶ余地もなければ、変更もできません。バラバラに分解することもできません。それは cat なのです。間違いなく。
アトムは小文字から始まる一単語ですが、他にもアトムを作る方法があります:
1> atom.
atom
2> atoms_rule.
atoms_rule
3> atoms_rule@erlang.
atoms_rule@erlang
4> 'Atoms can be cheated!'.
'Atoms can be cheated!'
5> atom = 'atom'.
atom
アトムは、小文字以外の文字、あるいはアンダースコア(_)や@など英数字以外から始まっている場合はシングルクォート(‘)で囲まれている必要があります。 5番目の表現はシングルクォートで囲まれたアトムはシングルクォートで囲まれていないアトムと変わりがないことを示しています。
私はアトムを自分自身の値を持った定数とみなしています。過去に定数を使ったコードに触れたことがあるでしょう:たとえば、目の色を表す値をこんなふうに決めたりします BLUE -> 1, BROWN -> 2, GREEN -> 3, OTHER -> 4 この場合、定数名と値を対応させなければいけません。 アトムを使えば、値を対応させるという作業から開放されます。目の色は簡潔に ‘blue’, ‘brown’, ‘green’, ‘other’ と書けます。 この色はコード中どこでも使えます。値が衝突することもなければ、定数が未定義になることもありません! もし、値が結びついた定数を本当に使いたい場合は、第4章( モジュール )でその方法に触れます。
アトムはアトムに結びついたデータを表現するときとそのデータを制限するときに役立ちます。アトムだけで使うと、良い使い道を見つけるのはちょっと難しいです。 なので、アトムだけで遊ぶのはこれ以上しません。一番の使い道は他のデータ型と一緒に使うとわかります。
Don’t drink too much Kool-Aid
アトムはメッセージや定数を送るときに非常に便利です。 しかし、多くのことにアトムを使い過ぎると落とし穴があります。アトムは「アトム表」を参照しているわけですが、これはメモリを消費します。(1アトムにつき32ビットシステムでは4バイト、64ビットシステムでは8バイトそれぞれ消費します) アトム表はガベージコレクトの対象にならないので、アトムはシステムが落ちるか、1048577個のアトムが宣言されるまで蓄積していきます。
これはつまり、アトムはどのような理由があっても動的に生成すべきではないということを意味します。 もしシステムの信頼を高める必要がある場合に、ユーザがアトムを生成することができて、それによってシステムをクラッシュさせることができてしまうような状況では、とても深刻な問題に陥るでしょう。 アトムは開発者のためのツールとみなしたほうがよいでしょう。なぜならはっきり言って見た目そのままだからです。
Note
いくつかのアトムは予約語で、言語設計者が意図した方法以外で使われるべきでありません。 それらには関数名、演算子、式などがあります。以下がその予約語です: after and andalso band begin bnot bor bsl bsr bxor case catch cond div end fun if let not of or orelse query receive rem try when xor

3.4. ブール代数と比較演算子¶
大小関係やtrueとfalseを区別出来なかったらとてもとても困ったことになります。 他の言語と同様に、Erlangでもブール演算子を使ったり、物を比較する方法があります。
ブール代数は単純です:
1> true and false.
false
2> false or true.
true
3> true xor false.
true
4> not false.
true
5> not (true and true).
false
Note
ブール演算子の and と or は常に両側の引数を評価します。 もし短絡演算子(右側の引数だけ評価するようなもの)を使いたければ、 andalso や orelse を使いましょう。
等値性の確認も単純ですが、他の言語で見てきたシンボルとは多少違いがあります:
6> 5 =:= 5.
true
7> 1 =:= 0.
false
8> 1 =/= 0.
true
9> 5 =:= 5.0.
false
10> 5 == 5.0.
true
11> 5 /= 5.0.
false
まず、通常の言語では等値性の評価に == や != を使います。Erlangでは =:= や =/= を使います。 後半の3つの式(9行目から11行目)では、落とし穴を紹介してくれています。Erlangでは算術の場合は浮動小数も整数も関係ありませんでしたが、比較のときは関係あるのです。 しかし心配はご無用です。 == や /= といった演算子は浮動小数と整数の比較の時に使えます。 これはちゃんと等値性を確認したいのかどうか判断するときに重要です。
他の比較演算子は < (より小さい), > (より大きい), >= (以上), =< (以下)があります。 最後の演算子は(私が思うに)左右逆になっていて、私のコード内では多くの構文エラーの原因になっています。 =< に気をつけてください。
12> 1 < 2.
true
13> 1 < 1.
false
14> 1 >= 1.
true
15> 1 =< 1.
true
5 + llama や 5 == true のようなことをしたらどうなるでしょうか? 試してみるほかありません。そして、エラーメッセージで恐ろしくなりましょう!
12> 5 + llama.
** exception error: bad argument in an arithmetic expression
in operator +/2
called as 5 + llama
おおっと!Erlangは基本型を間違って使っていることがお好きじゃないようです! エミュレータは素敵なエラーメッセージを返してくれました。 Erlangは + 演算子の2つの引数のうち1つがお好みではないと言っています!
Erlangは間違った型を使ったら常にお怒りになるというわけでもありません:
13> 5 =:= true.
false
なぜある演算子では異なった型は使えなくて、別の演算子では使えるのでしょうか? Erlangではどんなものでもすべての型と足し算はできませんが、比較はできます。 これはErlangの作者達が現実に合うようにすると理論は後回しになる部分があると考えたのと、一般的なソートアルゴリズムでどんな項も並び替えられるようにするのがとてもいいことだと決めたからです。 これによって物事がとても単純になって、Erlangでコードを書く際に多くの箇所で単純化できるようになったのです。
ブール代数と比較をする際に心にとどめておかなければいけないことがもう1つだけだあります:
14> 0 == false.
false
15> 1 < false.
true
もしあなたが手続き型言語や他のオブジェクト指向言語をやっていた場合、これは起こり得ます。 14行目はtrueになって、15行目はfalseになるべきです!結局、falseは0を意味して、trueはそれ以外のすべてです! しかしErlangは違います。なぜなら私が嘘を付いたからです。 はい、嘘をつきました。ほんと恥を知るべきですよね。すいません。
Erlangにはtrueやfalseといったブールの値は存在しません。trueとfalseという項はアトムなのです。 しかしその2つは言語内に十分適用しているので、falseとtrueがいわゆる”false”と”true”という値以外であることを期待しなければ、特に問題になることはないでしょう。
Note
各項を比較するときには次の順で行われます:
number < atom < reference < fun < port < pid < tuple < list < bit string
ここに挙げた型すべてについてはまだ触れていませんが、この本を読めばだんだんわかります。 ただ、ここに挙げた順序があるからどんなもの同士でも比較できるということを覚えておいてください! Erlangの作者の一人であるJoe Armstrongの言葉を借りれば「実際の順序は重要ではないのです – すべての並び替え順序がよく定義されていることが重要なのです」
3.5. タプル¶
タプルはデータをまとめる方法の一つです。 タプルは項の数が分かっているときに多くの項をひとまとめにするのに使う方法です。 Erlangではタプルは {Element1, Element2, ..., ElementN} という形で書きます。 例として、デカルト座業系で点の位置を示すときには座標 (x,y) を使うでしょう。 この点を2つの項のタプルとして表現することができます:
1> X = 10, Y = 4.
4
2> Point = {X,Y}.
{10,4}
この場合、点は常に2つの項で表されます。点を表現するために変数XとYを使う代わりに、タプル1つだけ使えばよいのです。 しかし、点を受け取ってX座標だけ使いたい場合はどうしたらいいのでしょうか。その情報だけとりだすのは難しくありません。 値を与えたときのことを思い出してください。Erlangは同じ値を与えてもエラーは吐きませんでした。 これを利用しましょう! f() を使っていま定義した変数を消す必要があるでしょう。
3> Point = {4,5}.
{4,5}
4> {X,Y} = Point.
{4,5}
5> X.
4
6> {X,_} = Point.
{4,5}

これでXをタプルの最初の値を取り出すのに使えるようになりました!なにが起きたのでしょうか? まず、XとYには値が束縛されていませんでした。これを = 演算子の左手側でタプル {X,Y} の中にセットしたときに、 = 演算子は {X,Y} と {4,5} の両方の値を比較します。 Erlangは十分お利口なので、タプルから値を展開して、演算子の左手側で未束縛の変数に束縛します。 そうすると、比較はただの {4,5} = {4,5} となります。これは明らかに成功します! これは多くのパターンマッチングの形のうちの1つです。
6番目の式では、任意の _ 変数を使っていることに注目してください。 これはどのように使われるかの例です。この変数は使わずに捨ててしまう値がくる場所に置かれます。 _ 変数は常に未束縛と認識され、パターンマッチではワイルドカードのように振る舞います。 パターンマッチが要素の長さ(タプルの長さ)が同じ時にだけタプルを展開します。
7> {_,_} = {4,5}.
{4,5}
8> {_,_} = {4,5,6}.
** exception error: no match of right hand side value {4,5,6}
タプルは1つの値を操作する場合にも役立ちます。どうするかって? 最も簡単な例は温度です:
9> Temperature = 23.213.
23.213
うん、これはビーチに行くにはちょうどいい日みたいだね...ちょっと待って、これは絶対温度なの?摂氏なの?華氏なの?
10> PreciseTemperature = {celsius, 23.213}.
{celsius,23.213}
11> {kelvin, T} = PreciseTemperature.
** exception error: no match of right hand side value {celsius,23.213}
これはエラーを投げますが、まさに私たちが欲しかったものです! もう一度いいますが、これはパターンマッチが働いているのです。 = 演算子は {kelvin, T} と {celsius, 23.213} を比較したところで終わっています。たとえ、変数 T が未定義でも、Erlangは比較するときに celsius アトムは kelvin アトムと一致しないと判断します。 例外が投げられて、実行中のコードが停止します。こうすることによって、絶対温度を期待しているプログラムは華氏の温度を処理できなくなります。 これによってプログラマは何が送られたか分かりやすくなり、デバッグの際に助けになります。 アトムを1要素に含むタプルは「タグ付きタプル」と呼ばれます。タプルの要素はどのような型でも、他のタプルでも構いません:
12> {point, {X,Y}}.
{point,{4,5}}
もし1つ以上の座標をもち回したいときにはどうしたらいいでしょうか?
3.6. リスト!¶
リストは多くの関数型言語で米と味噌汁のような存在です。あらゆる種類の問題を解くために使われ、間違いなくErlangの中で最も使われるデータ構造です。 リストはどんなものでも保持できます!数字、アトム、タプル、他のリスト。1つの構造の中にあなたの大きな野心を入れておくことができるのです。 リストの基本的な書き方は [Element1, Element2, ..., ElementN] です。リストの中に複数のデータ型を入れることも可能です。
1> [1, 2, 3, {numbers,[4,5,6]}, 5.34, atom].
[1,2,3,{numbers,[4,5,6]},5.34,atom]
とっても簡単ですよね?
2> [97, 98, 99].
"abc"
なんてこったい!これがErlangの中でもっとも嫌いなことの一つです。文字列!文字列はリストで、書き方はまったく一緒なのです!なんでみんなこれを嫌がるかって?これのせいです:
3> [97,98,99,4,5,6].
[97,98,99,4,5,6]
4> [233].
"é"
Erlangはリストの中の数字の内、1つでも文字として表示できないものがあると、数字のリストとして数字を表示するのです! Erlangにはちゃんとした文字列は存在しないのです!これは間違いなく将来あなたを悩ませることとなり、Erlangを嫌いになる原因ともなるでしょう。 絶望しないでください。文字列を書くには他の方法があります。この章で後ほど触れます。
Don’t drink too much Kool-Aid:
これがErlangの文字列操作ではクソだと言われる所以です。よくある他の言語のように組み込みの文字列型がないのです。 こうなった理由はErlangはもともと電話会社で作られ、使われてきた言語だからです。 電話会社では全然(ほとんど)文字列が使われなかったので、文字列を追加しようという気にならなかったんでしょう。 しかし、Erlangで文字列処理が残念な状況になっている点は徐々に改善されてきました。 Erlang VMはいまやネイティブでUnicode文字列をサポートしていますし、常に文字列操作は早くなっています。
文字列をバイナリデータ構造で保存する方法もあります。この方法は非常に気軽に、速く慣れることができます。 全体としては、まだいくつかの関数は標準ライブラリにあいりませんが、文字列処理はErlangで確実にやっていけるくらいにはなっています。 文字列処理がしたかったらPerlやPythonなど、もっと良い言語はいくつかあります。
リストを結合するには、 ++ 演算子を使います。 ++ の反対は -- です。これは要素をリストから削除します:
5> [1,2,3] ++ [4,5].
[1,2,3,4,5]
6> [1,2,3,4,5] -- [1,2,3].
[4,5]
7> [2,4,2] -- [2,4].
[2]
8> [2,4,2] -- [2,4,2].
[]
++ と -- のどちらも右結合です。これはたくさんの -- 演算子や ++ 演算子の要素は右から左に実行されていくということを意味します。次がその例です:
9> [1,2,3] -- [1,2] -- [3].
[3]
10> [1,2,3] -- [1,2] -- [2].
[2,3]
続けてみましょう。リストの最初の要素はHeadと呼ばれ、残りの要素はTailと呼ばれます。 これらの要素を取得するには2つの組み込み関数(Built-in Funtion, BIF)があります。
11> hd([1,2,3,4]).
1
12> tl([1,2,3,4]).
[2,3,4]
Note
組み込み関数(BIF)はたいていErlangだけで実装できない関数もしくはErlangが実装され始めた時期のものです。(80年代はPrologでした)前者は大抵のものはCで定義されています。 Erlangで実装できるBIFもありますが、よく使う操作なので速度を上げるためにCで実装しています。 この一つの例は、 length(List) 関数です。これは(ご想像のとおり)引数として与えられたリストの長さを返します。
headにアクセスあるいは追加するのは速くて効率的です。実際、リストを扱うすべてのアプリケーションは常にまずheadを操作します。 とても頻繁に使われるので、パターンマッチを使ってリストにおいてheadをtailを切り離す良い方法があります: [Head|Tail] です。 次に、どのようにリストに新しいheadを追加するかの例を示します:
13> List = [2,3,4].
[2,3,4]
14> NewList = [1|List].
[1,2,3,4]
リストを操作するときには、ふつうheadからはじめたように、あとで操作するようにtailを素早く保存する方法も知りたいと思うでしょう。 タプルでどのようにパターンマッチを使って座標( {X,Y} )の値を取り出したかを覚えていれば、同様の方法でリストで最初の要素(head)と残りを取り出す方法がわかると思います。
15> [Head|Tail] = NewList.
[1,2,3,4]
16> Head.
1
17> Tail.
[2,3,4]
18> [NewHead|NewTail] = Tail.
[2,3,4]
19> NewHead.
2
ここで使った | はcons演算子(コンストラクタ)と呼ばれるものです。実際、どんなリストもconsと値だけでつくることが出来ます:
20> [1 | []].
[1]
21> [2 | [1 | []]].
[2,1]
22> [3 | [2 | [1 | []] ] ].
[3,2,1]
これより、どんなリストも次の形で作ることができます: [Term1| [Term2 | [... | [TermN]]]] したがってリストはheadとそれに続くtailで再帰的に定義することができます。このときtail自身もheadとそれに続く多くのheadで定義されているのです。 この意味でリストはちょっとミミズに似ていると考えられます。真ん中で切ると2匹のミミズになるのです。
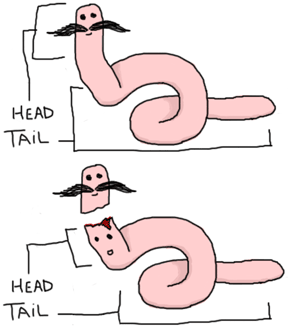
Erlangでのリストの作られ方は似たようなコンストラクタに馴染みがない人にとっては混乱の元です。 この考え方に慣れるには、これらの例を全部読みましょう。(ヒント:これらは全部等価です)
[a, b, c, d]
[a, b, c, d | []]
[a, b | [c, d]]
[a, b | [c | [d]]]
[a | [b | [c | [d]]]]
[a | [b | [c | [d | [] ]]]]
これが理解できたら、リスト内包を扱えるようになります。
Note
[1 | 2] の形は「間違ったリスト」と呼ばれています。間違ったリストは [Head|Tail] のパターンマッチのときは動作しますが、通常のErlangの関数で使おうとすると失敗します。( length() でもだめです) なぜなら、Erlangは適切なリストを想定しているからです。適切なリストは最後のセルが空のリストになっているリストです。 例えば [1|[2]] は動きます!間違ったリストは構文的には適切なのですが、ユーザ定義のデータ構造の外ではすごく制限されています。
3.7. リスト内包¶
リスト内包はリストを修正する方法です。リスト内包を使うと、プログラムが短くなりますし、他のリスト操作に比べると理解しやすくなります。 集合記法からアイデアをもらっています。数学の授業で集合論を習ったことがある、あるいは数学の表現を見たことがあれば、おそらくどうやって動作するかは分かるでしょう。 集合記法は基本的に集合の各要素が満たさなければいけない属性が書いてあって、どのように集合を作るか示してあります。 リスト内包は最初はとっつきにくいですが、努力するに値します。リスト内包はコードを綺麗で短くしてくれます。 なので、理解するまでどんどん例を試して書いてみてください!
集合記法の例はこれです: 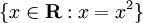 この集合記法では、その結果の集合はすべての実数に対して、それら自身の2乗と等しい数を集めたものになることを記述しています。結果は {0,1} です。他の集合記法の例としては、単純で省略された例です: {x : x > 0}
ここでは、 x > 0 なすべての数を表しています。
この集合記法では、その結果の集合はすべての実数に対して、それら自身の2乗と等しい数を集めたものになることを記述しています。結果は {0,1} です。他の集合記法の例としては、単純で省略された例です: {x : x > 0}
ここでは、 x > 0 なすべての数を表しています。
Erlangのリスト内包は集合空他の集合を生成することを意味しています。例えば {2n : n in L} という集合があったとします。このときLは [1,2,3,4] というリストです。Erlang実装では次のようになります:
1> [2*N || N <- [1,2,3,4]].
[2,4,6,8]
数学的記法とErlangの記法を比べると、大した違いはありません。波括弧({})がカギ括弧([])になったり、コロン(:)が2つのパイプ(||)になっています。また ‘in’ という単語は矢印(<-)に置き換わっています。 記号を置き換えただけで、論理は変わっていません。上の例では、 [1,2,3,4] の各値が順番にNにパターンマッチされます。 矢印はちょうど = 演算子のように動作します。ただここでは例外は投げません。
真偽値を返す演算子を使って、リスト内包表記に条件を追加することもできます。 1から10までの数の中からすべての偶数を取り出したいときは、次のように書けます:
2> [X || X <- [1,2,3,4,5,6,7,8,9,10], X rem 2 =:= 0].
[2,4,6,8,10]
ここで X rem 2 =:= 0 は数が偶数か確認しています。実際のアプリケーションではリストの各要素に関数を適用して、全部に条件に適合するかなどを確認しています。 例として、レストランを持っているとします。お客が入って、メニューを見て、税込(たとえば7%)で$3から$10の間に収まるような商品の価格をすべて見たいといった場合です。
3> RestaurantMenu = [{steak, 5.99}, {beer, 3.99}, {poutine, 3.50}, {kitten, 20.99}, {water, 0.00}].
[{steak,5.99},
{beer,3.99},
{poutine,3.5},
{kitten,20.99},
{water,0.0}]
4> [{Item, Price*1.07} || {Item, Price} <- RestaurantMenu, Price >= 3, Price =< 10].
[{steak,6.409300000000001},{beer,4.2693},{poutine,3.745}]
もちろん、小数は読みやすいように丸められてはいないですが、要点は得ていますよね。したがってErlangでのリスト内包を作る方法は NewList = [Expression || Pattern <- List, Condition1, Condition2, ... ConditionN] です。 Pattern <- List の部分は生成式と呼ばれます。条件式は1つ以上持てます!
5> [X+Y || X <- [1,2], Y <- [2,3]].
[3,4,4,5]
この例では演算 1+2, 1+3, 2+2, 2+3 がおこなれます。リスト内包を作りたい場合は一般的に書けば NewList = [Expression || GeneratorExp1, GeneratorExp2, ..., GeneratorExpN, Condition1, Condition2, ... ConditionN] となります。生成式はパターンマッチとひもづいてフィルタとして動作していることに注意してください。
6> Weather = [{toronto, rain}, {montreal, storms}, {london, fog},
6> {paris, sun}, {boston, fog}, {vancouver, snow}].
[{toronto,rain},
{montreal,storms},
{london,fog},
{paris,sun},
{boston,fog},
{vancouver,snow}]
7> FoggyPlaces = [X || {X, fog} <- Weather].
[london,boston]
もしリスト ‘Weather’ 内の要素が {X, fog} パターンに対応しなかった場合、それはリスト内包に単純に無視されるだけとなります。 = 演算子だったら例外を投げるような状況です。
さらにもう一つ基本的なデータ型が残っているので、今から見てましょう。それはバイナリデータを簡単に解釈することができる驚くべき機能です。
3.8. ビット構文!¶
大抵の言語では数字、アトム、タプル、リスト、レコードと/あるいは構造体などのデータを操作できるようになっています。 しかし大抵の言語ではバイナリデータに関しては非常にサポートが薄いです。 Erlangではバイナリをパターンマッチを使って扱う際にとても有用な抽象化をしてくれて、次のレベルに連れていってくれます。 この機能によって、生のバイナリデータを扱うのが楽しく、簡単になります。(実際は全然楽しくないです) この機能は電話会社のアプリケーションに必要だったのです。ビット操作は独特の構文やイディオムで、はじめは奇妙に見えるかもしれません。 しかし、ビットやバイトがどのように動作するか分かれば、とてもわかりやすいものでしょう。 そうでなければこの章の残りをスキップしたくなるでしょう
ビット構文はバイナリデータを << と >> で囲って、読みやすいセグメントにカンマで分けます。 セグメントはバイナリ列になっています。(必ずしもバイト区切りでなくてもよいですが、バイト区切りがデフォルトです) PhotoshopやWebのCSSスタイルシートで色を確認したことがあれば、16進数記法が #RRGGBB というようなフォーマットであることを知っていると思います。 オレンジの淡い色はこのフォーマットだと #F09A29 で、Erlangでは次のように書けます:
1> Color = 16#F09A29.
15768105
2> Pixel = <<Color:24>>.
<<240,154,41>>
これは基本的に「#F09A29というバイナリ値を1画素での24ビット(赤に8ビット、緑に8ビット、青にも8ビット)に配置してください」と言っています。 値はあとでファイルに書くこともできます。これは一度ファイルに書き込まれると、それをテキストエディタで開いたら全然読めない文字が並んでいることでしょう。 再度ファイルをErlangで読み込むと、Erlangはバイナリを解釈して、きれいな <<240,151,41>> の形式で表示してくれます!
さらに面白いのが、バイナリをパターンマッチで展開できる機能です:
3> Pixels = <<213,45,132,64,76,32,76,0,0,234,32,15>>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
4> <<Pix1,Pix2,Pix3,Pix4>> = Pixels.
** exception error: no match of right hand side value <<213,45,132,64,76,32,76,
0,0,234,32,15>>
5> <<Pix1:24, Pix2:24, Pix3:24, Pix4:24>> = Pixels.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
3番目のコマンドでは、4画素のRGBカラーをバイナリで宣言しています。 4番目のコマンドでは、バイナリ列から4つの値を展開しようとしています。これは4つ以上のセグメントがあるため例外を投げます。実際には12もセグメントがあるのです! なので、Erlangに左側のそれぞれの変数が24ビットのデータを保持することを伝えてやらなければいけません。 それが Var:24 が意味しているものです。これで最初の画素を取って、個々の色値に分けることが出来ます。
6> <<R:8, G:8, B:8>> = <<Pix1:24>>.
<<213,45,132>>
7> R.
213
「イェイ、これは素晴らしい。じゃあ最初から1色しか必要なかった場合はどうしたらいいんだい?いつも全部の値を展開する必要があるのかい?」 ハッ!全然必要ないさ!Erlangではこんな時のための構文糖衣とパターンマッチがあります:
8> <<R:8, Rest/binary>> = Pixels.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
9> R.
213
どうだい?最高だろ?これはErlangはバイナリセグメントを表現するのに複数の方法があるから出来るわけです。 次に挙げる例はすべて正しい構文です:
Value
Value:Size
Value/TypeSpecifierList
Value:Size/TypeSpecifierList
ここでSizeは常にビットで、TypeSpecifierListは次のどれかを表しています:
- 型
- 使える値 : integer | float | binary | bytes | bitstring | bits | utf8 | utf16 | utf32 これはバイナリデータが使われる種類を表しています。’bytes’は’binary’の短縮表現で、’bits’は’bitstring’の短縮表現であることに気をつけてください。型を何も指定していなければ、Erlangは’integer’と推定します。
- 符号付き
- 使える値 : signed | unsigned 型がintegerの時だけ関係します。デフォルトは’unsigned’です。
- エンディアン
- 使える値 : big | little | native エンディアンはinteger, utf16, utf32, floatの時にだけ関係します。 これはシステムがバイナリデータをどのように読み込むかに関係します。例として、BMPイメージのヘッダフォーマットは4バイトの整数値としてファイルサイズを保持しています。 サイズが72バイトのファイルは、リトルエンディアンのシステムでは <72,0,0,0>> で、ビッグエンディアンでは <0,0,0,72>> で表現します。 一方では ‘72’ と読み込む一方では ‘1207959552’ として読み込みます。なので正しいエンディアンを使っているか確認してください。 ‘native’というオプションもあって、これはランタイムにCPUがリトルエンディアンかビッグエンディアンのどちらを使っているか判断します。 デフォルトでは ‘big’ に設定されています。
- ユニット
- unit:Integer のように書きます。 これはビットで書いた各セグメントのサイズです。Integerは1から256の範囲で書くことが出来、デフォルトではintegerでは1に、floatsやbitstringでは8に設定されています。 utf8, utf16, utf32ではunitを必要としません。ユニットで操作されるSizeはセグメントが取るビット数で、8で割り切れる数でなければいけません。ユニットサイズは通常バイトアラインになっています。
TypeSpecifierList は属性を ‘-‘ で区切ることで出来ています。
いくつかの例を見れば定義を理解する助けになるかもしれません:
10> <<X1/unsigned>> = <<-44>>.
<<"Ô">>
11> X1.
212
12> <<X2/signed>> = <<-44>>.
<<"Ô">>
13> X2.
-44
14> <<X2/integer-signed-little>> = <<-44>>.
<<"Ô">>
15> X2.
-44
16> <<N:8/unit:1>> = <<72>>.
<<"H">>
17> N.
72
18> <<N/integer>> = <<72>>.
<<"H">>
19> <<Y:4/little-unit:8>> = <<72,0,0,0>>.
<<72,0,0,0>>
20> Y.
72
バイナリデータを読み込み、保存して、解釈するのに1つ以上の方法があるのが分かると思います。 これは少々混乱しやすいですが、それでも他の言語で提供されているツールに比べたらずっと簡素です。
標準のバイナリ演算(左右ビットシフト、バイナリの’and’, ‘or’, ‘xor’, ‘not’)もErlangに存在します。 関数 bsl (Bit Shift Left, 左ビットシフト), bsr (Bit Shift Right, 右ビットシフト), band, bor, bxor, bnot を使ってください。
2#00100 = 2#00010 bsl 1.
2#00001 = 2#00010 bsr 1.
2#10101 = 2#10001 bor 2#00101.
このような記法と一般的なビット構文を使えば、バイナリデータをパースしてパターンマッチするなんて造作も無いことです。 TCPセグメントをパースするコードはこんな感じに書けます:
<<SourcePort:16, DestinationPort:16,
AckNumber:32,
DataOffset:4, _Reserved:4, Flags:8, WindowSize:16,
CheckSum: 16, UrgentPointer:16,
Payload/binary>> = SomeBinary.
同様のことがどんなバイナリにも適用できます:ビデオエンコーディング、画像、他のプロトコル実装などなど。
Don’t drink too much Kool-Aid:
ErlangはC言語やC++に比べたら遅いです。我慢強い人じゃなかったら、ビデオや画像の変換にErlangを使うのは得策ではありません。たとえバイナリ構文が上に挙げたように面白そうでもだめです。Erlangは重いデータを数値処理するのには向いてないのです。
しかし、Erlangはそれでも多くの数値処理が必要ないアプリケーションでは結構速いのです。イベントに反応する、メッセージパッシングする(アトムを使うと相当軽いです)などです。 イベントをミリ秒単位で処理することができ、ソフトリアルタイムアプリケーションにはもってこいです。
バイナリ記法には他の側面もあります。ビット文字列です。バイナリ文字列はリストで表現する文字列と同様、言語に強く結びついていますが、ビット文字列は空間の観点からするとずっと効率的です。 なぜなら、通常リストは双方向リストになっているますが(1文字につき1ノード)、ビット文字列はC言語での配列のようなものです。 ビット文字列は次のような構文を使います: <<"this is a bit string!">> リストと比べて、ビット文字列の不利な点は、パターンマッチや操作する際に単純さが失われるという部分です。 結果として、ビット文字列はあまり操作されない文字列を保存するときか、空間効率が問題になるような時に使われます。 文字列とビット文字列については第9章で掘り下げます。さしあたって、これくらい知っておけば大丈夫です。
Note
たとえビット文字列が軽量だとしても、タグとして使うのは避けましょう。 文字列リテラルを {<<"temperature">>, 50} のように使ってしまうことがありえますが、こういうときはアトムを使いましょう。 この商の前の方で、アトムはどんなに長くても4バイトあるいは8バイトしか使わないと言いましたね。 アトムを使うことによって、関数から関数にデータをコピーするとき、あるいは他のサーバ上にある他のErlangノードにデータを転送するときにオーバーヘッドなく処理することができます。 逆に、軽いからといって文字列の代わりにアトムを使うのはやめましょう。文字列は操作できます(分割、正規表現など)が、アトムは比較しかできません。
3.9. バイナリ内包¶
バイナリ内包はリストに対してリスト内包があったものが、ビット構文にもあるということです。コードが短く簡潔になります。 バイナリ内包はErlangでは比較的新しいものです。以前のバージョンでも使うことはできましたが、それを実装したモジュールが必要で、さらに動作には特別なコンパイルフラグが必要でした。 R13B(この本で使われています)から標準になり、シェルも含めどこでも使えるようになりました:
1> [ X || <<X>> <= <<1,2,3,4,5>>, X rem 2 == 0].
[2,4]
通常のリスト内包との唯一の違いは <- が <= になり、リスト([])の代わりにバイナリ(<<>>)になりました。 この章の前の方で、たくさんの画素のバイナリ値があって、RGB値を取得するためにパターンマッチをそれぞれの画素に対して行う、という例がありました。 あれでもいいんですが、もっと大きなデータ構造の場合、可読性が下がって保守が大変になります。 ちょっとやってみれば、1行のバイナリ内包でことは済みそうです。そしてとても見やすくなりました:
2> Pixels = <<213,45,132,64,76,32,76,0,0,234,32,15>>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
3> RGB = [ {R,G,B} || <<R:8,G:8,B:8>> <= Pixels ].
[{213,45,132},{64,76,32},{76,0,0},{234,32,15}]
<- を <= に変えることで、バイナリストリームも生成器とすることが出来ました。 完全なバイナリ内包は基本的にバイナリデータをタプル内の整数値に変換します。他のバイナリ内包構文も存在して、全く逆のことができるようになっています:
4> << <<R:8, G:8, B:8>> || {R,G,B} <- RGB >>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
注意してください。結果として生成されるバイナリは生成器がバイナリを返す場合はきちんとサイズを明示してあげなければいけません:
5> << <<Bin>> || Bin <- [<<3,7,5,4,7>>] >>.
** exception error: bad argument
6> << <<Bin/binary>> || Bin <- [<<3,7,5,4,7>>] >>.
<<3,7,5,4,7>>
上記のルールが守られていれば、バイナリ内包をバイナリ生成器として使うこともできます:
7> << <<(X+1)/integer>> || <<X>> <= <<3,7,5,4,7>> >>.
<<4,8,6,5,8>>
Note
これを書いたときは、バイナリ内包についてはほとんどドキュメントがありませんでした。 なので、あまり多くは書かず、バイナリ内包とは何かを定義し、基本的な動作を理解するのに必要な分だけ書きました。 ビット構文全体についてもっと詳しく知りたい場合は その仕様書を読んでみてください 。